





原标题:python带图片验证码的登录自动化实战
近期在跟进新项目的时候,整体的业务线非常之长,会一直重复登录退出不同账号的这个流程,所以想从登录开始实现部分的自动化。因为是B/S的架构,所以采用的是selenium的框架来实现。大致实现步骤如下:
1.环境准备
2.验证码爬取
3.识别方案选择
4.图像处理和识别
5.自动化实现
一、环境准备
系统:macOS
软件:Pycharm
语言:Python 2.7
浏览器:Chrome 70.0.35
依赖库:selenium 3.141、xlrd 1.1、aip 1.0.0.5、pytesser、pytesseract 0.2.5、opencv-python 3.4.3、urllib3 1.24.1、Pillow-PIL 0.1
驱动安装与配置环境:
①下载chromedriver:http://chromedriver.storage.googleapis.com/index.html(需代理)、http://npm.taobao.org/mirrors/chromedriver/(无需代理)
②具体浏览器与驱动版本映射表可参考 https://blog.csdn.net/huilan_same/article/details/51896672
③解压后放置在 /urs/bin/目录下
④加入环境变量:export PATH=$PATH:/usr/local/bin/ChromeDriver
二、验证码爬取
对于验证码而言,目前各式网站出现的验证码类型基本有:图形验证码(数字、计算题、中文、英文、问答题)、滑块验证码、语音验证码、图片验证码(正倒序、同类型)。自身项目的验证码为数字+英文图形验证码,针对这一块的内容,首先我们先来爬取一些验证码到指定文件夹中,来着重分析一下特点,代码如下:

大致讲解一下上面出现的一些函数用法和实现过程中存在的问题。
1.使用classname定位,运行时报错
A:一般来说,使用classname来定位还是比较精准的,但是此项目的classname包含了多个tag,如上述的登录按钮class='ant-btn logining-btn ant-btn-primary ant-btn-lg ant-btn-background-ghost',这时候使用 find_elements_by_class_name方法定位,会无法定位并报错。所以需要使用find_elements_by_css_selector,大家可以根据各自项目来选择方法。
2.urllib.urlretrieve(src,local)
urllib模块提供的urlretrieve()函数,urlretrieve()方法直接将远程数据下载到本地,传入下载的链接。
3.命令行获取参数
为了指定我们想要下载的验证码数量,要在源程序里面修改吗?不用。sys.argv[]是一个从程序外部获取参数的桥梁,所获得的是一个列表(list),文中的sys.argv[1]则是代表获取列表中的下标为1的内容,在终端我们运行的方法是:python catch_code.py 10 ,这样sys.argv[1]取到的的值则为10,num的值亦为10,循环10次下载验证码。
三、识别方案选择
上节中爬取下来了100张验证码,如下图:

基本特性是:横向排列、数字与英文字母组合、字母间粘连占比约30%、背景干扰较少。阅读已有的一些ocr识别技术,基本有以下三个方向:
① pytesser
② pytesseract
③ 百度文字识别 AipOcr
为了对比这三者识别技术的识别率,对应实现来展示效果,所以样本选择为0.png、4.png、11.png(字母粘连、纯字母、字母+数字)
pytesser:谷歌OCR开源项目的一个模块,在python中导入这个模块即可将图片中的文字转换成文本。pytesser下载链接:http://code.google.com/p/pytesser/ ,实现代码如下:

image_file_to_string()函数可以实现简单的英文字母识别,如果图像是不相容的,会先转换成兼容的格式,然后再提取图片中的文本信息。
image_to_string()函数亦可实现英文字母识别,读取图片时,将内存中的图像文件保存为bmp,再使用tesseract处理。
执行结果如下:
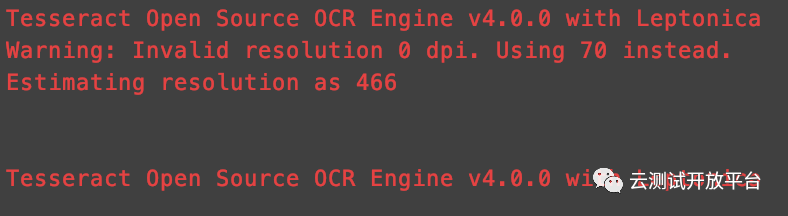
顺序识别0,4,11图片后均无法识别结果,识别概率为0%
pytesseract:Google的Tesseract-OCR引擎包装器

顺序识别0,4,11图片后均无法识别结果,识别概率为0%
AipOcr:一款百度提供的OCR识别服务,支持多种图片格式,接口免费调用50000次/日,具体请参考官方文档:https://ai.baidu.com/docs#/OCR-API/top ,在实现之前,我们需要创建一款产品,来获得AppID、API Key、Secret Key的值。如下图:

获取到以上三个参数后,继续上代码:

顺序识别0,4,11图片后,图片11识别出了一半,提取到了"2F",概率为16%
四、图像处理和识别
在上节看来,未经过处理的图片进行识别,识别概率都非常之低。所以我们换一个角度来思考,通过对图片进行一些处理,使得特征更加明显,再通过上述的三种识别库来识别,提高识别的概率。步骤大致如下:1)灰度二值化 2)线降噪 3)开运算
1)灰度二值化
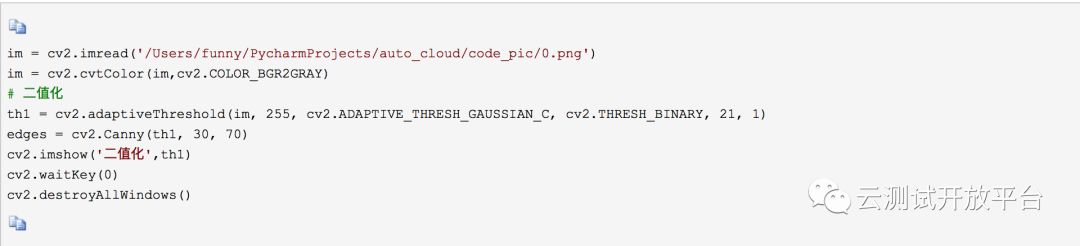
处理的图像如下:
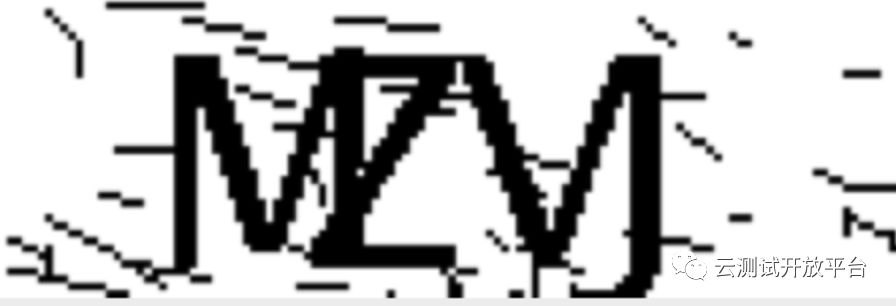
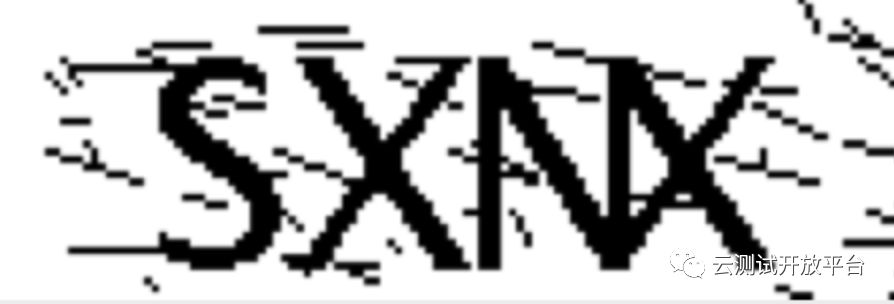
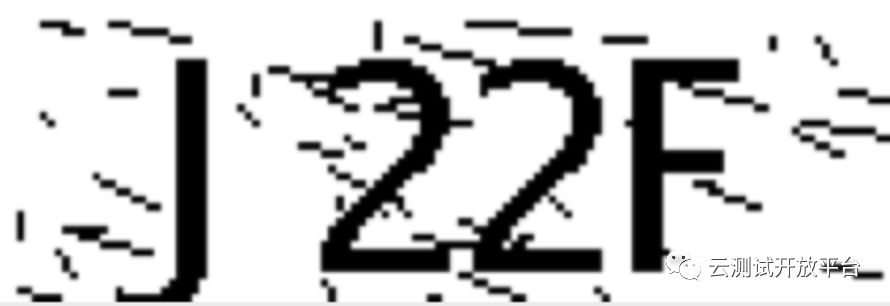
2)线降噪

处理的图像如下:

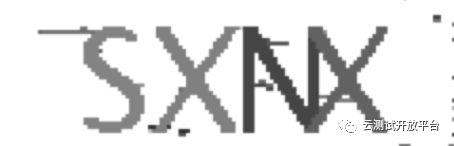

3)闭运算

处理的图像如下:



图像处理到现在基本上我们已经将已有的背景干扰及色彩去除完毕,接下来我们针对这些处理的图像进行三种识别方案的识别,识别结果如下表:

我们来分析一下这个表,在最开始的二值化,AipOcr至少识别出来了一些内容。纵观三种图像处理后的识别效果,明显闭运算已经能识别出大致的内容了,图片4.png三种识别方式都是可以识别出来,对于0.png这种粘连字母,识别效果基本为0%,而11.png“j”的底部表现不出来,所以识别不出来,但后面的内容亦识别成功。所以我们可以总结三点:①识别方式精准度 :AipOcr>pytesser>pytesseract。 ②处理后效果:闭运算>线降噪>二值化。③粘连性、带噪点图片识别效果非常差(当前准确值是基于我选取的样本集)。
五、自动化实现
从上节的处理和识别中的总结内容中,本项目我们选择将AipOcr作为识别,若识别结果不正确(如粘连、噪点过多、部分裁剪图片),将获取新的验证码,以此类推。将上述部分代码封装,方便调用,最终完整代码请参考原文链接(https://www.cnblogs.com/fightccc/p/9995387.html)里第五部分。
对于粘连性及部分被切割的验证码,还需要再研究一番~
另,因为验证码识别率还不能达到100%,且后期可能因为版本迭代的原因,更换不同方式的验证码类型,所以这里只是提供一个图像预处理思路给到大家,实现登录自动化还有其他方式,如白名单控制、关闭验证码校验等。返回搜狐,查看更多
责任编辑:















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









