





使用工具:Fiddler+基础爬虫
官方网站:https://www.telerik.com/fiddler
Fiddler是一个抓包神器,用来检查电脑和互联网之间所有的通讯内容,而且比较简单容易上手,显示的格式也比较友好。
网页基本都会爬了,现在开始要想想如何去爬手机app里的内容了,爬取手机内容的方式也有很多,今填就介绍一个比较简单的组合,使用Fiddler+基础爬虫的形式来爬取,主要的案例就是来爬取知乎app内的热榜内容。
案例:使用fiddler+基础爬虫爬取知乎热榜
前言
首先简单的介绍一下一些网站以及一些手机app的原理,很多网站和手机app基本都是先把架子写好,然后往架子里填充数据,然而这些数据基本都是通过手机app或者网站向服务器发起请求,之后服务器返回json或者xml数据,然后网站或者手机app对数据进行解析到各个地方。之前我写过的一个微信小程序经纬我查查就是通过这种方式来操作的,通过小程序获取用户当前的地址,之后将地址传到服务器进行坐标转换再将结果传回解析到相应的位置。
1.设置Fiddler
先去官方网站下载一个fiddler,具体怎么下载就不说了,下边直接开始说关于如何设置的问题。

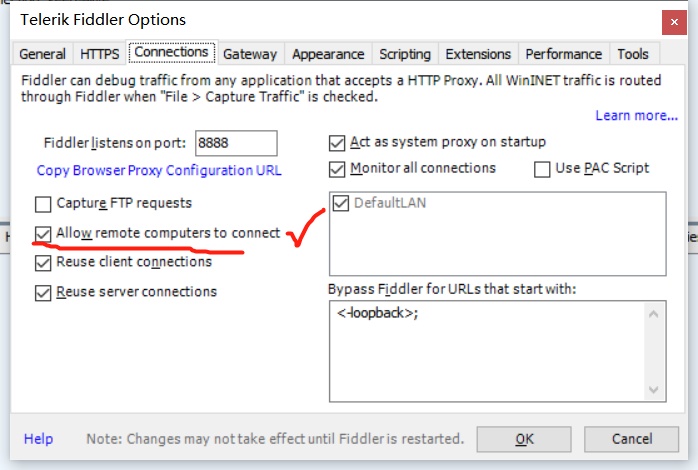
找到tools之后打开,选择connections,将图中标记的选项打对
之后再去HTTPS,将相应的内容打对,因为访问HTTPS网站需要下载专门的证书
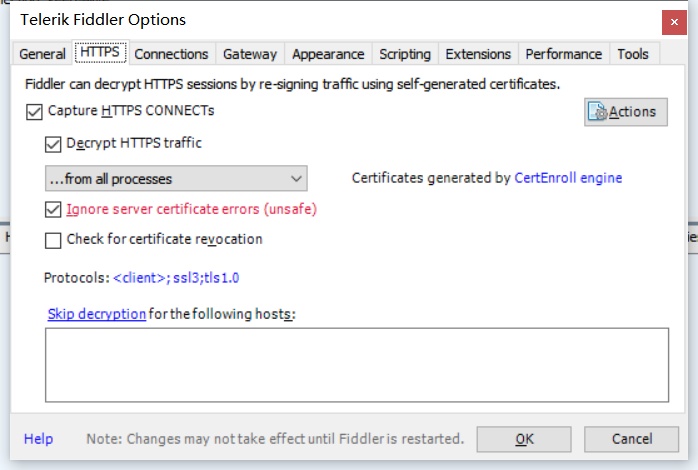
上的边操作完之后点击ok即可。
2.对手机进行设置
我拿了一个iphone举例子,android机的操作也是类似的,找到无线局域网点圈的位置,android是记入高级设置(要确保计算机和手机在同一局域网内)。
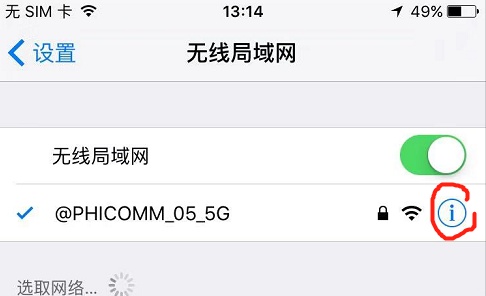
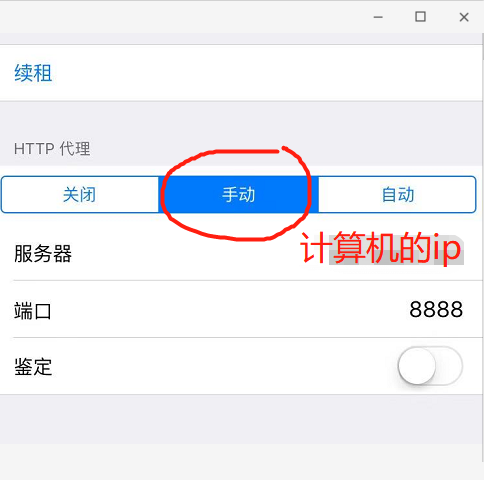
进入之后将HTTP代理调成手动,相应的位置输入相应的内容(电脑ip可以打开cmd输入ipconfig有一个ipv4就是计算机局域网内的ip)
之后用浏览器地址栏输入:电脑ip:8888,会到下列页面,点击圈内的内容即可。
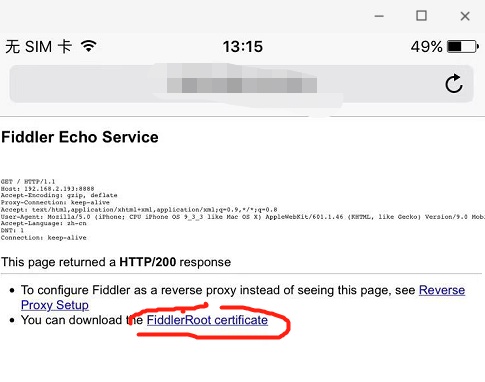
之后安装证书即可

安装完了之后重新连接一下wifi就可以在fiddler内进行抓包了。
3.抓包
打开fiddler之后,在手机上打开知乎app,之后在fiddler内会出现很多http连接
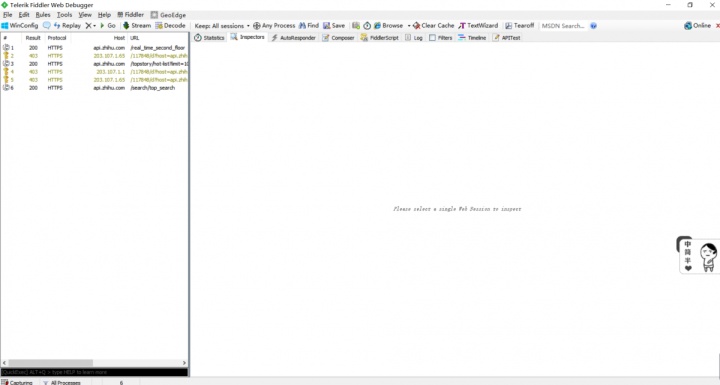
找前边标志位json的
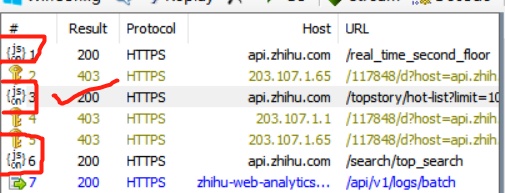
挨个找找,最后发现第二个里边有很多的东西,看起来密密麻麻挺麻烦的,一般会有两个框,第一个大框是request(你向服务器发出的请求,忽略即可),第二个大框是response(服务器返回的内容,有价值)看到里边基本都是/x0a之类的你就要立刻反应出这是unicode编码(详情可以百度)。
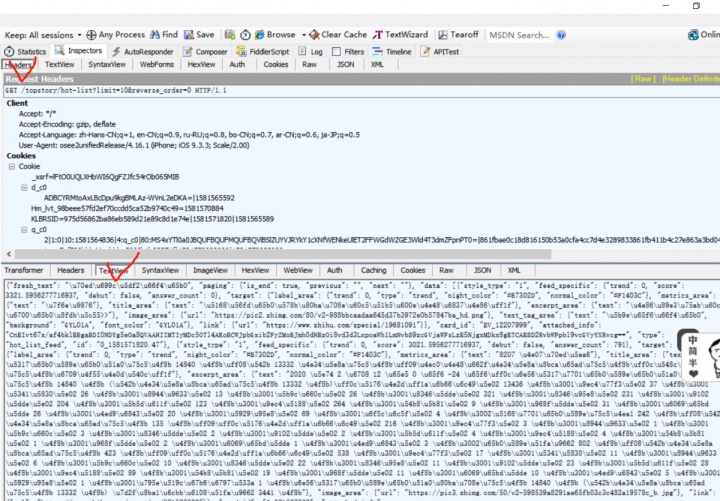
之后你复制一下文本,打开unicode转码,将这些代码复制进去猛然发现,这不就是我们要爬取的东西吗?
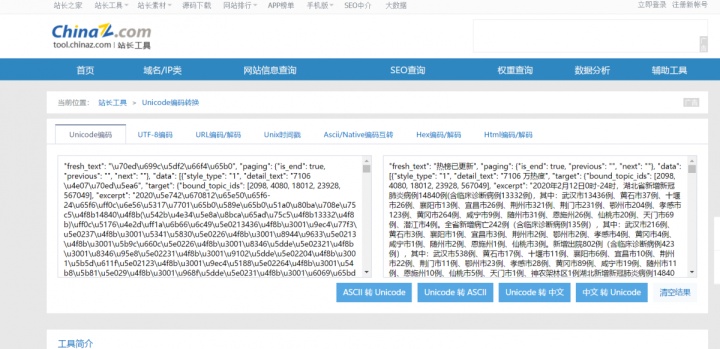
赶紧回到fiddler把这个api的网址复制下来,
GET https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0
200 OK (application/json)
掐头去尾就得到了api的网址
https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0
拿到网址之后赶紧放到浏览器里试一下看看有什么收获
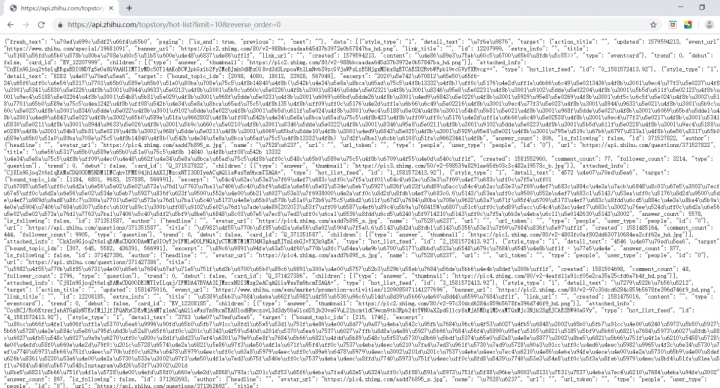
4.爬取
开始写爬虫

爬取结果
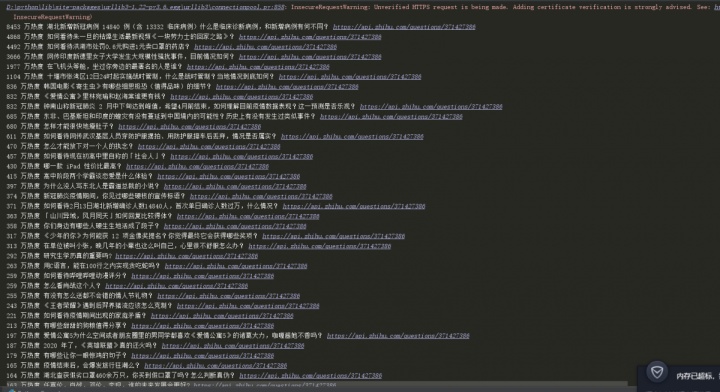
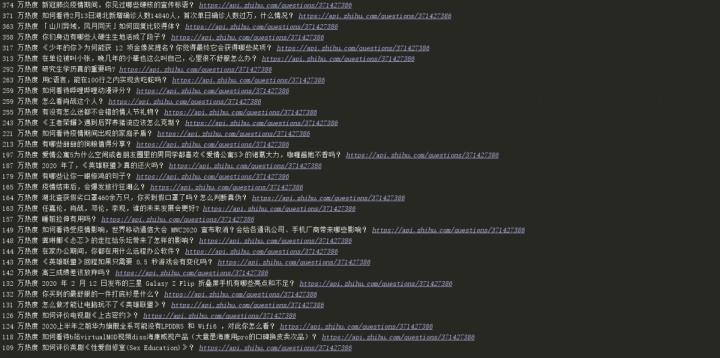
里边有一个警告是关于SSL证书,这个不用领会,是因为访问HTTPS协议网站的原因。
5.总结
这个案例拆分之后可以作为爬取知乎热榜练习,爬取手机app内的信息唯一的好处就是不需要去管什么反爬措施,如果直接通过web网页去爬这个热榜就涉及到登录等相关问题。本案例算是一个比较简单的爬取app内信息的实战。fiddler的作用非常大,在遇到反爬做的比较好的网站也可以使用fiddler进行分析各种传送的参数,在写爬虫的时候fiddler是一个非常实用的工具。
下面宣传一下自己的公众号:Bert的理想国,关于爬虫实战案例从 requests到selenium最后到scrapy框架以及scrapy-redis。
















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









