






 本文介绍了CS231n课程中的图像语义分析任务,包括RNN和LSTM在Image Captioning中的应用,以及网络可视化、风格转移和GAN的相关内容。通过实例详细解析了RNN和LSTM的前向和反向传播过程,并展示了如何使用这些技术进行图像风格迁移和生成对抗网络的训练。
本文介绍了CS231n课程中的图像语义分析任务,包括RNN和LSTM在Image Captioning中的应用,以及网络可视化、风格转移和GAN的相关内容。通过实例详细解析了RNN和LSTM的前向和反向传播过程,并展示了如何使用这些技术进行图像风格迁移和生成对抗网络的训练。
Hello,大家好,这里是从不拖更的糖葫芦喵喵~!
ようこそ実力至上主义のCS231n教室へ
天気がいいから、いっしょに散歩しましょう。(划掉烦人的听力!)
考N1什么的才不会耽误更新!大家一定要保佑喵喵一次通过啊~
那么,最后一篇CS231n 2017 Spring Assignment3 就要开始了~!
喵喵的代码实现:Observerspy/CS231n,欢迎watch和star!
视频讲解CS231n Assignment3:
Assignment 3-AI慕课学院www.mooc.ai
Part 1 Image Captioning with Vanilla RNNs
下面让我们来和普通RNN一起玩耍,并完成一个简单的看图说话(图像语义分析)的任务吧!
1.1 Vanilla RNN
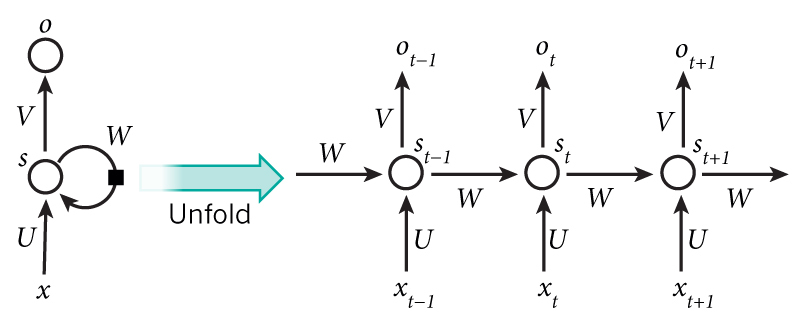
1.1.1 RNN单元
首先我们来看对于一个RNN单元:
前向:
向右的箭头:也就是
向上的箭头:输出层,是一个softmax:
反向:
反向我们需要计算dWx,dWh,db,dx和dh,不管计算哪一个,都要先把
剩下的就是一个线性的式子,分别对我们要的5个参数求导:
db = sum(dtheta)
dWx = dtheta dot x (是矩阵乘哦,然后还有注意形状!这里喵喵给出的不是实际式子,应该谁和谁相乘请按照形状自己想一想~)
dWh = dtheta dot h
dx = dtheta dot Wx
dh = dtheta dot Wh
1.1.2 完整RNN
每个单元都是一样的,那么,对于完整的RNN:
前向:
也就是要对RNN单元循环T次,T是序列的长度。
返回来看RNN单元前向公式,每次输入5个参数,输出一个
反向:
RNN反向和之前我们计算的反向都不太一样,因为之前我们计算反向时上游传回来的值只有dout一个。在RNN示例图中,反向时所有箭头都要翻转,也就是说,不仅有从右边来的dprev_h,还有从上面来的dh。
既然有两个那么加起来就好了。
首先我们逆序循环:
for t in range(T-1, -1, -1):对于每一个时间片t,上面来的导数是dh[:, t, :](形状是(N, T, H)),右边来的暂时记作dprev_h。对于最后一个单元,它的右边没有传来导数,所以初始化dprev_h是0。
于是对于每一个RNN单元,需要传进去的导数就是dh[:, t, :]+dprev_h。显然dprev_h是需要更新的。
注意到我们在实现RNN单元的反向传播时还需要有一个参数cache,所以还需要构造cache,这时候需要注意其中有些元素的下标。
参数计算完毕,利用刚才实现的反向传播就可以计算出5个导数了。
但是还没有完!
对于dx,我们可以计算它每一个时刻的导数,那么剩下dWx,dWh,db和dh呢?注意到
其实RNN中,这四个参数在不同时刻是共享的,因此需要在每一个时刻把它们都加起来做更新。
RNN我们做完啦!下面让我们来看看这个看图说话(图像语义分析)任务是什么样!
1.2 Image Captioning
简单说就是看图说话,给你一幅图,给出关于这幅图的说明文字。网络结构如下图所示:

1. 隐藏层
输入一幅图片,从训练好的vgg16的fc7层中取出特征,当做h0输入到RNN中。这样剩下的任务就是训练网络,使之能够输出图片说明句子(单词序列)。然后h还要经过一次线性变换。
如何表示单词呢?做过自然语言处理想必一定知道必不可少的操作就是Word embedding。其实就是把onehot编码的单词映射为一个向量,这个映射你可以自己从头训练,也可以用现成的比如word2vec,glove等继续训练,这里不再赘述。那么我们来看Word embedding的具体操作:
1.2.1 Word embedding
前向:
就是从映射矩阵里取出你要的单词对应的vec,直接取就好了。
反向:
反向只是选出dout中对应x的值就行了,注意各部分的形状,np.add.at()可以实现这一操作:
dW = np.zeros(W.shape) #dW.shape: (V, D)
np.add.at(dW, x, dout) #x,shape(N, T) dout.shape: (N, T, D)这样,对于RNN而言通过上面的两个步骤,两个输入(隐藏层的h0和embedding的单词)都准备好了,就可以进行训练了!
1.2.2 网络结构:
图片特征 -> FC -> h0
单词 -> embedding -> input
(h0, input) -> RNN -> Output
Output -> 时序FC -> 时序softmax-> Loss
注意最后的loss是时序FC和时序softmax,具体可以看给出的实现(其实没有太大的差别,就是形状不一样:原来是输入是(N, D)现在是(N, T, D),要来回reshape(N*T, D))。
前向和反向过程按照上述结构组合模块就可以了!
注意训练时候输入是captions[:, :-1],label是captions[:, 1:],也就是用下一个词当做当前词的label。captions的第一个词是start标记,最后一个词是end标记。
测试的时候稍有不同,我们需要构造一个输入,它的第一个单词是start标记。和训练时不同的是,测试时我们不知道T的大小,因此限定了最大输出长度,需要在循环里用RNN前向单元来进行预测:
for t in range(1,max_length):
word_embedding_forward()
rnn_step_forward()
affine_forward()
captions[:,t] = np.argmax()这样所有的结构都完成了,快去进行愉快的训练和测试吧!看看结果是不是很有趣?
Part 2 Image Captioning with LSTMs
RNN对长一点的序列有难以训练的缺点,那么我们就用LSTM替换它!
整个Image Captioning结构就不在重复说了,这里着重说明一下LSTM。
2.1 LSTM单元

前向:
解释一下这个图
从左向右传递的两个:上面是
从下向上计算的分别是:
注意到我们有三个输入c、h和x,同时Wx、Wh和b都分别有四个,实际上代码中将四个Wx、Wh和b链接在了一起,因此f、i、g、o的线性部分可以通过以一次计算完成:
z = x.dot(Wx) + prev_h.dot(Wh) + bz就变成了(N, 4H)的形状,取出对应的部分计算c、h即可。
反向:
反向要求dWx,dWh,db,dx,dprev_h和dprev_c。
和RNN不同,这次反向传回来的值有两个,分别是dnext_h和dnext_c。
回到图中分析,将所有箭头反过来发现
o只受到dnext_h影响,而i,f,g都是收到dnext_c与dnext_h通过tanh传回上面的值(记作dh2c)的和影响。
式子比较多,我们先不管那四个一样的线性部分(把它们记作i,f,o,g)
针对
首先求do(o是sigmoid求出来的,复习一下sigmoid的导数:sigmoid * (1 - sigmoid))
do = dnext_h * tanh(c) * o * (1 - o)
然后求dnext_h通过tanh传回上面的值(dh2c):
dh2c = dnext_h * o * (1 - tanh(c)**2)
这个值和dnext_c在
针对
di = (dnext_h + dh2c) * g * i * (1 - i)
df = (dnext_h + dh2c) * prev_c * f * (1 - f)
dg = (dnext_h + dh2c) * i * (1 - g**2)
dprev_c = (dnext_h + dh2c) * f
然后把di,df,do和dg用np.hstack链接在一起(记作d)就得到了线性部分的导数。
剩下的线性部分导数就很简单了
dx = d dot Wx
dWx = d dot x
dWh = d dot prev_h
dprev_h = d dot Wh
db = sum(d)
注意对应形状,大功告成!
2.2 完整LSTM
LSTM单元完成了,剩下的LSTM模块其实和RNN差不多啦
前向:
比RNN多了一个c,初始为0,记得循环里要更新它。
反向:
也是多了一个c,初始为0,循环里要更新它。注意代码中cache的构造方式和RNN不同。
好了,现在你可以把LSTM加入到Image Captioning中的网络结构里去了!看看效果吧!
Part 3 Network Visualization: Saliency maps, Class Visualization, and Fooling Images
复杂的公式和求导再也没有了,从这里开始都是有趣的例子,让我们一起看看吧!
3.1 Saliency maps
显著图,也就是要看看我们训练好的网络在进行图片分类时关注的是图片的那些地方(像素点)。
和之前不同的是,以前我们的梯度都是针对参数进行计算的,现在我们要利用正确分类的score去计算输入图片的梯度。然后取梯度的绝对值,在3个通道上选择最大的那个值。
这里注意求梯度的函数tf.gradients()返回的是一个list,我们只要取tf.gradients()[0]的值就行了。
然后运行可视化出来,是不是很有趣的结果?

3.2 Fooling Images
调整我们的图片,使它骗过我们训练好的网络,也就是用目标分类对输入图片的梯度来迭代更新输入图片。
首先计算目标分类对于当前输入图片的梯度,注意这里label要用tf.one_hot转换成onehot编码形式:
loss = tf.nn.softmax_cross_entropy_with_logits(labels=tf.one_hot(target_y, 1000), logits=model.classifier)
g = tf.gradients(loss, model.image)[0]然后按照要求计算normalize的梯度,并梯度上升更新输入:
X_fooling = model.image - dX一般在100轮迭代内即可完成,所以要写一个循环,循环里面计算:
X = sess.run(X_fooling, feed_dict={model.image: X})注意这行代码实际上是在不断更新X(也就是一开始我们的输入)。
当然你可以不用等100轮迭代完成,用下面的模块做一个判断然后break就行啦。
scores = sess.run(model.classifier, {model.image: X})
if scores[0].argmax() == target_y:
print(i," ",class_names[scores[0].argmax()])
break然后跑起来吧,得到的结果如下图,看起来一样,但是你的网络已经认为它不一样了!

3.3 Class Visualization
类别可视化,和显著图类似,不过这次我们要看的是训练好的网络关注的每个类别图片是什么样子。基本和上一个任务一样,只不过这次我们在随机噪声图片上更新目标分类的梯度。
注意根据要求这次loss要减去一个l2正则项。
循环里依旧更新X,最终跑出来的结果:

竟然是蜘蛛!(逃...
Part 4 Style Transfer
风格迁移,顾名思义,就是把一幅图片的风格转移到另一幅图片上,效果如下:

网络结构是这样子的:

简单说就是定义一个新的loss,然后对随机噪声图片进行梯度更新。注意三个图片是经过同样的训练好的网络的。
4.1 loss
为了达到这个效果,首先我们要考虑loss。新的loss由三项构成:content loss、style loss和total variation loss。
4.1.1 content loss
内容loss反映了生成的图片内容和源内容图片的差异,很简单,用feature map度量:
其中
4.1.2 style loss
风格loss目的就是为了衡量生成的图片风格和源风格图片的差异。而风格是用feature map的协方差矩阵度量的,所以新定义了一个Gram matrix:
实际上协方差矩阵反应了feature map值之间的关联性,通过相乘,使得原来大的值更大,原来小的值更小,也就是要突出自己的feature map的特点。
和内容loss一样,风格差异定义如下:
其中
4.1.3 total variation loss
这一项正则可以使生成图片更平滑:
其中
pixel_dif1 = img[:, 1:, :W-1, :] - img[:, :H-1, :W-1, :]
pixel_dif2 = img[:, :H-1, 1:, :] - img[:, :H-1, :W-1, :]实际上tf里提供了绝对值版本的total variation loss:tf.image.total_variation()。也就是不算平方,只用绝对值。
至此,三个loss计算完毕,加在一起就好了。
代码跑起来就可以看到上面的效果了,是不是很有趣?
这里有很多可以调的参数,loss的三个权重,内容loss和风格loss的层选择等等,这些参数对于结果有很大影响。
特别的,当风格loss权重为0时,是对源内容图像的重建,当然你也可以试试内容loss权重为0的情况。
另外,和这个需要不断迭代的风格迁移不同,有更快的fast style transfer方法去进行迁移,详见博客:谈谈图像的Style Transfer(一),谈谈图像的style transfer(二)。
Part 5 Generative Adversarial Networks(GAN)
终于到了我们作业的最后阶段啦!
生成对抗网络可以说是近年最火的一个研究方向,它生成的图片质量之高让人惊叹。那么就让我们来看看它的结构吧!
GAN其实就是生成器和判别器之间的博弈,一方面判别器从真实数据和生成数据中不断学习提高自己的判别能力,另一方面生成器不断迭代以提高自己的欺骗能力。这样,我们就可以用loss来表达我们的需求了:
这个公式有两层意思:
- 更新生成器使得判别器做出正确判断的概率下降
- 更新判别器使得判别器做出正确判断的概率上升
所谓正确判断是指判别器把真实数据判别为真,生成样本数据判别为假。这个过程也就是我们说的博弈的过程。但是一边上升一边下降是很难计算的,因此我们把1.反过来说:
- 更新生成器使得判别器做出错误判断的概率上升
1.对应公式:
2.对应公式:
接下来,我们分别要实现vanilla gan、ls-gan、dc-gan和wgan-gp。至于哪一种gan好,谷歌说,都差不多2333。详见那么多GAN哪个好?谷歌大脑泼了盆冷水:都没能超越原版|论文。不过从效果上看,我觉得dc-gan在手写数字生成上更好一些。
下面就是实现不同的gan了,都是调用tf的函数,建议使用tf.layers里面的函数,省的自己定义参数了,方便快捷,效果也好。
5.1 vanilla gan
判别器:
Fully connected layer from size 784 to 256
LeakyReLU with alpha 0.01
Fully connected layer from 256 to 256
LeakyReLU with alpha 0.01
Fully connected layer from 256 to 1
生成器:
Fully connected layer from tf.shape(z)[1] (the number of noise dimensions) to 1024
ReLU
Fully connected layer from 1024 to 1024
ReLU
Fully connected layer from 1024 to 784
TanH (To restrict the output to be [-1,1])
loss:有三个部分,一定注意label应该对应谁。
D_loss1 = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = logits_real, labels = D_label))
D_loss2 = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = logits_fake, labels = G_fake_label))
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = logits_fake, labels = G_real_label))5.2 ls-gan
loss有所变动,不在计算交叉熵了:
5.3 dc-gan
判别器:
32 Filters, 5x5, Stride 1, Leaky ReLU(alpha=0.01)
Max Pool 2x2, Stride 2
64 Filters, 5x5, Stride 1, Leaky ReLU(alpha=0.01)
Max Pool 2x2, Stride 2
Flatten
Fully Connected size 4 x 4 x 64, Leaky ReLU(alpha=0.01)
Fully Connected size 1
生成器:注意conv2d^T (transpose)操作是反卷积tf.nn.conv2d_transpose
Fully connected of size 1024, ReLU
BatchNorm
Fully connected of size 7 x 7 x 128, ReLU
BatchNorm
Resize into Image Tensor
64 conv2d^T (transpose) filters of 4x4, stride 2, ReLU
BatchNorm
1 conv2d^T (transpose) filter of 4x4, stride 2, TanH
5.4 wgan-gp
判别器:
64 Filters of 4x4, stride 2, LeakyReLU
128 Filters of 4x4, stride 2, LeakyReLU
BatchNorm
Flatten
Fully connected 1024, LeakyReLU
Fully connected size 1
生成器同上一个网络。
loss:这里多了gradient penalty的操作。优点详见郑华滨:生成式对抗网络GAN有哪些最新的发展,可以实际应用到哪些场景中?
由于涉及内容较多,具体的gradient penalty实现请看代码。
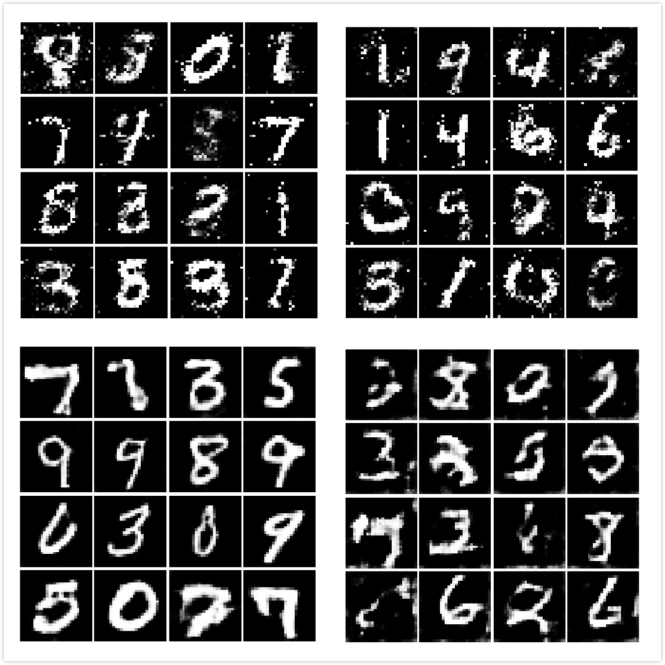
5.5 效果
最后的最后,让我们比较一下四种gan的输出结果吧!
左上vanilla gan右上ls-gan左下dc-gan右下wgan-gp。看起来还是dc-gan好呢!
恭喜看到这里的大家,你们已经完成了所有的Assignment!相信你们一定学到了很多东西,请在接下来的旅程中继续努力吧!
じゃ、おやすみ~!

下期预告: CS224n Assignment1作业详解
对你没看错!CS224n!记得来看哦!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









