






想必很多人都听过深度学习,但是很少人知道它究竟能干什么,今天伟哥要给大家分享的就是深度学习里很热门的一个领域—图像识别。我们今天的目标就是给一张猫或者狗的图片,利用深度学习模型就能判断出它是猫还是狗,这对于我们人类来说肯定再简单不过了,但如何通过代码,让计算机也可以实现呢?下面就开始今天的正式内容吧!
1
数据说明
本次数据是jpg格式的图片。放在两个文件夹train和test中,其中,train文件夹包括12500张猫的图片,12500张狗的图片,一起组成25000张图片的训练集。猫和狗的图像分别从0-12499编号。下面展示其中一部分。

我们最后的任务是要识别的12500张没有标签的猫狗图片。全部保存在test文件夹中,下面展示其中一部分。

2
数据准备
首先是导入必要的Python包。
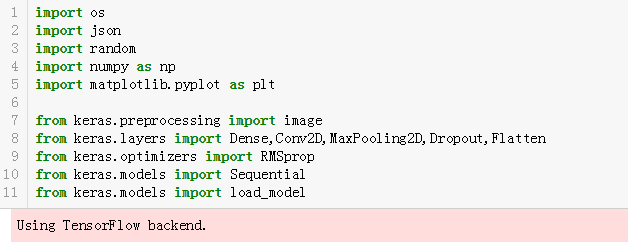
接下来是把图片分成训练集和我们最后要预测的数据集



重点解释下面代码的意思:
第1行:设置随机种子,保证每次取出来的图片都是一样的。
第3行:选出24000张猫狗数据组成我们的训练集。
第5行:选出剩下的1000张猫狗数据来评价模型最终的效果。
第7,8行:为了避免同类图片集中一起,影响模型效果,随机打乱选中的数据。
第10,12,13行:划分训练集和验证集。
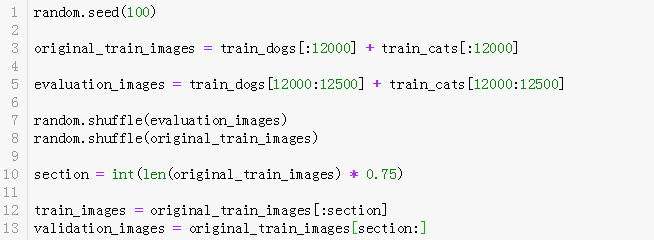
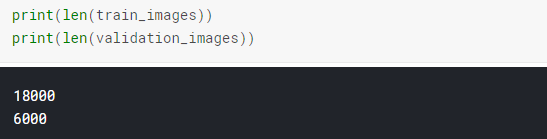
现在我们的训练集有18000张图片,验证集6000张图片。
我们通常处理的图像具有三个维度:高度,宽度和颜色深度,也就构成一个3D张量(张量也就是Numpy数组),关于颜色深度,灰度图像只有1个颜色深度,彩色图像有3个,因此,如果图像大小为150x150,那么100张彩色图像组成的批量可以保存在一个(100,150,150,3)的张量中,灰色图像则表示为(100,150,150,1),见下图。
同时,图像张量的形状有两种规定:通道在前(在Theano中使用)和通道在后(在Tensorflow中使用)。如果在Theano中使用,前面例子就变为(100,3,150,150)和(100,1,150,150)。我们下面使用的模型是在Keras框架下的,同时支持这两种格式。

接下来就把我们的图像数据变成模型可与读入的Numpy数组形式。这里需要用到image这个包(载入from keras.preprocessing import image),这是个很强大的包,后面数据增强部分也会用到它。
image.load_img可以很方便的读入图像;
image.img_to_array可以将图像转成Numpy数组;
image.array_to_img可以将数组又转成图像。我开始做的时候,我用的是cv2这个包来把图像处理成数组,进行了一系列的转换,最后在检查过拟合时发现原来一开始数据处理有问题,还好发现了新大陆!
下面编写了一个函数来处理我们的图片,重点解释下部分代码:
第3,4行:设置图像的尺寸和颜色通道。
第8行:生成一个全为0的Numpy数组,形状是(图像个数,图像高度,图像宽度,颜色通道),用来存储我们图片转化后的数组。
第9行:生成一个全0的Numpy数组,形状是(图像个数,),也就是一列。这个主要是储存每张图片的标签。在这里狗用数字1代替,猫用数字0代替。
第12,13行:先按照指定形状加载图片,再转成数组,存在X这个我们开始创建的数组里。
第14,15行:如果‘dog’在文件名中,则对应位置记为1,否则记为0,这也就实现了我们对图片的标签化。
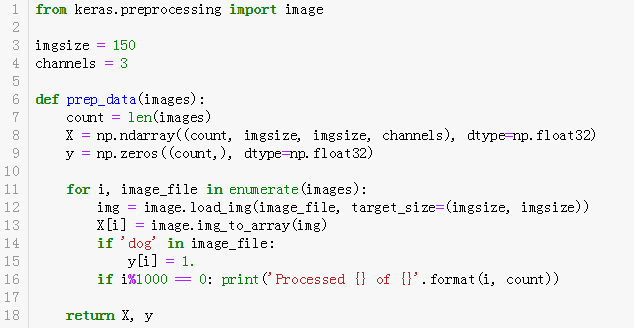
下面就是调用我们刚刚的prep_data函数来处理我们的训练集和验证集:


和我们说的一样,训练集一共18000张图片,存在了(18000,150,150,3)的张量中。
3
数据增强
其实数据增强也是数据准备的一部分,这里拿来单独说,是我觉得这一部分挺重要的,特别是在数据集比较小的时候,数据增强能很好帮助我们解决数据不足而出现过拟合这一问题。我开始的模型没有用数据增强,因为我确信25000张训练集足够用了,但后来跑完模型后出现了严重过拟合问题,最后还是乖乖地用了这一利器。
我们知道,如果数据量太小,那就无法训练出能泛化到新数据的模型,就会出现过拟合,而数据增强就是从现有的训练样本中生成更多的训练数据,他主要是利用图像的随机变换,例如旋转角度,平移,缩放等操作来增加样本,让模型能学习到更多的数据,从而具有更好的泛化能力。在Keras中主要是用ImageDataGenerator来实现(from keras.preprocessing.image import ImageDataGenerator)
下面解释下其中部分参数的含义,详情可以查看Keras官方文档 https://keras.io/
rotation_range:是一个0-180的度数,用来指定随机选择图片的角度。
width_shift和height_shift:用来指定水平和竖直方向随机移动的程度,这是两个0-1之间的比例。
Rescale:将在执行其他处理前乘到整个图像上,我们的图像在RGB通道都是0-255的整数,这样的操作可能使图像的值过高或过低,所以我们将这个值定为0-1之间的数。
shear_range:是用来进行剪切变换的程度,参考剪切变换。
zoom_range:用来进行随机的放大。
horizontal_flip:随机的对图片进行水平翻转,这个参数适用于水平翻转不影响图片语义的时候。
fill_mode:用来指定当需要进行像素填充,如旋转,水平和竖直位移时,如何填充新出现的像素。
接下来我会用一张图片来给大家演示下效果。下面代码就实现了把一张图片实现各种变换来达到数据增强的目的。
第20-27行:这里datagen.flow将从数据中无限生成随机变换后的图像批量。因此设置了条件来终止循环。

这是原图

来看看增强后的效果
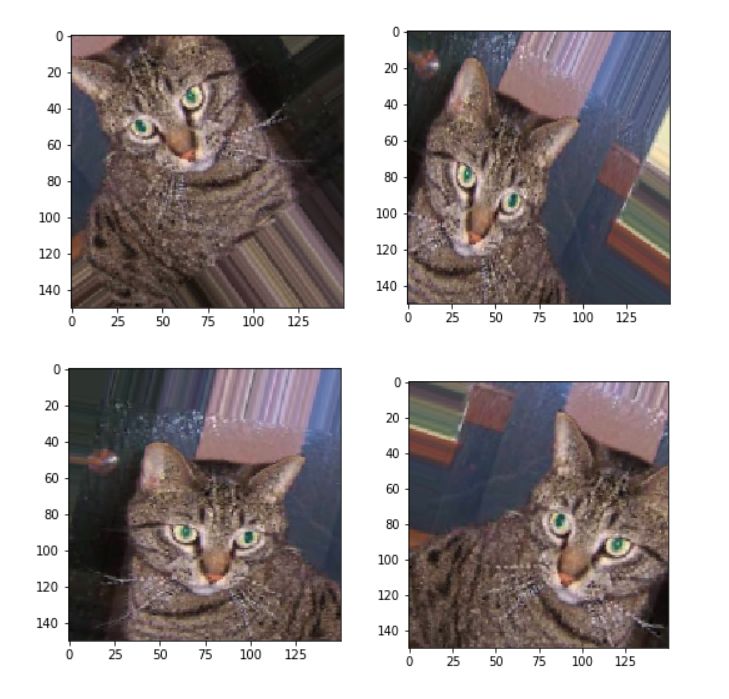
接下来我会在训练集实现数据增强。
这里重点说下rescale,rescale值会在执行其他处理前,乘到整个图像上,我们的图像在RGB通道都是0-255的整数,乘以1/255.这样的操作可能使图像的值定为0-1之间的数,神经网络喜欢处理较小输入的值。

对于验证集,只进行rescale,改变值到0-1这个操作就行了。

4
建立模型
其实对于建模部分,能说的很少,只要是前面数据处理成模型可读入的形式,一般就不会有什么问题,这次模型使用的是卷积神经网络,主要是Conv2D层和MaxPooling2D层交替堆叠,最后加一个Flatten层和Dropout层,我看到有的大神每一个池化层后都用了一个Dropout层,还有的使用了多个卷积层,准备有机会试试效果。下面是我模型的简单代码。
几点注意的就是:
第3行:input_shape里的数据要和我们输入进去的数组格式对应,即(150,150,3)第19行:由于我们是二分类问题,所以最后一层是只有一个单元并且激活函数使用sigmoid的Dense层,输出是0-1范围的标量,表示概率。第21行:二分类问题,使用binary_crossentropy损失函数,使用accuracy作为指标,对于优化器optimizers,我看很多大神使用RMSprop,于是直接借鉴,也有使用Adam的。

使用model.summary()来看看我们网络的结构。最大池化层和Dropout层会改变网络的部分数值,不用担心。

接下来就是要直接拟合数据跑模型了,有几点需要注意:
第1,2行:因为数据不断生成,Keras每一轮要知道从生成器抽取多少样本,这里就是样本数,每个批量包含BATCH_SIZE = 128个样本,读取完18000个样本就需要大约140个批次。第4行:由于我们使用了数据增强,所以通常的model.fit变成了model.fit_generator,它的第一个参数就是我们的Python生成器,即前面的train_generator。第7行:验证集就是用前面的validation_generator,也是一个Python生成器。

我的模型在GPU上一共跑了大约2个多小时,准确率有91%多,没有数据增强时,跑了大约30多分钟,但是效果很差,过拟合严重,后来我在CPU上跑了试了一下,跑了一晚上,所以建议还是使用GPU。
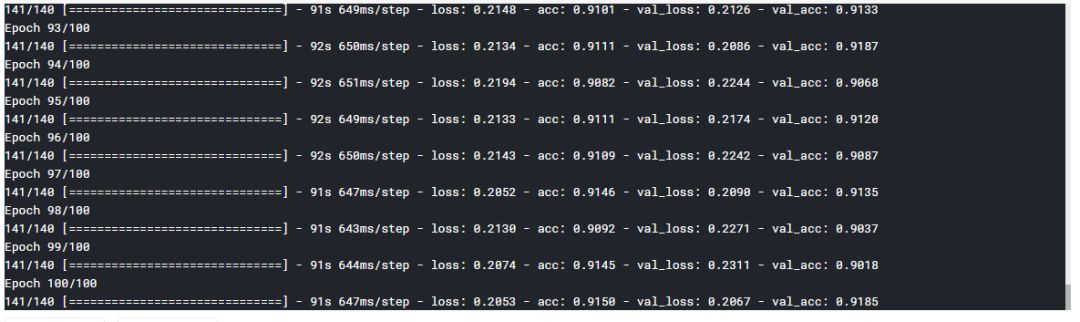
接下来画图看看模型准确率和损失值,history中包含了模型的四个参数:训练集准确率acc,验证集准确率val_acc,训练集损失loss,验证集损失val_loss。

可以看到,训练集和验证集准确率随着训练轮次的增加同步增加,没有过拟合现象。
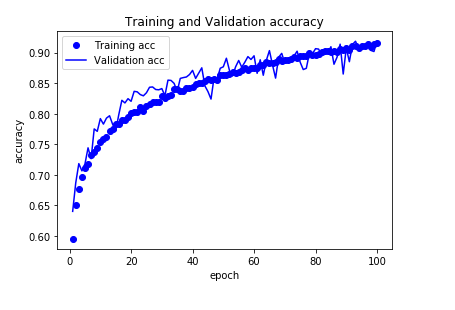
训练集和验证集的损失也随着训练轮次的增加同步递减。
我们的模型效果还是很不错的,可以把训练后的模型权重保存下来,下次就可以直接导入权重,不用再耗时重头训练模型。并把我们模型的history中相关信息保存到json文件。

要说模型效果好,只通过两张图并不能让大家信服,还记得我们开始创建了1000张图片的数据集吗,现在就派上用场了,我们可以用它来评估我们的模型。第一步还是用prep_data函数来处理数据。注意以下几点:
第1,2行:前面我们是使用数据增强里的参数把数据范围变到0-1,这里直接除以255.来改变值的范围。
第4行:使用model.evaluate来评估模型,返回值是损失值和前面模型定义的指标值metrics,这里指标是accuracy。


准确率在0.909,说明效果还不错。
下面就是激动人心的时候了,我们要开始预测12500张未标签的猫狗数据了!
第1行:我们prep_data函数函数返回的是两个值,要预测的数据没有标签,因此‘_=’会返回我们的数组,而不是标签。第4行:使用model.predict直接来预测。

执行完上面的代码,我们已经预测完了,结果就保存在predictions 中,里面是0-1范围的一些值。可是我们并不能很直观的知道预测的准不准。下面我会把原始的图片和我们预测的值一起显示给大家,由于有12500张,因此,我只显示了4张。
第1-8行:由于规定dog用1,cat用0,如果predictions的值大于0.5,我就认为预测的是dog,否则就预测是cat。image.array_to_img把数组转成图像

来一起看看结果:



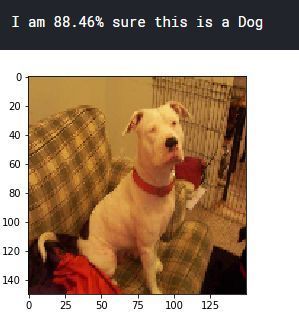
当然,这些都是预测准的,我还多看了几张,就发现有预测错误的,毕竟我们的准确率是90%多,没到100%。下面这张,就把一个白猫预测成了狗

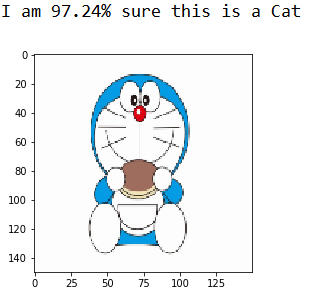
作为一个爱玩的人,我还没有玩够,因此,我又从网上找了一张多啦A梦图片,看看能不能预测准呢?这里我直接加载训练好的权重文件,用来预测。

看来多啦A梦的确是只猫。
5
小结
很早前就接触了这个数据集,也做了部分工作,但有的部分没有很透彻,所以也就没有做完,但随着知识越来越丰富,积累的经验越来越多,发现以前不懂的地方现在再回头看,竟然格外透彻。
前段时间网上到处被李彦宏刷屏,借用他演讲时说的一句话:“在AI前进的道路上会有各种各样的事情发生,但是前进的决心不会改变”。本次分享的内容都是我在解决各种问题后实现的最好的结果,其实在做这个项目的时候,我也碰到各种问题:数据预处理,GPU内存溢出,过拟合等等,但只要前进的决心不改变,问题也会迎刃而解,而解决问题的过程恰恰是成长最快的时候。
下面是一些心得分享给大家,希望大家有收获:
① 无论是机器学习还是深度学习,数据是最重要的。模型很重要但不是最重要!
② 过拟合很常见,可能是使用的数据少了,可以用数据增强。
③ 学习是很奇妙的东西,一时半会不懂的知识,先放一放,说不定积累多了,见识多了,某个时刻突然就懂了。放一放不是指放弃!
④ 网上资源很多,大神也很多,要学会查找利用,站在巨人的肩膀上,善于学习!
以上仅是个人观点,谢谢阅读,下次再见!
文字来源|木子偉
图片来源|木子偉
编辑|宋欣蕊
审核|叶紫薇
欢迎大家转发,但大家记得标明原创出处哟~如果喜欢记得点【在看】呀~,扫描关注我们的公众号↓
















 3920
3920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









