





常用的链表有单链表、双链表、循环链表。
概念看得再多,理解得再多,也不一定能够写得出来。所以动动手,多练习才是提升能力的关键。
有朋友留言说道:建议大家在实现之前的思考时间不要太长。一是先用自己能想到的暴力方法实现试试。另外就是在一定时间内(比如半个小时到一个小时)实在想不到就要在网上搜搜答案。有的算法很巧妙,不能生想,就能够想到的。
说的真好。毕竟从自己已有的知识出发,才知道自己所欠缺的是什么。
首先单链表是什么样的呢
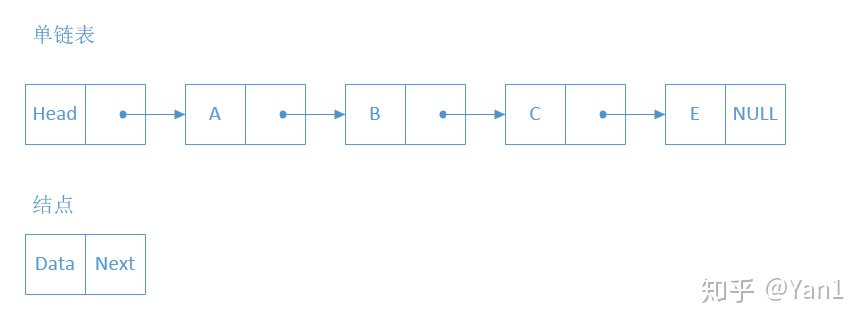
这里用了网络的图片。
每个结点存储一个数据,还有一个指针,指向的是下一个结点。
但为了区分链表为空的情况以及方便操作链表,在A前面加了一个头结点,头结点不存储数据,头结点的指针部分,指向链表的第一个结点。如上图:Head->A->B->C->E就组成了一个单链表。
由此开始粗糙的实现单链表(Java实现):
1.先从结点开始:
public 结点类Node,包含了一个数据data,还有一个指针next(Java这里叫引用)
有了结点类后,试试几个结点链起来
2.没有头结点的链表
public 这样便表达了A->B->C->E这间的链表的关系,但总觉得少了点什么。有了这个链表,能做什么用,而且A->B->C->E看起来没问题,但也不够直观。对,我们应该遍历下数据,看看对不对。
PS:这里方便写代码,将class Node加了static修饰
3.链表的遍历,引入头结点的链表比较像回事
遍历从头结点开始,下一个结点,取值,下一个结点,取值,直到没有下一个结点。也就是next,next,next直到next为null
public 执行结果
Node data: 1
Node data: 2
Node data: 3
Node data: 4
Process finished with exit code 0写了一个traverse方法来遍历链表,不传head,直接传nodeA,开始遍历好像也可以。但是没有头结点,就处理不了空链表的情况。代码写起来比较奇怪。
PS:头结点没有存储数据,所以保留空参数的构造方法Node()。
至此,遍历已经写好。但是建立head,nodeA,nodeB,nodeC..之间的关系的代码,直接赋值的方式显得非常的简陋。是不是可以考虑起个名字叫addNode,表示链表新增了一个新的结点。因此我们可以重新审视上面的代码,上面的代码一直是聚焦在Node。head,nodeA,nodeB,nodeC...的创建和关系的建立。node建立关系后成为链表。不对,我们可以从上到下来看。关注链表。然后才是链表中的结点Node。起个链表的结构叫LinkList(这个名字听起来就像链表)















 3360
3360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









