






分区表创建
在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition分区概念
分区表指的是在创建表的时候指定的partition的分区空间。一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。表和列名不区分大小写。分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示
使用方式:partitioned by (分区字段 字段类型)
注意:分区字段不能与表中字段重复
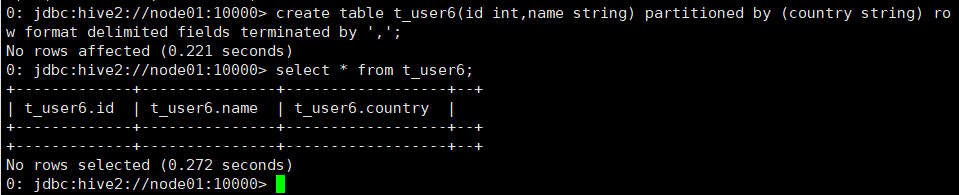
创建表
命令:create table t_user6(id int,name string) partitioned by (country string) row
format delimited fields terminated by ',';
创建映射文件
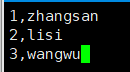
在HDFS上创建6.txt文件,在文件中编写id与name字段的数据
注意:分区字段数据不属于表中实际数据,所以不用添加
上传文件到HDFS中:hadoop fs -put 6.txt /hivedata
建立映射关系
分区表上传文件不能使用之前的方式直接上传,需要在客户端机器node02上使用load方式上传文件
命令:load data local inpath '/root/hivedata/6.txt' into table t_user6 partition(
country='china');

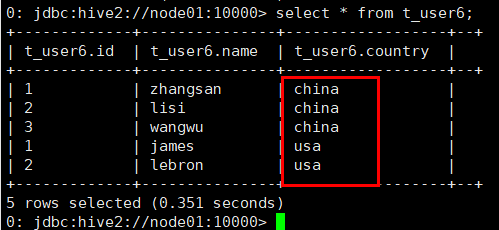
页面显示

分区字段作用
在7.txt中添加数据并利用分区形式建立与Hive的连接
命令:load data local inpath '/root/hivedata/7.txt' into table t_user6 partition(
country='usa');
此时查看表的时候,在表中字段的分区不同
页面显示

当需求为只查看china用户情况,那么HSQL可以按照如下形式编写
命令:select * from t_user6 where country='china';
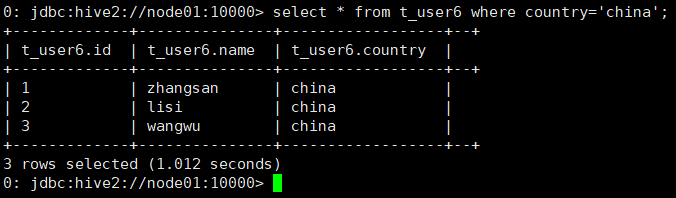
总结:分区表可以根据分区字段内容查看指定的数据内容
双分区表创建
需求:以天为单位,每小时导入一批数据
分析:此时就需要两分区,第一个分区指定日期,第二个分区指定时间
创建表
命令:create table t_user7(id int,name string) partitioned by (dt string,hour string) row format delimited fields terminated by ',';
建立映射关系
将6.txt文件中的信息映射到Hive中
命令:load data local inpath '/root/hivedata/6.txt' into table t_user7 partition(
dt='20200429',hour='14');

将7.txt文件中的信息映射到Hive中
命令:load data local inpath '/root/hivedata/7.txt' into table t_user7 partition(
dt='20200429',hour='15');

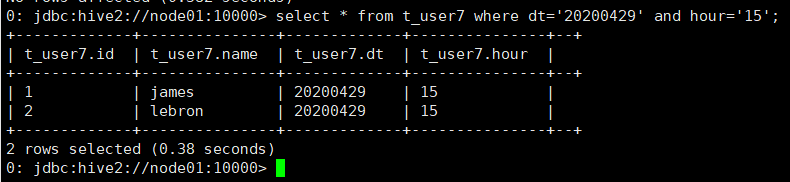
需求:查询表中时间为2020年4月29日下午3点中的数据
命令:select * from t_user7 where dt='20200429' and hour='15';
桶表创建以及数据导入
对于每一个表或者分区,Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
- 获得更高的查询处理效率。桶为表加上了额外的结构,Hive在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用Map端连接(Map-site join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大减少JOIN的数据量
- 使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
分桶表创建需要使用cluster by与into num buckets
- 开启分桶功能
查看分桶是否开启命令:set hive.enforce.bucketing;
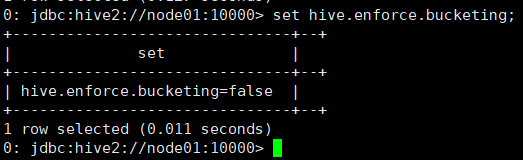
默认情况下不支持分桶功能
开启分桶命令:set hive.enforce.bucketing=true;
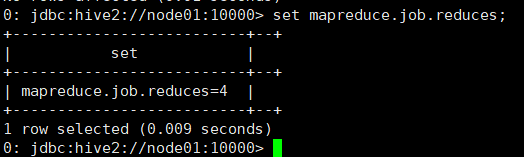
设置分桶个数命令:set mapreduce.job.reduces=4;
查看分桶个数命令:set mapreduce.job.reduces;
2、创建分桶表
create table stu_buck(sno int,sname string,sex string,sage int,sdept string)
clustered by(sno) //根据学生编号进行分桶,该字段必须是表中存在的字段
into 4 buckets //设置分桶个数
row format delimited fields terminated by ',';
命令:create table stu_buck(sno int,sname string,sex string,sage int,sdept string
) clustered by(sno) into 4 buckets row format delimited fields terminated by ',';
3、创建数据
在HDFS上新建一个文件8.txt,在文件中编写如下数据
0001,zhangsan,man,23,level1
0002,lisi,woman,30,level2
0003,wangwu,man,23,level1
0004,zhaoliu,man,25,level3
0005,songqing,woman,29,level5
0006,tangqiang,man,30,level4
0007,liangqiang,man,34,level2
0008,zhangying,woman,23,level1
0009,guojing,man,35,level4
0010,zhaoxia,woman,27,level3
0011,zongqing,woman,34,level5
0012,mayun,man,50,level10
- 针对分桶表数据的导入,load方式导入不能展现分桶效果,因为load的本质相当于Hive去执行hadoop fs -put命令,不是执行mapreduce
所以分桶表导入数据需要使用以下语句
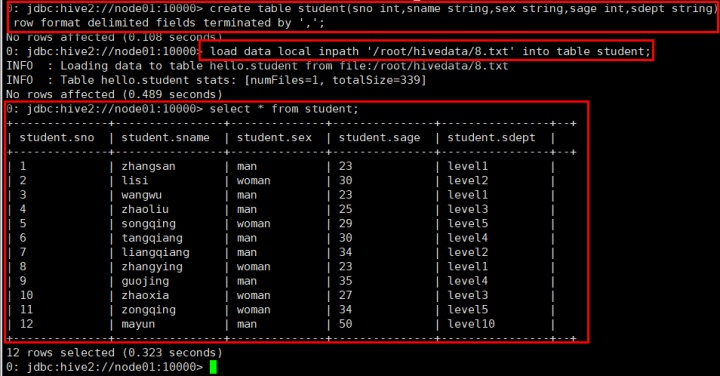
第一步:创建一张student表,将数据通过load形式加载到表中
命令:create table student(sno int,sname string,sex string,sage int,sdept string
) row format delimited fields terminated by ',';
加载数据命令:load data local inpath '/root/hivedata/8.txt' into table student;
第二步:实现分桶效果
查看分桶效果:select * from student cluster by(sno);
此时执行的是一个MapReduce程序
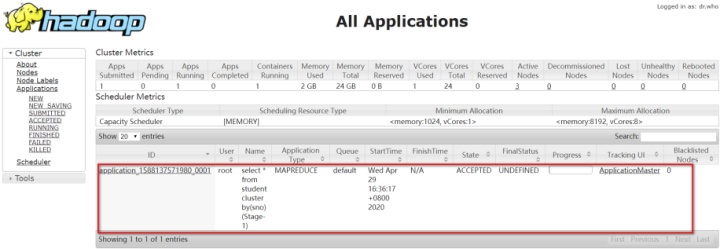
执行结果
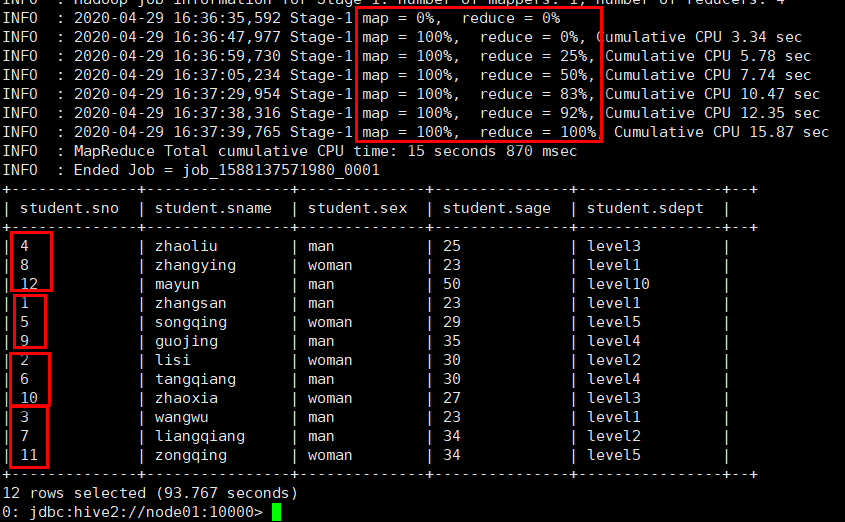
通过查看,发现数据被分成了四个部分
实现最终分桶效果
命令:insert overwrite table stu_buck select * from student cluster by(sno);
执行结果:此时数据被分成了四个模块
内部表与外部表
external关键字让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(location)
Hive创建内部表时,会将数据移动到数据仓库指向的路径。若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
- 创建映射文件
创建外部表的时候,不要将数据移动到HDFS的指定路径下,因为在创建表的时候可以通过location制定数据路径,所以映射文件可以在任意路径下
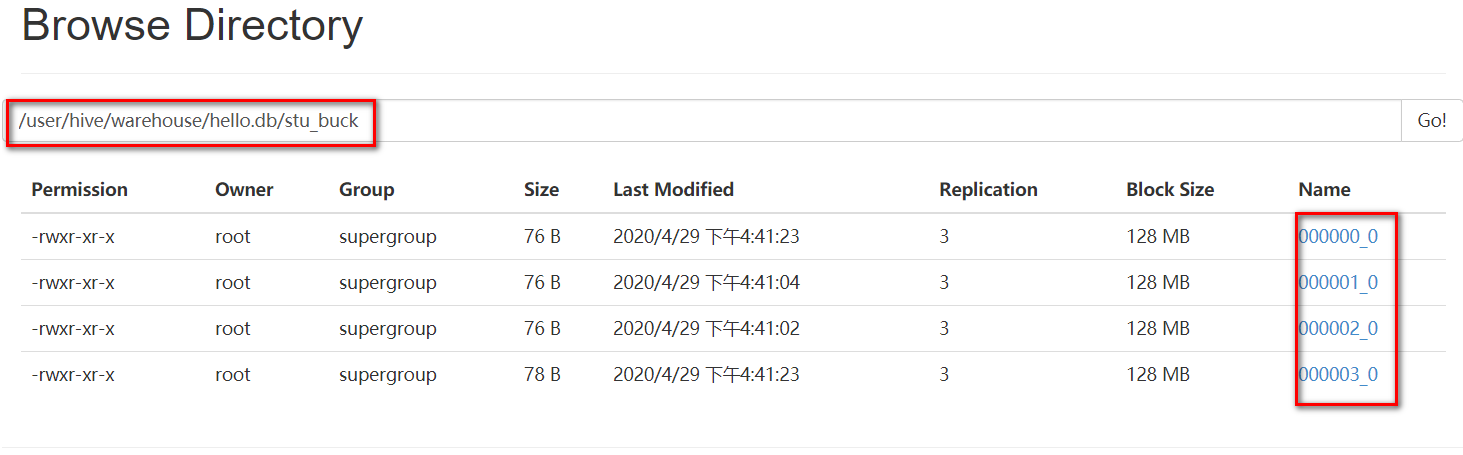
将8.txt文件上传到HDFS的/gw路径下
命令:hadoop fs -put 8.txt /gw

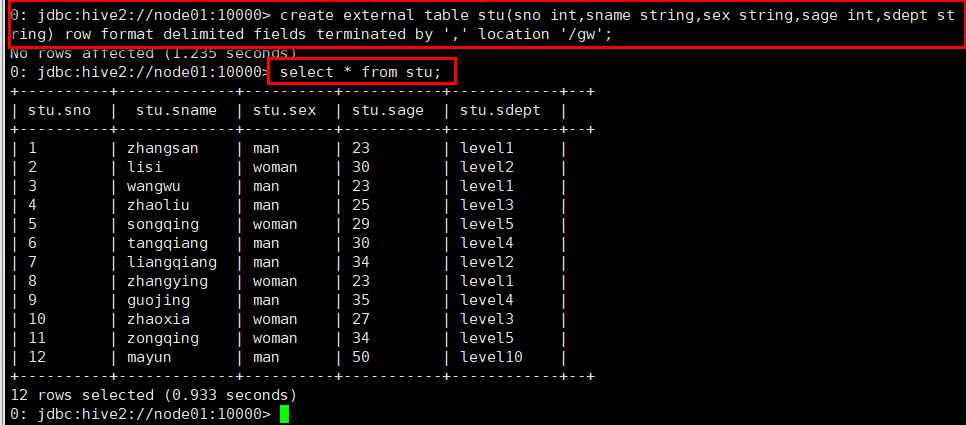
2、创建外部表
命令:create external table stu(sno int,sname string,sex string,sage int,sdept string) row format delimited fields terminated by ',' location '/gw';
此时查询stu表,发现数据已经映射到Hive中
Like允许用户复制现有的表结构,但是不复制数据
语法:create table table_name like existing_table_name
修改表操作


显示命令
显示当前数据库所有表
show tables;
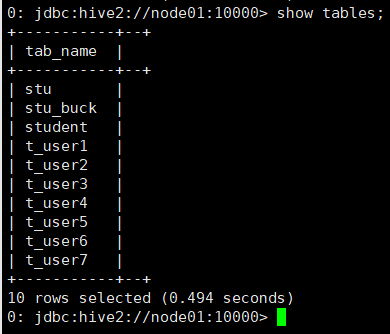
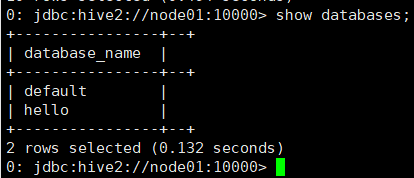
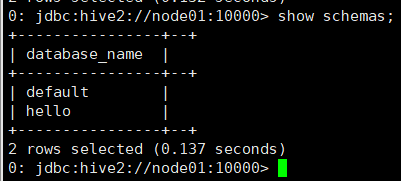
显示所有库
show databases | schemas;
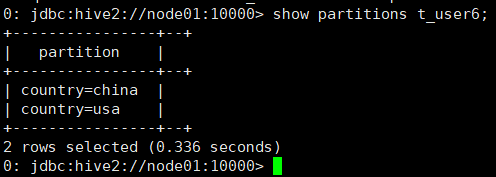
显示表分区信息,不是分区表执行报错
show partitions table_name;
显示当前版本Hive支持的所有方法
show functions;
查看表信息
desc extended table_name;
查看表信息(格式化、美观)
desc formatted table_name;
查看数据库相关信息
describe database database_name;















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









