





今天跟B站“奔跑的东兵卫”大佬的教程,学习了使用tf.clip_by_global_norm处理梯度爆炸(exploding gradient problem)的方法。
梯度爆炸是训练很深的神经网络时,随着层数的增加,导数会出现指数级的下降,则导致梯度消失。或者指数级的增加,导致梯度爆炸;本质是梯度传递的链式法则所导致的矩阵高次幂(反向传播会逐层对函数求偏导相乘)、深度学习-梯度爆炸和梯度消失_sisteryaya的博客-CSDN博客blog.csdn.net

在教程现有的三层网络处理MINST这个情况里很难出现梯度爆炸的现象,大佬费尽心思调整参数才有一点梯度很大的意思,然后用tf.clip_by_global_norm处理后梯度就变小了哈哈。只是为了体验一下这个解决方法啦。
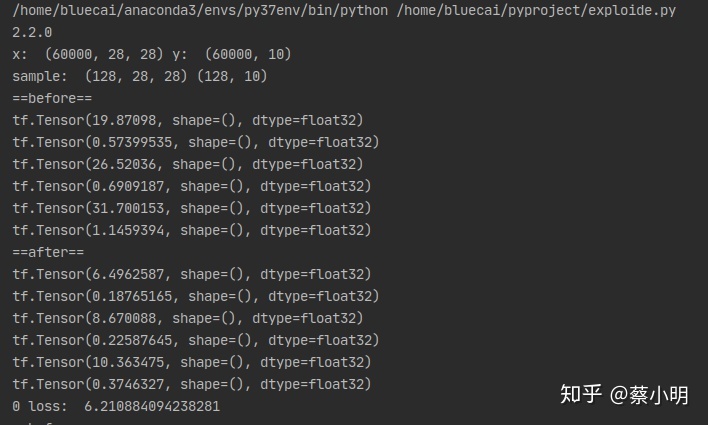
可以看到从before到after,六行对应w1, b1, w2, b2, w3, b3六个参数。
处理后,梯度降低了,这个方法我决定本质上就是单纯的限制梯度上限,减缓参数优化的速度(在梯度爆炸情况下就是爆炸的速度)。
我注意到另外一件事,就是W1,W2,W3之间的相对大小,随着迭代次数的增多,可以看到靠近输入层的w1变得比靠近输出层的w3要小很多,也就是前面的层逐渐减慢了优化的速度。这个问题在层次很深的模型中会变得很夸张,就是输入层附近的参数和初始值差不多,不怎么变化,也就是说这些不怎么变化的层次对模型来说是无用的。这其实就是梯度消失现象,如同开头提及的,这是由于求导过程迭代导致的。怎么解决我还不知道,之后遇到再细谈把。
下面放这次的代码
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
print(tf.__version__)
(x, y), _ = datasets.mnist.load_data()
x = tf.convert_to_tensor(x, dtype=tf.float32) / 50.
y = tf.convert_to_tensor(y)
y = tf.one_hot(y, depth=10)
print('x: ', x.shape, 'y: ', y.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y)).batch(128).repeat(30)
x,y = next(iter(train_db))
print('sample: ', x.shape, y.shape)
def main():
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
optimizer = optimizers.SGD(lr=0.01)
for step, (x,y) in enumerate(train_db):
x = tf.reshape(x,(-1, 784))
with tf.GradientTape() as tape:
h1 = tf.nn.relu(x @ w1 + b1)
h2 = tf.nn.relu(h1 @ w2 + b2)
out = h2 @ w3 +b3
loss = tf.square(y-out)
loss = tf.reduce_mean(loss, axis=1)
loss = tf.reduce_mean(loss)
#compute gradient
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
print('==before==')
for g in grads:
print(tf.norm(g))
grads, _ = tf.clip_by_global_norm(grads, 15)
print('==after==')
for g in grads:
print(tf.norm(g))
#update w' = w - lr*grad
optimizer.apply_gradients(zip(grads, [w1, b1, w2, b2, w3, b3]))
if step % 100 == 0:
print(step, 'loss: ', float(loss))
if __name__ == '__main__':
main()














 8427
8427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









