






一想到做爬虫大家第一个想到的语言一定是python,毕竟python比方便,而且最近也非常的火爆,但是python有一个全局锁的概念新能有瓶颈,所以用java还是比较牛逼的,
webmagic 官网 https://webmagic.io/ 讲的非常详细,当然java比较优秀的框架还有很多不知这些
各类JAVA爬虫框架
Python中大的爬虫框架有scrapy(风格类似django),pyspider(国产python爬虫框架)。
除了Python,Java中也有许多爬虫框架。
nutch
apache下的开源爬虫程序,功能丰富,文档完整,有数据抓取解析以及存储的模块。
它的特点是规模大。
heritrix
比较成熟
地址:internetarchive/heritrix3 · GitHub很早就有了,经历过很多次更新,使用的人比较多,功能齐全,文档完整,网上的资料也多。有自己的web管理控制台,包含了一个HTTP 服务器。操作者可以通过选择Crawler命令来操作控制台。
crawler4j
UCI大学(加利福尼亚欧文分校)出品,简洁,古老,结构清晰
webmagic
国产,借鉴了scrapy,有pipeline,功能比较简单。Request也有meta属性,meta属性是一个字典,meta属性的value是Object类型
具体参考 https://www.cnblogs.com/weiyinfu/p/8099605.html
使用问题
下载maven依赖
us.codecraftwebmagic-core0.7.3
us.codecraftwebmagic-extension0.7.3注意这里0.7.3是maven目前最新版本但是有个问题没有修复,运行回报java.net.SSL异常,需要去webmagic官网下载最新源码然后自己构建webmagic-core这个包代替maven仓库的才会正常运行首页 去https://github.com/code4craft/webmagic 下载最新master源码
然后IDEA打开项目 会自动下载maven项目依赖如
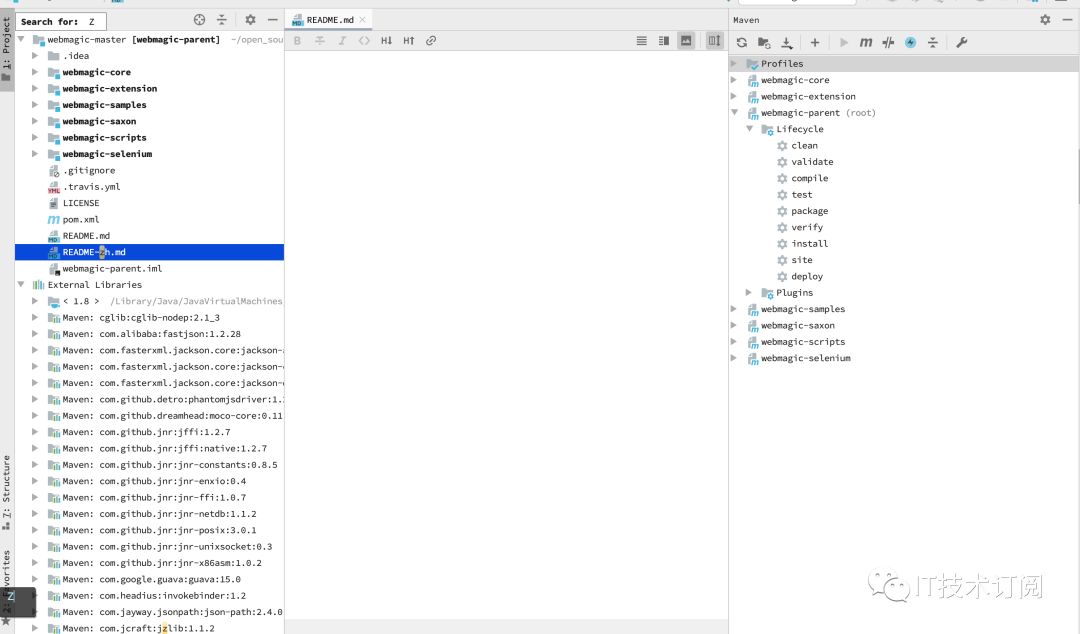
然后IDEA运行mvn install 构建每个模块找到webmagic-parent最开始的进行构建
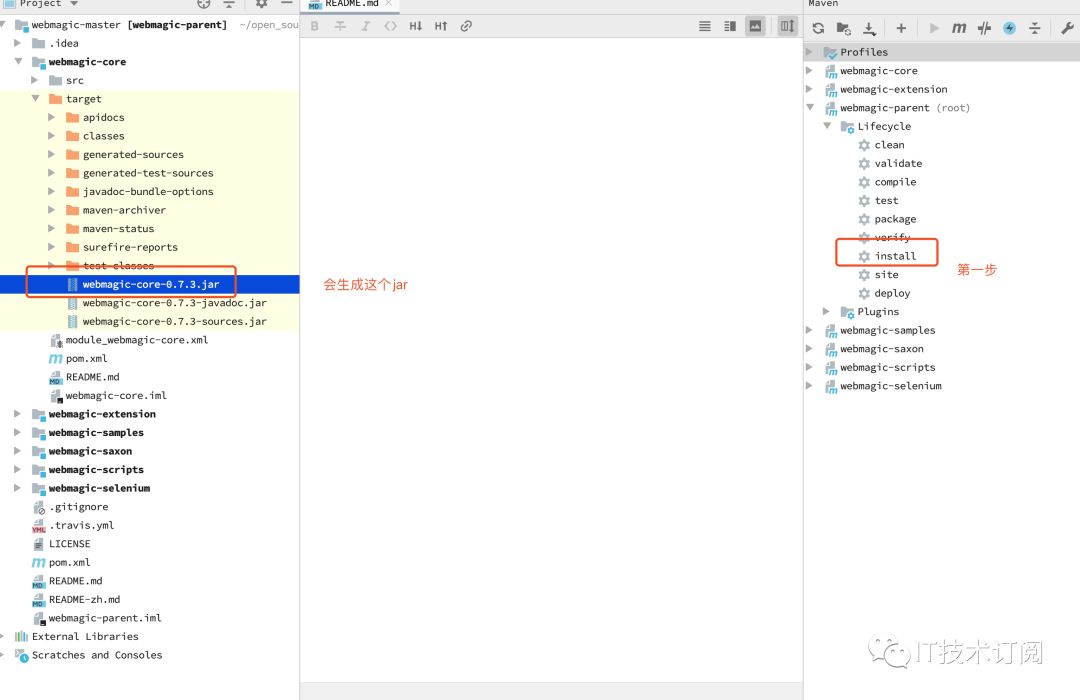
如上图如果构建成功会重新打包webmagic-core的jar,然后我们把这个jar安装到我们本地的maven仓库替换掉原来下载的webmagic-core-0.7.6.jar
通过maven以下命令安装本地
mvn install:install-file -Dfile=webmagic-core-0.7.3.jar -DgroupId=us.codecraft -DartifactId=webmagic-core -Dversion=0.7.3 -Dpackaging=jar其中-Dfile参数是你新构建的webmagic-core的jar包路径
最新版的webmagic0.7.3 使用了slfj+Log4j2日志你需要自己定义初始化log4j日志属性文件否则日志会报错
在maven项目resources目录新建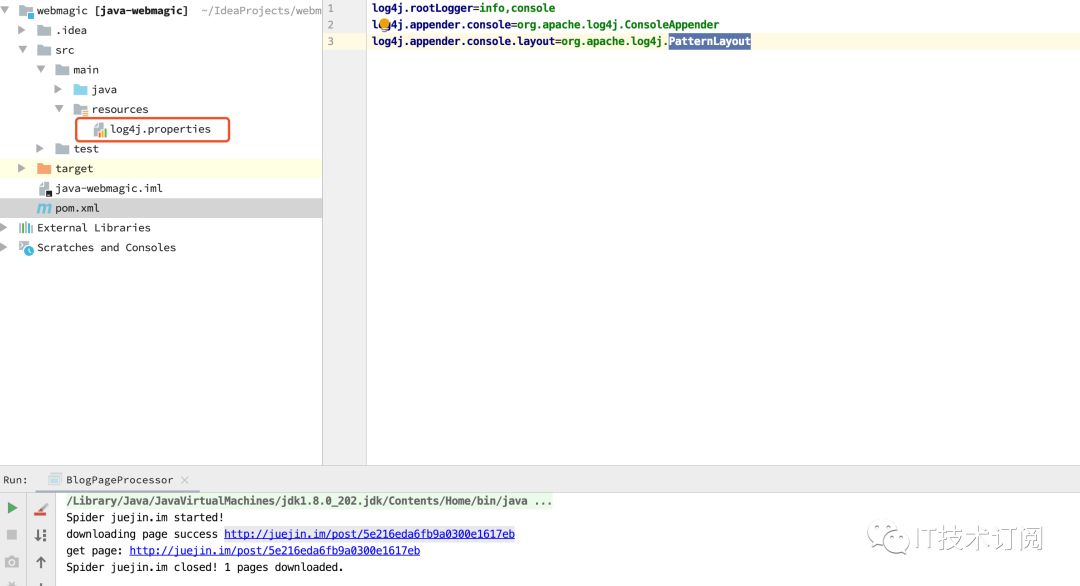
声明日志输出等级,位置,样式,才能正常运行
开始使用
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的设计参考了Scapy,但是实现方式更Java化一些。
而Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
WebMagic总体架构图如下:

我们只用写自己的PageProcessor实现PageProcessor接口就行
package com.kenx;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class BlogPageProcessor implements PageProcessor {
private Site site = Site.me();
@Override
public void process(Page page) {
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new BlogPageProcessor()).addUrl("http://juejin.im/post/5e216eda6fb9a0300e1617eb").run();
}
}
通过Spider入口运行自己写的PageProcessor就可以启动爬虫到这来就完美结束
详细官网文档 http://webmagic.io/docs/zh/posts/ch1-overview/architecture.html
















 2909
2909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









