






 该文描述了一个使用Python进行网络爬虫,从IP138网站抓取电话号码信息,然后利用Flask框架创建Web服务,将数据呈现在HTML页面上的过程。开发环境包括VSCode,涉及的库有requests、lxml和Flask。
该文描述了一个使用Python进行网络爬虫,从IP138网站抓取电话号码信息,然后利用Flask框架创建Web服务,将数据呈现在HTML页面上的过程。开发环境包括VSCode,涉及的库有requests、lxml和Flask。
一. 开发环境
编译器:vscode
语言:python, html
二. 源代码(python, html)
-
文件夹架构
-
通过python,爬取电话号码信息并储存
-
通过html代码编写网页
三. Web显示
- 将信息通过Web网页显示
一. 略
二. 源代码(python, html)
-
文件夹架构
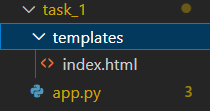
注意:templates 名字固定
-
python源代码(爬取电话号码后的信息,传入到html中)
# pip install flask 提供web服务的模块
# pip install requests 发送请求模块
# pip install lxml 解析数据模块
import requests
from lxml import etree
from flask import Flask, render_template, request
app = Flask(__name__) #创建一个可以支持web应用的对象
def get_mobile(phone):
# 发送请求的地址
url = f'https://www.ip138.com/mobile.asp?mobile={phone}&action=mobile'
# 伪装自己
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'}
# 发送请求
resp = requests.get(url, headers = headers)
#设置中文显示
resp.encoding = 'utf-8'
# 解析数据
e = etree.HTML(resp.text)
#编写Xpth提取数据
num = e.xpath('//tr/td[2]/a[1]/text()') #爬取tr/目录下,第二个td/目录中,第一个a/中的内容,输出为文本。(此处爬取的是电话号码)
datas = e.xpath('//tr/td[2]/span/text()') #爬取tr/目录下,第二个td/目录中,span中的内容,输出为文本。(此处爬取的都是电话号码背后的属地等信息)
datas = num + datas #列表拼接 将两个列表拼接,用于输出
# 解析响应
return datas
@app.route('/') #在网页不添加任何后缀的情况下,网页显示index.html代码中的网页
def index():
return render_template('index.html')
@app.route('/search_phone') #建立路由
def search_phone():
phone = request.args.get('phone')
data = get_mobile(phone)
return '<br/>'.join(data)
# get_mobile(15********5)
app.run(debug = True) #跑web服务-
html源代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=
, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form action="/search_phone" method="get">
手机号:<input type="text" name="phone" id="">
<input type="submit" value="查询">
</form>
</body>
</html>三. Web显示
-
将信息通过Web网页显示
-
运行代码
-
打开浏览器

-
输入电话号码

-
显示结果


















 2243
2243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









