





在工作中大家都接触过PDF文件,如果你的领导让你把PDF文件中的文字提取出来,你还在急的焦头烂额?今天就教给大家几个实用的方法,一键轻松提取PDF文字。

1.直接复制粘贴
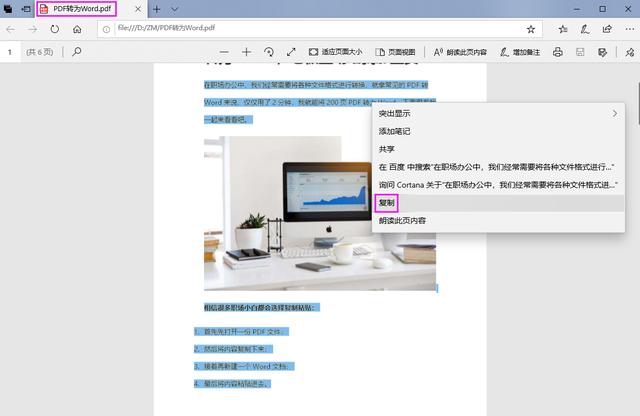
最简单直接的方法就是复制粘贴了,找到一份需要提取文字的PDF文件,双击直接打开,只需要拖动鼠标选中内容,然后右击选择【复制】就好了。
但是这种方法只能复制文本,如果你的PDF文件中有图片的话,是不能提取的哦。
2.Word打开PDF
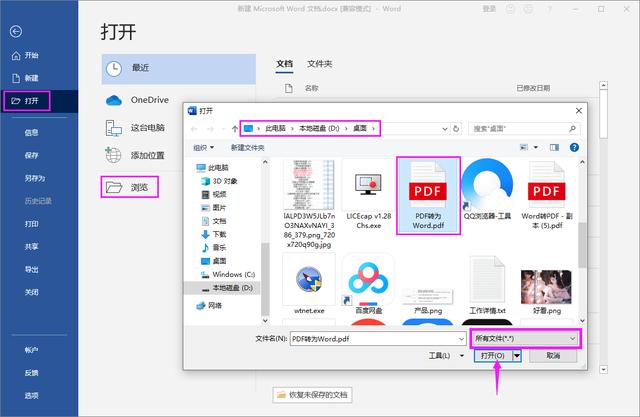
还有一种方法就是从Word中打开PDF,新建一个Word文档,点击【打开】-【浏览】,在电脑文件夹中选择【所有文件】,然后找到PDF文件点击【打开】。
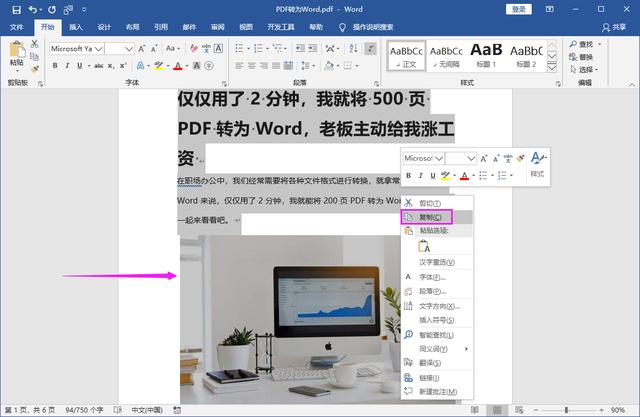
接着就能看到,PDF文件中的内容在Word中展现了,这种方法你可以理解为将PDF转换成Word,PDF文件到了Word中,还不是想复制就复制?
3.工具扫描PDF
以上的两种方法,都可以提取PDF文字,然而在工作中,如果有大量的PDF文件需要提取,就需要使用迅捷PDF转换器,一键批量识别了。
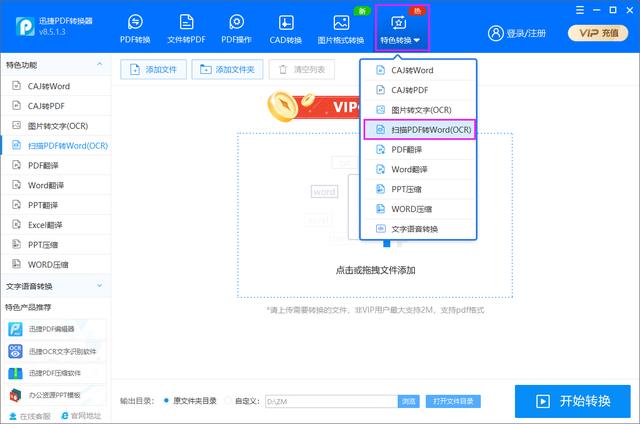
首先我们打开这个工具,进入转换器中,在顶部点击【特色转换】,然后在下拉框中选择【扫描PDF转Word(OCR)】。
接下来点击【添加文件】,从电脑文件夹中找到需要提取的PDF文件,按住【Alt】键可以批量选中,再点击【打开】。
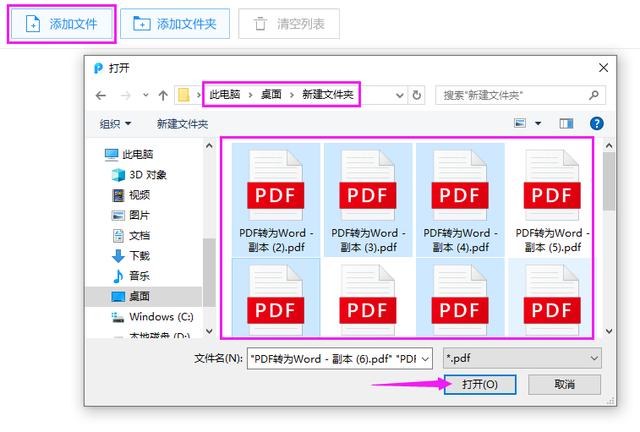
当PDF文件添加完成后,在底部将输出格式改为【DOCX】;将识别结果改为【图文混排】;将输出目录改为【原文件目录】。
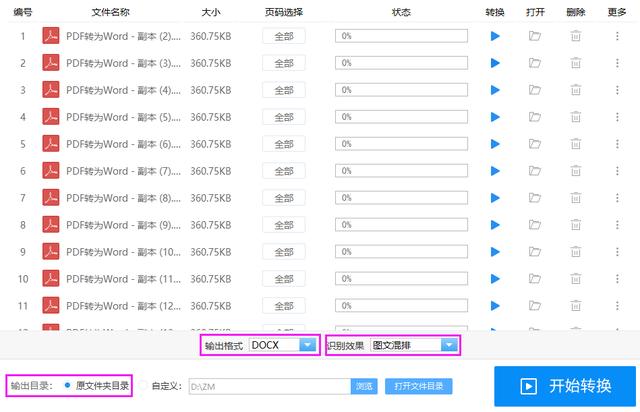
最后就可以点击【开始转换】按钮了,等待十几秒,就可以将所有的PDF文件转换完成了,点击底部的【打开文件目录】,查看识别结果。
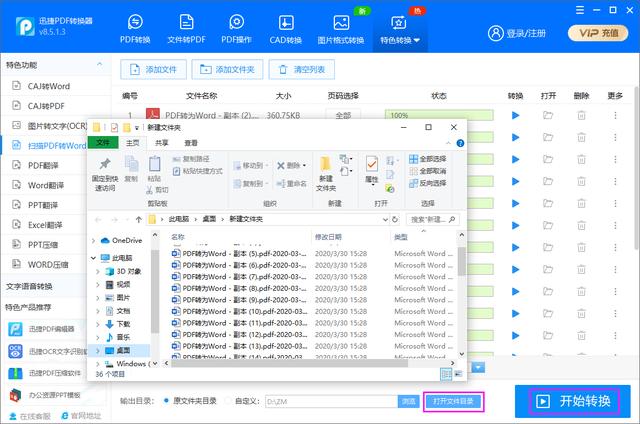
原来PDF提取文字这么简单,大家都学会了吗?















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









