





本文在调参记录17的基础上,将残差模块的数量增加到27个。其实之前也这样做过,现在的区别在于,自适应参数化ReLU激活函数中第一个全连接层中的神经元个数设置成了特征通道数量的1/16。同样是在Cifar10数据集上进行测试。
自适应参数化ReLU激活函数的基本原理如下:
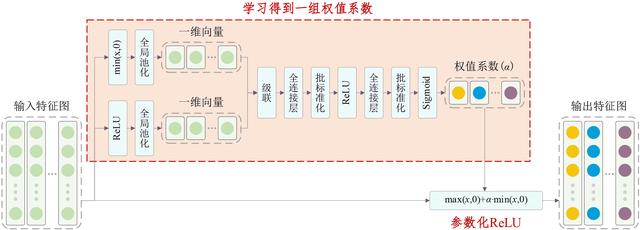
自适应参数化ReLU激活函数
Keras代码如下:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""Created on Tue Apr 14 04:17:45 2020Implemented using TensorFlow 1.0.1 and Keras 2.2.1Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Shaojiang Dong, Michael Pecht,Deep Residual Networks with Adaptively Parametric Rectifier Linear Units for Fault Diagnosis, IEEE Transactions on Industrial Electronics, 2020, DOI: 10.1109/TIE.2020.2972458 @author: Minghang Zhao"""from __future__ import print_functionimport kerasimport numpy as npfrom keras.datasets import cifar10from keras.layers import Dense, Conv2D, BatchNormalization, Activation, Minimumfrom keras.layers import AveragePooling2D, Input, GlobalAveragePooling2D, Concatenate, Reshapefrom keras.regularizers import l2from keras import backend as Kfrom keras.models import Modelfrom keras import optimizersfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.callbacks import LearningRateSchedulerK.set_learning_phase(1)# The data, split between train and test sets(x_train, y_train), (x_test, y_test) = cifar10.load_data()# Noised datax_train = x_train.astype('float32') / 255.x_test = x_test.astype('float32') / 255.x_test = x_test-np.mean(x_train)x_train = x_train-np.mean(x_train)print('x_train shape:', x_train.shape)print(x_train.shape[0], 'train samples')print(x_test.shape[0], 'test samples')# convert class vectors to binary class matricesy_train = keras.utils.to_categorical(y_train, 10)y_test = keras.utils.to_categorical(y_test, 10)# Schedule the learning rate, multiply 0.1 every 1500 epochesdef scheduler(epoch): if epoch % 1500 == 0 and epoch != 0: lr = K.get_value(model.optimizer.lr) K.set_value(model.optimizer.lr, lr * 0.1) print("lr changed to {}".format(lr * 0.1)) return K.get_value(model.optimizer.lr)# An adaptively parametric rectifier linear unit (APReLU)def aprelu(inputs): # get the number of channels channels = inputs.get_shape().as_list()[-1] # get a zero feature map zeros_input = keras.layers.subtract([inputs, inputs]) # get a feature map with only positive features pos_input = Activation('relu')(inputs) # get a feature map with only negative features neg_input = Minimum()([inputs,zeros_input]) # define a network to obtain the scaling coefficients scales_p = GlobalAveragePooling2D()(pos_input) scales_n = GlobalAveragePooling2D()(neg_input) scales = Concatenate()([scales_n, scales_p]) scales = Dense(channels//16, activation='linear', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(scales) scales = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(scales) scales = Activation('relu')(scales) scales = Dense(channels, activation='linear', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(scales) scales = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(scales) scales = Activation('sigmoid')(scales) scales = Reshape((1,1,channels))(scales) # apply a paramtetric relu neg_part = keras.layers.multiply([scales, neg_input]) return keras.layers.add([pos_input, neg_part])# Residual Blockdef residual_block(incoming, nb_blocks, out_channels, downsample=False, downsample_strides=2): residual = incoming in_channels = incoming.get_shape().as_list()[-1] for i in range(nb_blocks): identity = residual if not downsample: downsample_strides = 1 residual = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(residual) residual = aprelu(residual) residual = Conv2D(out_channels, 3, strides=(downsample_strides, downsample_strides), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(residual) residual = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(residual) residual = aprelu(residual) residual = Conv2D(out_channels, 3, padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(residual) # Downsampling if downsample_strides > 1: identity = AveragePooling2D(pool_size=(1,1), strides=(2,2))(identity) # Zero_padding to match channels if in_channels != out_channels: zeros_identity = keras.layers.subtract([identity, identity]) identity = keras.layers.concatenate([identity, zeros_identity]) in_channels = out_channels residual = keras.layers.add([residual, identity]) return residual# define and train a modelinputs = Input(shape=(32, 32, 3))net = Conv2D(16, 3, padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(inputs)net = residual_block(net, 9, 32, downsample=False)net = residual_block(net, 1, 32, downsample=True)net = residual_block(net, 8, 32, downsample=False)net = residual_block(net, 1, 64, downsample=True)net = residual_block(net, 8, 64, downsample=False)net = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(net)net = aprelu(net)net = GlobalAveragePooling2D()(net)outputs = Dense(10, activation='softmax', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(net)model = Model(inputs=inputs, outputs=outputs)sgd = optimizers.SGD(lr=0.1, decay=0., momentum=0.9, nesterov=True)model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])# data augmentationdatagen = ImageDataGenerator( # randomly rotate images in the range (deg 0 to 180) rotation_range=30, # Range for random zoom zoom_range = 0.2, # shear angle in counter-clockwise direction in degrees shear_range = 30, # randomly flip images horizontal_flip=True, # randomly shift images horizontally width_shift_range=0.125, # randomly shift images vertically height_shift_range=0.125)reduce_lr = LearningRateScheduler(scheduler)# fit the model on the batches generated by datagen.flow().model.fit_generator(datagen.flow(x_train, y_train, batch_size=100), validation_data=(x_test, y_test), epochs=5000, verbose=1, callbacks=[reduce_lr], workers=4)# get resultsK.set_learning_phase(0)DRSN_train_score = model.evaluate(x_train, y_train, batch_size=100, verbose=0)print('Train loss:', DRSN_train_score[0])print('Train accuracy:', DRSN_train_score[1])DRSN_test_score = model.evaluate(x_test, y_test, batch_size=100, verbose=0)print('Test loss:', DRSN_test_score[0])print('Test accuracy:', DRSN_test_score[1])结果如下:
Train loss: 0.04765264599025249Train accuracy: 0.9993600006103516Test loss: 0.2855186524987221Test accuracy: 0.9428000026941299测试准确率第一次突破了94%。
其实,在训练的后半阶段还是出现了过拟合,说明还要针对性地调整超参数。
同时,似乎没必要训练5000个epoch。因为epoch再多,loss也不怎么下降。
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Shaojiang Dong, Michael Pecht, Deep Residual Networks with Adaptively Parametric Rectifier Linear Units for Fault Diagnosis, IEEE Transactions on Industrial Electronics, 2020, DOI: 10.1109/TIE.2020.2972458
https://ieeexplore.ieee.org/document/8998530















 2144
2144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









