






反爬手段最重要的一环就是加入各种验证码,其中最简单的形式就是图片验证码了,图片验证码当然也有简单和困难的,交互型的验证码比如

这里作为入门级的分享,只说说简单的验证码如何识别。尽管图片验证码已经有点过时了,但其实还是挺多网站还在采用的。算是抛砖引玉,可以为我们后期作更深的爬虫作点思想准备。
这次的任务是来识别知网注册页的验证图片
注册my.cnki.net请出今天的主角是Tesserocr。Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本。没错,输入图片,输出文字,就这么简单。那他的识别效果如何呢?我亲自测试一下,

识别结果
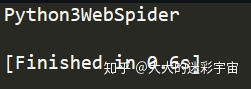
图片很清晰,识别很不错。
安装
我前面的文章很少讲安装,因为都是基本操作,在网上都能搜到相应的教程,然而今天这个Tesserocr带坑有点严重,笔者安装过程也走了点弯路,记录一下,以供参考。
tesserocr的安装
1 安装tesserocr的依赖tesseract。https://digi.bib.uni-mannheim.de/tesseract/
进入下载页面,可以看到有各种.exe文件的下载列表,其中文件名中带有dev的为开发版本,
不带dev的为稳定版本,我自己选择下载的是tesseract-ocr-setup-3.05.01.exe
2 下载完成后双击exe文件,此时可以勾选Additional language data(download)选项来安装OCR识别支持
的语言包,这样OCR便可以识别多国语言,语言较多,下载时间会比较长,建议找到中文简体和中文繁体,
按需勾选,然后点下一步,也可以不选语言包,后面可以从网页上直接下载语言包, 放入安装目录下tessdata
目录下面即可
3 配置相应的环境变量
我们需要配置两个环境变量一个是path环境变量,一个新建环境变量 TESSDATA_PREFIX
TESSDATA_PREFIX 对应的地址是 C:Program Files (x86)Tesseract-OCRtessdata
path变量新增2个
C:Program Files (x86)Tesseract-OCR
C:Program Files (x86)Tesseract-OCRtessdata
4 设置完环境变量后,打开cmd窗口看能否识别 tesseract 输入命令 tesseract -v
5 获得数据文件。将 Tesseract-OCR安装根目录下 比如 C:Program Files (x86)Tesseract-OCR
的 tessdata 文件夹复制到Anaconda的安装目录下,比如C:Usersyx2018011502Anaconda3 下即可 。
如果你的python环境不是Anaconda,就复制到对应的python环境下环境变量根据自己的安装目录调整即可。如果把上面的步骤做完,一般不会出现其他意外。。。我不敢保证~~
mac下安装tesseract就简单多了,
brew install tesseracttesseract安装完, 安装pillow
pip install pillow最后正式安装tesseract,pip搞不定这个,不信你们试试,
win用户打开链接 simonflueckiger/tesserocr-windows_build
下载tesserocr-2.2.2-cp36-cp36m-win_amd64.whl 文件(根据自己系统选择),并将该文件放至 pip命令所在目录,我是使用的anconda环境我的目录路径,然后在那个路径下
pip install tesserocr-2.2.2-cp36-cp36m-win_amd64.whlmac用户一般pip install tesserocr 就可以了,如果出现意外
/usr/local/include/tesseract/host.h:28:10: fatal error: 'cstdint' file not found
#include <cstdint> // int32_t, ...
^~~~~~~~~
error generated.
error: command 'gcc' failed with exit status 1
-------------------------------------------按路径将 host.h文件中的 include<cstdint>改为 include include<stdint.h> 步骤如下
1 cd /usr/local/Cellar/tesseract/3.05.02/include/tesseract/
2 open -e host.h
3 将host.h文件中的include<cstdint>为include<stdint.h>根据自己的路径调整。
安装完毕测试代码
import tesserocr
from PIL import Image
image = Image.open('./img/cut.png')
result = tesserocr.image_to_text(image)
print(result)自己选择一张图片测试即可
测试
完了我弄一张知网的验证码,

图片太小了,手动放大截图放上来,识别结果不理想
可能图片太模糊了,稍微处理下吧,作灰度处理以及二值化操作,灰度处理可以使背景的干扰线条被淡化,二值化就是把图片的rgb256个颜色改成1和0,简单说就是黑白处理,那怎么区分黑白呢,设定一个阈值,在这举个例子,以上面的图片为例
import tesserocr
from PIL import Image
image = Image.open('./img/python.png')
image = image.convert('L')
threshold = 165
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table,'1')
image.show()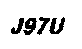
背景被虚化了,这里165就是设定的阈值。处理以后的图片 不会被线条干扰,导致整个图片识别不出来。经过我多次测试,发现单个字母准确率还行,但是整个验证码准确度就堪忧了,我打算做 样本来作为素材进行训练来提高识别准确度。那先写个程序来获取测试样本吧。先用selenium来获取目标的动态验证码
审查元素发现这张图片不是一个具体地址

是一个动态的地址,那咋办,每次验证码都是不同的,我这里给出的方案是截图,对图片进行截图,当然不是手动,
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from pyquery import PyQuery as pq
import re
import time
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
class Crack():
def __init__(self):
self.url = 'http://my.cnki.net/elibregister/commonRegister.aspx#'
self.browser = webdriver.Chrome(options=chrome_options)
self.wait = WebDriverWait(self.browser, 100)
self.browser.get(self.url)
def get_code_name(self):
doc = pq(self.browser.page_source)
getCodeID = doc('#checkcode').attr('src')
pattern = re.compile('.*id=(.*)',re.S)
result = re.match(pattern,getCodeID)
return result[1]
def mult_get_code_img(self):
checkcode_tap = self.wait.until(EC.presence_of_element_located((By.ID, 'checkcode')))
save_path = './imgs/{}.png'.format(self.get_code_name())
# 截图
ele = self.browser.find_element_by_id('checkcode')
ele.screenshot(save_path)
checkcode_tap.click()
time.sleep(1)
if __name__ == '__main__':
crack = Crack()
for item in range(20):
crack.mult_get_code_img()循环20次,截图完暂停1秒,对图片进行点击就会更新,这样子,我就成功拿到20个样本
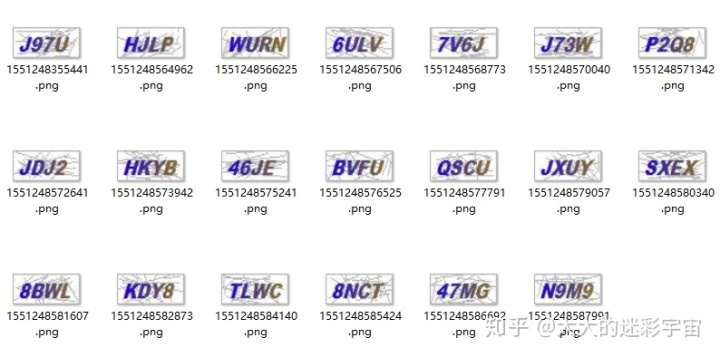
样本当然越多越好,但是作为示例,就放20个进行训练。接下来要做的事就是要把20个样本变成训练数据给tesserocr。 训练样本需要一个工具,jTessBoxEditor, 这个工具是用java开发的,需要jre7以上的版本支持。 下载地址,
Browse /jTessBoxEditor at SourceForge.netsourceforge.net眼睛放亮,不要看到download就点,看清楚名字是否是jTessBoxEditor,这个工具是打开的bat程序,mac不能直接运行(除非用虚拟机) 。。。
为了方便处理,我先把这20张图片合并成1张,并且生成一个png和一个tif文件,命名都统一为code.font.exp1, 命名规则,
[lang].[fontname].exp[num]
lang是语言
fontname是字体 调用系统命令生成一个box文件,此文件是后面让我们用来矫正的,处理如下
import PIL.Image as Image
import os, sys
img_lis = os.listdir('imgs')
img_ex = Image.open(os.getcwd()+'imgs'+img_lis[0])
img_ex_width = img_ex.width
img_ex_height = img_ex.height
wrap_width = img_ex_width * 5
wrap_height = img_ex_height * 4
toImage = Image.new('RGBA', (wrap_width, wrap_height))
for x in range(5):
for y in range(4):
item = img_lis.pop(0)
fromImage = Image.open(os.getcwd()+'imgs'+item)
toImage.paste(fromImage, (x*img_ex_width, y*img_ex_height))
toImage.show()
toImage.save('code.font.exp1.tiff')
toImage.save('code.font.exp1.png')
os.system('tesseract code.font.exp1.png code.font.exp1 -l eng batch.nochop makebox')效果

运行jTessBoxEditor的bat文件,点击open,选择我们生成的tif文件,如下
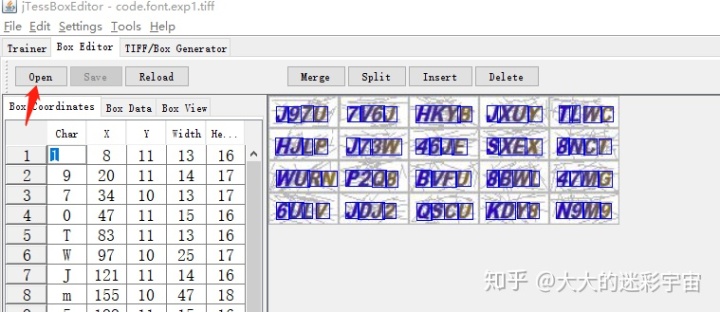
矫正过程很简单 就是调整框框的范围,然后修正左边对应字符的char, 手动矫正完如下,点击save
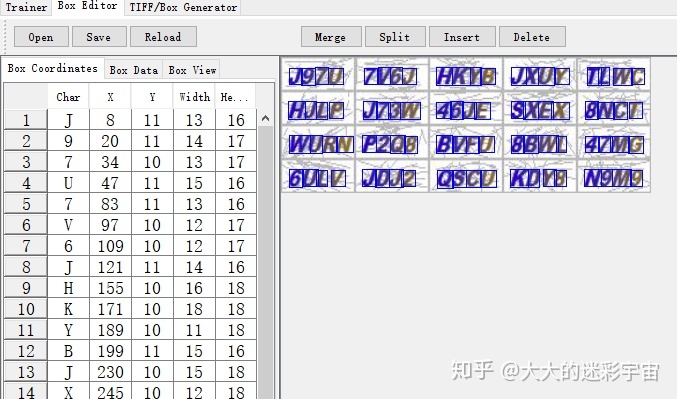
回到代码处,再跑一个脚本来生成一些文件
def traning_after():
# 写文件font_properties:
with open('font_properties', 'w') as f:
f.write('font 0 0 0 0 0')
# 生成文件
os.system('tesseract code.font.exp1.tiff code.font.exp1 nobatch box.train')
os.system('unicharset_extractor code.font.exp1.box')
os.system('mftraining -F font_properties -U unicharset code.font.exp1.tr')
os.system('cntraining code.font.exp1.tr')
rename_file(['unicharset','inttemp', 'pffmtable', 'shapetable', 'normproto'])
os.system('combine_tessdata font.')
这里一波生成文件有点多,看起来有点复杂,稍微来整理下整个过程
1 获取训练的图片, 样本当然是越多越好, 样本最好做成一张图片。这张图片根据命名规则命名
2 生成box文件
3 文字矫正,打开jTessBoxEditor工具进行处理
4 生成.tr训练文件
nobatch box.train
5 计算字符集,从生成的box文件中提取
unicharset_extractor
6 生成字体特征文件
font_properties
7 特征训练
mftraining
8 把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上字体名称
9 合并相关文件,生成字典文件
combine_tessdata
10 最终,在当前目录中会产生一个为font.traineddata文件,将其拷到tessdata文件夹中,再测试一下。尽管生成的文件很多,最重要的文件是只有2个文件,图片的源文件tiff和训练完以后的box文件,box记录了你矫正以后图像信息,不要轻易删掉。最后生成的font.traineddata就是我们要的训练集。我们来测试下,看看效果,测试图片为训练集处理以后的

先不用训练集测试
tesseract code.font.exp1.png result -l eng效果
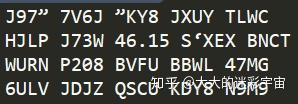
再来看看我们训练的
tesseract code.font.exp1.png result -l font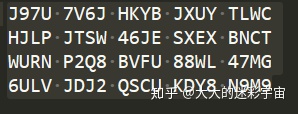
完美,等等,拿训练集来测试有点说不过去,我们来测试目标网上的,在这之前先下载
pip instll pytesseract这个库可以让我们指定语言识别图像字符串,因为 tesseract 只是一个命令行工具,并不能直接操作代码,接下来的代码过程分别是,
1 对验证码进行截图保存到本地
2 对本地的验证码图片进行灰度和二值化处理并保证
3 识别操作2保存的图片,指定我们训练的语言
4 将识别字符显示到对应的输入框代码如下
txtOldCheckCode = self.wait.until(EC.presence_of_element_located((By.ID, 'txtOldCheckCode')))
file = self.get_code_name() + '.png'
save_path = './{}'.format(file)
# 截图
ele = self.browser.find_element_by_id('checkcode')
ele.screenshot(save_path)
# 二值化灰度处理
self.img_handle(file)
# 识别
image = Image.open(file)
res = pytesseract.image_to_string(image,lang='font')
# 将识别结果放入输入框
txtOldCheckCode.clear()
txtOldCheckCode.send_keys(res)效果如下
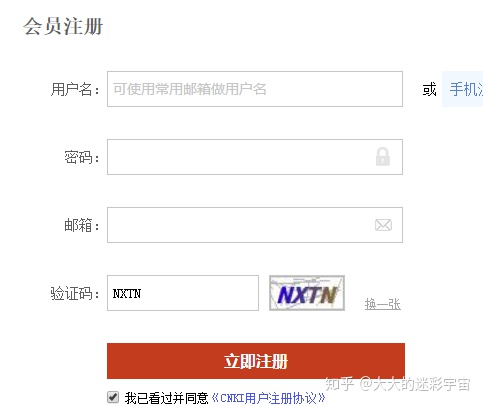
其实正确率还行,原因可能是我的训练集比较少,只有20个,尽管如此,比没训练集的时候好太多了。
以上请参考源代码
wuzhenbin/zhiwang-codegithub.com















 1171
1171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









