






今天要讲的是今日头条web版的__ac_signature参数逆向
这次应该是最近刚更新的一个反爬,受朋友委托帮忙查看,跟上次的解决方式差不多,算法方面基本一致。先放上一篇文章的链接
具体如何找到加密算法以及断点调试等可以参考上一篇文章,我这边主要讲一下有哪些坑吧。
从上一篇的接口中我们可以拿到一些比如“https://www.toutiao.com/i6824014300391145991/”这样的详情页链接,当我们通过session去访问这些链接的时候 会发现并不是直接返回的原文内容 而是一串js代码 如下图

我这里把这个代码给贴下来了 有点js基础的同学应该可以很容易理解 这个实际上就是拿到cookie中的__ac_nonce字段 然后调用window.byted_acrawler.sign("",“cookie字段”)然后赋值给__ac_signature=拼接成新的cookie再刷新页面,大致就是这样的一个流程 那么这样的话就很简单了
我们首先拿到第一次页面返回的cookie里面的__ac_nonce字段
import requests
ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
headers = {
"User-Agent": ua,
}
s = requests.Session()
url = 'https://www.toutiao.com/i6824014300391145991/'
resp = s.get(url, headers=headers)
print(resp.text)
resp_cookie = resp.cookies.get_dict()
x = resp_cookie['__ac_nonce']
print(x)

然后把之前封装的接口稍微改一下 改为window.byted_acrawler.sign("",“cookie字段”)即可

然后再用python调用该方法即可,我这边比较喜欢用node封装接口的方式(因为方便调试且坑比较少),直接调用接口传递cookie第一个字段然后计算出第二个字段就行了。
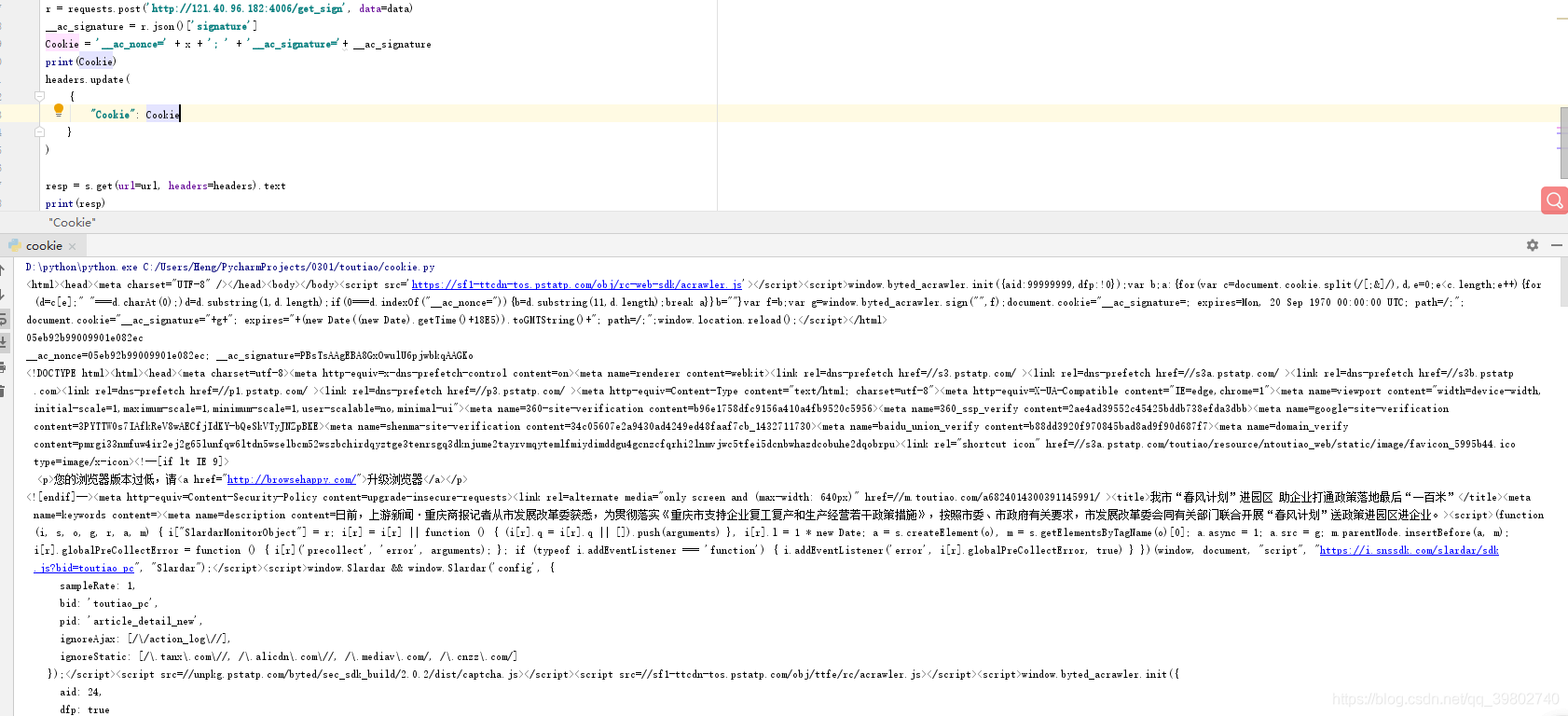
data = {
"cookie": x
}
r = requests.post('http://121.40.96.182:4006/get_sign', data=data)
__ac_signature = r.json()['signature']
Cookie = '__ac_nonce=' + x + '; ' + '__ac_signature='+ __ac_signature
print(Cookie)
headers.update(
{
"Cookie": Cookie
}
)
resp = s.get(url=url, headers=headers).text
print(resp)
在这里也给小伙伴们提供一个免费开放的接口:
http://121.40.96.182:4006/get_sign
Ending
持续更新ing (欢迎各种star与fork)
联系方式: 442891187(QQ)
如有权益问题可以发私信联系我删除
站长简介:前每日优鲜python全栈开发工程师,自媒体达人,逗比程序猿,钱少话少特宅,关注我,做朋友, 我们一起谈人生和理想吧!我的公众号:想吃麻辣香锅
关注公众号回复充值+你的账号,免费为您充值1000积分















 5362
5362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









