






什么是Hive?
Hive是基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表。Hive提供类似SQL的HiveQL的数据处理功能,Hive将HiveQL语句转换成MapReduce程序交给Hadoop集群处理。

为什么要用Hive?
MapReduce实现复杂查询逻辑开发难度太大,人员学习成本太高,项目周期要求短,引入Hive可以使用HiveQL这种类SQL语法,提供快速开发的能力,避免写MapReduce程序,降低学习成本。
Hive的组成:
用户接口;CLI、HiveServer2、HUE
元数据存储;
解释器、编译器、优化器、执行器。
各组件的功能:
用户接口:
CLI:使用shell客户端进行交互,用Hive进行通信。
HiveServer2:通过JDBC或者ODBC去访问Hive。
HUE:通过Web页面来和Hive进行交互。
元数据存储:
Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,修改时间,表类型(内部表、外部表),创建时间,存储位置,表的字段信息等。
解释器:解释器的作用是将HiveSQL语句转换为语法树(AST)。
编译器:编译器是将语法树编译为逻辑执行计划。
优化器:优化器是对逻辑执行计划进行优化。
执行器:执行器是调用底层的运行框架执行逻辑执行计划。
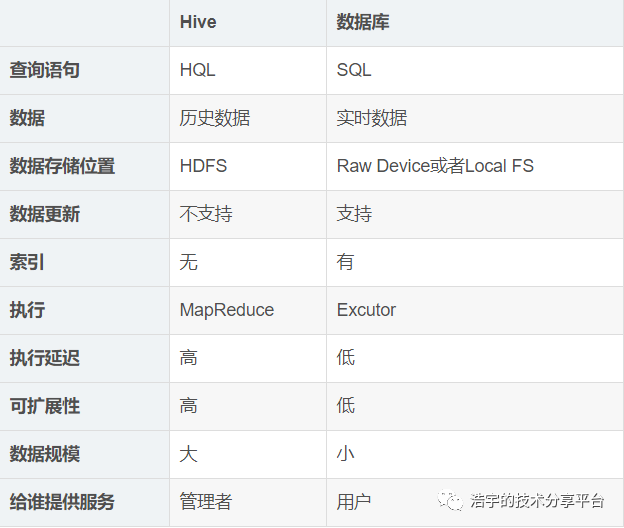
Hive与传统数据库对比:
Hive的数据存储:
Hive是建立在Hadoop系统之上的。Hive本身没有专门的数据存储格式,所有的数据都存储在HDFS中。
Hive不能为数据建立索引,用户需要在建立表时指定Hive数据中的列分隔符和行分隔符即可解析数据。
Hive中包含四种数据模型:Table,External Table,Partition,Bucket
Table:Hive中的表和数据库中的表在概念上是类似的,每个表在Hive中都有一个对应的存储目录。
External Table:外部表与Table类似,但是External Table的数据存放位置可以在任意指定路径。
Partition:分区,在hdfs中表现为table目录下的子目录。
Bucket:桶, 在HDFS中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中。
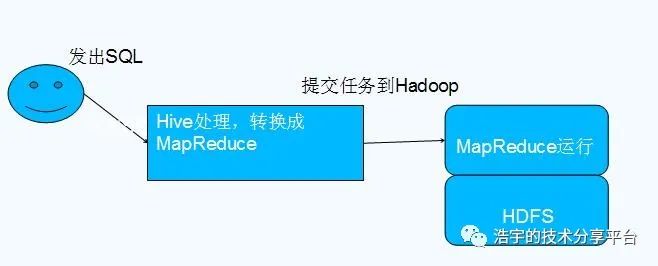
Hive与Hadoop的关系:
Hive将HQL语句转换成MapReduce程序,交给MapReduce计算处理,并存储到HDFS中。















 1727
1727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









