





本文基于mnist手写数字识别任务,建立全连接前馈神经网络,详细分析其中的前向传播和反向传播过程,并使用numpy实现,用于解决手写数字识别任务。
注意: 本文中利用numpy实现全连接神经网络没有涉及太多封装(后续考虑封装成Pytorch的接口形式),只保留最简单的前向反向过程。
利用神经网络解决问题的训练过程如下:
- 建立网络结构,初始化网络模型参数;
- 前向传播得到模型的预测分布,并用损失函数计算预测分布和真实分布之间的损失值
- 反向传播求解损失函数对模型参数的梯度
- 更新模型参数
- 不断重复2-4的步骤,直到模型的性能达到任务要求
注意: 为了与输入数据(batch_size, input_size)中每个样本是行向量的形式保持一致, 本文推导过程中使用的单个样本的向量均为行向量,如果使用列向量进行推导计算需要进行相应的变换。
1 准备数据
def load_data(path):
"""
Args:
path: mnist数据集路径
return:
training_data: tuple
training_data[0]: 输入数据, (num_samples, input_size) 即(50000, 784)
training_data[1]: 标签, (num_samples, ) 即(50000, )
"""
f = gzip.open(path)
training_data, val_data, test_data = pickle.load(f, encoding='bytes')
f.close()
return training_data, val_data, test_data数据集采用的是 mnist数据, 加载进来返回三部分: training_data, validation_data, test_data; 每部分是个tuple对象,包含两个numpy的ndarray:
- [0] 输入数据 (num_samples, input_features)
- [1] 标签 (num_samples, )
深度学习中训练和评估都是使用批处理数据,因此我们要对数据集进行batch化:
def load_batches(data, batch_size):
"""
对数据洗牌,并分成一个个batch
Args:
data: tuple, 训练集 or 验证集
data[0]: 输入数据, (num_samples, input_size)
data[1]: 标签, (num_samples, )
batch_size:
Return:
batches_x: list
batches_x[0]: (batch_size, input_size)
batches_y: list
batches_y[0]: (batch_size, )
"""
n = len(data[0])
# 对数据进行洗牌
shuffle_idx = random.sample(range(n), n)
X = data[0][shuffle_idx]
Y = data[1][shuffle_idx]
batches_x = [X[i: i+batch_size] for i in range(0, n, batch_size)]
batches_y = [Y[i: i+batch_size] for i in range(0, n, batch_size)]
return batches_x, batches_y2 网络架构
我们首先要定义网络的结构,并初始化网络的模型参数(这里使用了标准正态分布进行初始化,未来将会介绍其他提高网络性能的初始化方法和其他提高网络性能的方法),在这里我们定义一个 Network类:
class Network(object):
"""
fully-connected neural network
Attributions:
sizes: list, 每个元素是每层的神经元的个数, 包括输入输出层
num_layers: 神经网络的层数
weights: list, 每个元素是一层神经网络的权重
bias: list, 每个元素是一层神经网络的偏置
"""
def __init__(self, sizes):
self.sizes = sizes
self.num_layers = len(sizes)
self.weights = [np.random.randn(i, j) for i, j in zip(self.sizes[:-1], self.sizes[1:])]
self.bias = [np.random.randn(1, j) for j in self.sizes[1:]]注意:
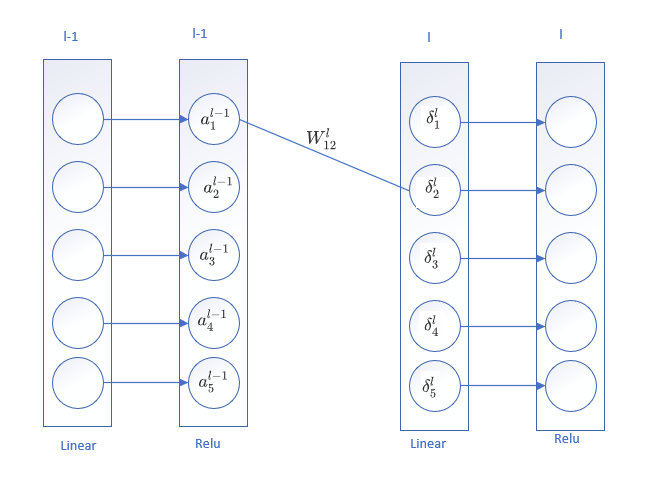
- 注意层与层之间网络权重的形状, 后面我们实现的是batch版本的训练过程,输入的数据形状是: (batch_size, input_size), 每个样本是行向量的形式,所以权重的形状是(权重输入神经元的个数, 权重输出神经元的个数), 例如部分网络如下图所示时:
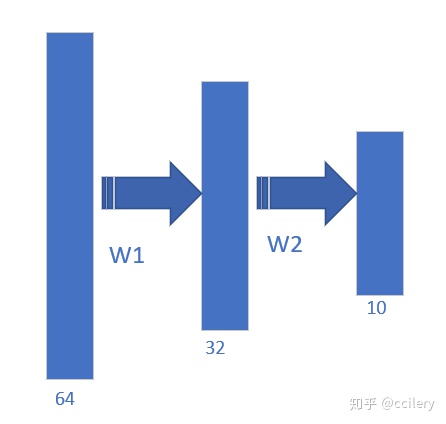
那么权重 W1的形状是(64, 32), W2的形状是(32, 10)。
- 注意权重向量对应的位置:
第l层的权重
定义好网络的结构后还有要考虑的就是激活函数的选择,在这里我们使用Relu作为隐藏层的激活函数,在输出层使用softmax+cross-entropy的组合.
3 前向传播
层与层之间的前向传播分为两部分: 线性变换+非线性激活。
在这里用
所以在这里我们的网络前向传播过程如下:
首先实现激活函数部分:
def relu(z):
"""
Args:
z: (batch_size, hidden_size)
"""
flag = (z <= 0) # 需要修改为0的部分
z[flag] = 0
return z
def softmax(logits):
"""
Args:
logits: (batch_size, output_size)
Returns:
(batch_size, output_size)
"""
max_row = np.max(z, axis=-1, keepdims=True) # 每一个样本的所有分数中的最大值
tmp = z - max_row
return np.exp(tmp) / np.sum(np.exp(tmp), axis=-1, keepdims=True)这里说一下softmax函数的实现:
公式
分母要对指数幂求和,容易超出最大限制,得到 nan,因此采取了一个技巧:将向量z 中的每个值减去向量z的最大值,然后再进行softmax运算,这样得到的结果是不变的:
线性变换的实现很容易, 就是矩阵乘积运算,这里只截取部分代码说明:
for weight, bias in zip(self.weights[:-1], self.bias[:-1]):
z = np.dot(a, weight) + bias
a = relu(z)交叉熵损失函数的实现没有单独写,而是将其与softmax组合在一起:
def softmax_cross_entropy(logits, y):
"""
Args:
logits: (batch_size, output_size), 网络的输出预测得分, 还没有进行 softmax概率化
y: (batch_size, ) 每个样本的真实label
return:
a: (batch_size, output_size)
loss: scalar
"""
n = logits.shape[0]
a = softmax(logits)
scores = a[range(n), y]
loss = -np.sum(np.log(scores)) / n
return a, loss注意传入的 y, 只包含每个样本的label.
进行推理预测时的前向传播实现:
def forward(self, x):
"""
x: (batch_size, input_size)
"""
a = x
for weight, bias in zip(self.weights[:-1], self.bias[:-1]):
z = np.dot(a, weight) + bias
a = relu(z)
# 处理输出层
# 在前向传播时不需要进行softmax概率化,反向传播时才会用到
logits = np.dot(a, self.weights[-1]) + self.bias[-1]
return logits注意:
前向传播过程有两种:
- 推理预测时的前向传播,此时不需要用到softmax, 只用logits就可以做出预测
- 训练时的前向传播,此时需要记录中间变量z和a, 并且需要进行softmax计算
训练时的前向传播过程在backward()中进行实现。
4 反向传播
反向传播是神经网络中的重点,它是一种快速高效 求解损失函数对模型参数的梯度的方法,也就是求解
介绍公式之前,先在这里引入一个记号:
我们看前向传播过程中的一个片段:
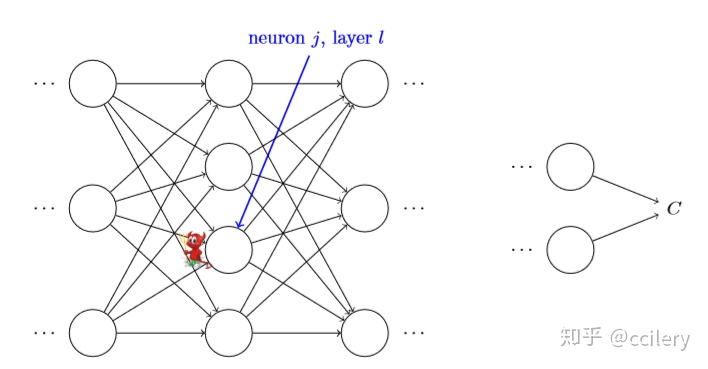
第l层的第j个神经元, 这个神经元的值为
所以
下面介绍反向传播过程的四个公式:
- 输出层的误差
- 误差反向传播(就是相邻两层误差之间的递推关系)
- 误差与模型权重的关系
- 误差与模型偏置的关系
下面我将详细介绍这四个公式,以及背后的直觉理解。
4.1 输出层误差
输出层的误差很容易计算,它取决于你选择的损失函数和输出层的激活函数, 关于softmax layer + cross-entropy的反向传播过程在这里不详细介绍了,可以参考之前写过的一篇文章(神经网络多分类中softmax+cross-entropy的前向传播和反向传播过程),过程有些麻烦,但结果很漂亮,也很容易实现:
def derivation_softmax_cross_entropy(logits, y):
"""
Args:
logits: (batch_size, output_size), 网络的输出预测得分, 还没有进行 softmax概率化
y: (batch_size, ) 每个样本的真实label
Return:
frac {partial C}{partial z^L}
(batch_size, output_size)
"""
n = logits.shape[0]
a = softmax(logits)
a[range(n), y] -= 1
return a上面实现的一个batch的输出层误差.
4.2 误差反向传播
这个公式反映的是两层误差之间的关系,其中
计算过程如下图所示:
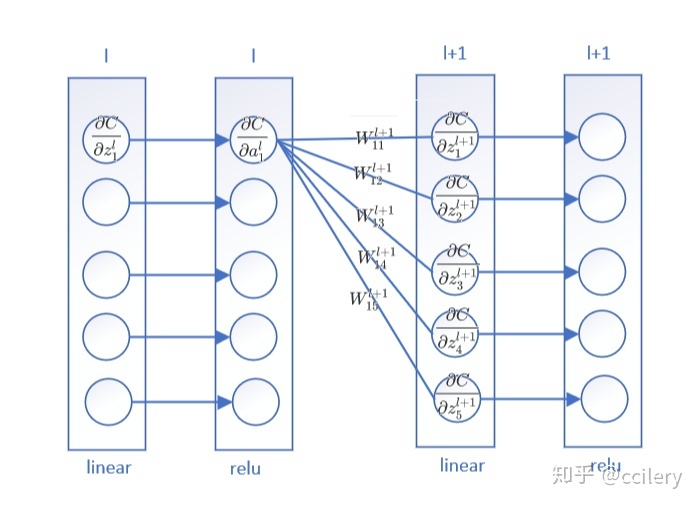
分为两个阶段:
- 将上一层的误差按照前向传播过程原路返回:
- 通过激活函数
具体实现(截取部分代码):
for i in range(2, self.num_layers):
dl = np.dot(dl, self.weights[-i+1].T) * derivation_relu(zs[-i])4.3 误差与模型权重的关系
看一个具体的例子:
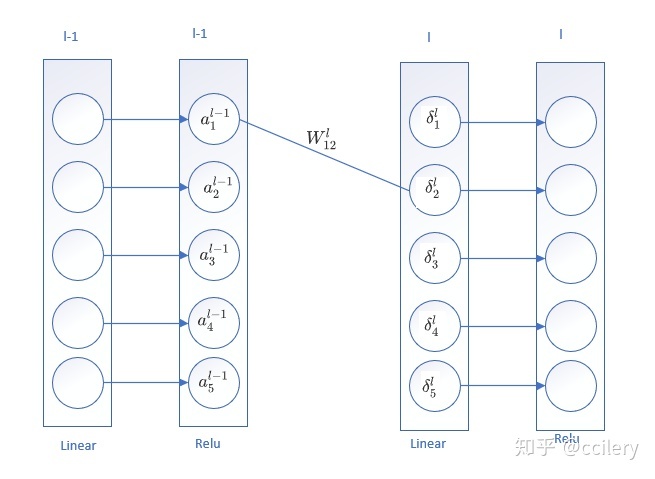
损失函数对某个权重的导数就是:该权重的激活输入 和 该权重输出神经元的误差的乘积.
权重的激活输入是在前向传播时计算各层的a, 权重输出神经元的误差是从输出层误差反向传播计算的。
4.4 误差与模型偏置的关系
具体实现:
for i in range(2, self.num_layers):
dl = np.dot(dl, self.weights[-i+1].T) * derivation_relu(zs[-i])
dws[-i] = np.dot(_as[-i-1].T, dl) / n
dbs[-i] = np.sum(dl, axis=0, keepdims=True) / n这里将每个样本求得的梯度求和作平均。
从上面我们可以看到,还需要求解激活函数的导数:
def derivation_relu(z):
flag = (z <= 0)
z[flag] = 0
z[~flag] = 1
return zsoftmax和corss-entropy的导数在输出层误差部分已经合起来一起求解了。
5 参数更新
采用mini-batch的随机梯度下降法进行参数更新:
loss, dws, dbs = self.backward(x, y)
self.weights = [weight - learning_rate * dw for weight, dw in zip(self.weights, dws)]
self.bias = [bias - learning_rate * db for bias, db in zip(self.bias, dbs)]尽管实现很粗糙,但效果还是很不错的
def main():
path = "data/mnist.pkl.gz"
training_data, validation_data, test_data = load_data(path)
model = Network([784, 30, 10])
model.train(training_data, validation_data, 1, 50, 100)按照以上设置,在验证集上的准确率可以达到 0.94 左右。
完整实现见 https://github.com/ccilery/nn-from-scratch
6 总结
本文介绍了全连接前馈神经网络中前向传播和反向传播过程,并用numpy实现,应用到mnist手写数字识别中。本文的实现比较粗暴,没有进行一定的抽象,未来计划实现CNN、RNN和LSTM后,参照Pytorch的接口进行一定的封装,变成一个小型的神经网络库。
参考:
- http://neuralnetworksanddeeplearning.com/chap1.html
- http://neuralnetworksanddeeplearning.com/chap2.html















 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









