








文章发布于公号【数智物语】 (ID:decision_engine),关注公号不错过每一篇干货。
转自 | 数据团学社,微信搜索metrodata_xuexi 即可关注
本文约2400字,阅读需要7分钟
关键词:Python sklearn 决策树 KNN 逻辑回归 SVM
本文讲述了使用python分别构建决策树、KNN、逻辑回归、SVM、神经网络共五种不同的模型甄别淘宝优质店铺的过程。
目录
1. 背景知识介绍
2. 数据和工具准备
3. 模型介绍、代码示范和结果比较
4. 调参方法
5. 模型进阶:随机森林
▼
背景知识介绍
在经历数年双十一血拼,双十二剁手之后,作为一名优秀的数据分析师,我觉得我需要研究一下如何精准的定位优质店铺,看穿套路,理性消费。
今天的数据来自于阿里云天池。
这是一份包含2000家店铺的评分,等级,评论等信息和数年交易记录的数据。
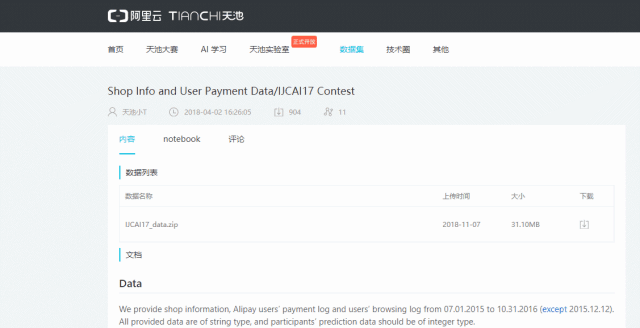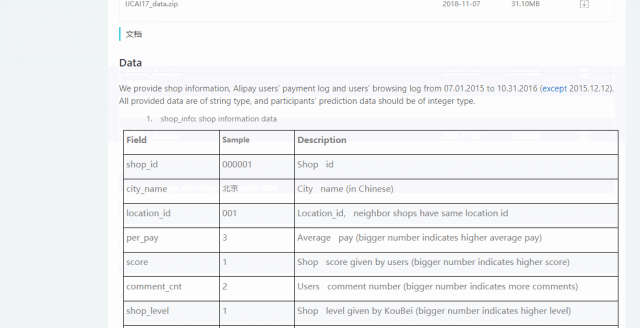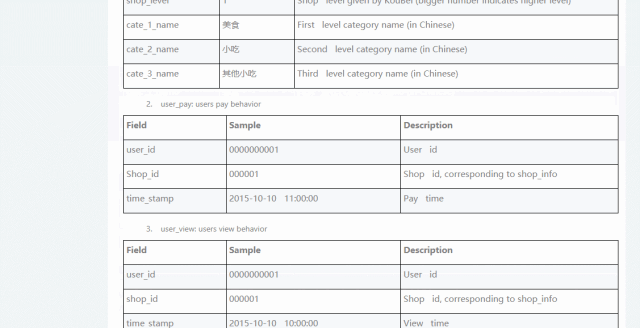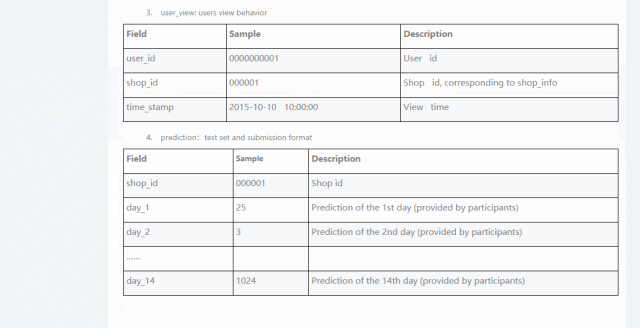
数据维度可以查看明细:
通过这份数据,我们可以构建一套选店模型,为即将到来的各种大小节日做准备。这个过程我们将使用sklearn包来完成。
我们要做的事情,就是构建模型,根据店铺的访问、购买信息等数据,来评测该店铺是否为优质店铺。一部分数据将用来作为训练集,另一部分数据会用来测试已经训练好模型的精确度。我们这里将重点关注模型的拟合情况,对每个模型进行调参比较,选出最适合的那一个~
欠拟合指模型没有很好地捕捉到数据特征,不能够很好地拟合数据:
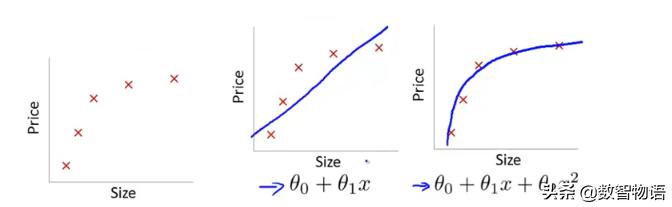
过拟合通俗一点地说就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差:
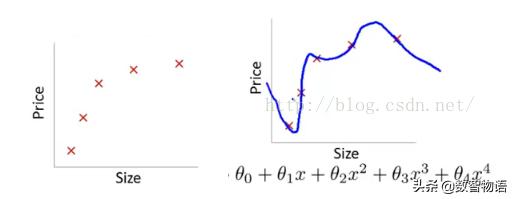
▼
数据和工具准备
一组数据到手,清理整合等预处理工作是绕不开的。我们可以得到了一份适合建模使用的样本数据:
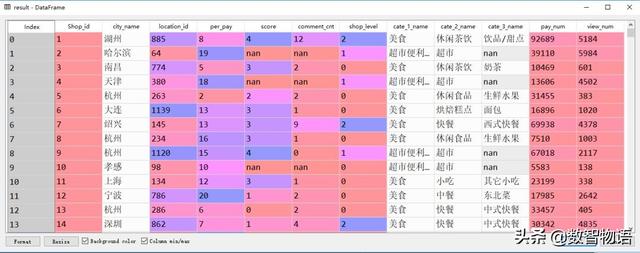
准备好数据以后,文末导入所需的包、填充数据空值,再拆分提取训练集和测试集数据,并将数据进行标准化,为后续的模型构建做足准备~
训练集(Training Set):帮助我们训练模型,简单的说就是通过训练集的数据让我们确定拟合曲线的参数。
验证集(Validation Set):用来做模型选择(model selection),即做模型的最终优化及确定的,用来辅助我们的模型的构建,可选。
测试集(Test Set):用来测试已经训练好的模型的精确度。
实际应用中,一般只将数据集分成两类,即训练集Training set 和测试集Test set。
既然数据都准备好了,那就开始我的表演~对于每个模型,我都会给出模型介绍和代码、简单的调参过程和查看模型结果的混淆矩阵。
*考虑这份数据比较粗糙,我们仅使用0分店铺和4分店铺的数据。
▼
不同模型的构建及其效果
模型一:决策树
#决策树max_depth_l = [2,3,4,5,6,7,8,9,10]for max_depth in max_depth_l: dt_model = DecisionTreeClassifier(max_depth=max_depth) dt_model.fit(x_train_scaled,y_train) train_accuracy = dt_model.score(x_train_scaled,y_train) test_accuracy = dt_model.score(x_test_scaled,y_test) print('max depth',max_depth) print('训练集上的准确率:{:2f}%'.format(train_accuracy*100)) print('测试集上的准确率:{:2f}%'.format(test_accuracy*100))决策树是一个类似于人们决策过程的树结构,从根节点开始,每个分枝代表一个新的决策事件,会生成两个或多个分枝,每个叶子代表一个最终判定所属的类别。
决策树,需要调节的主要参数是树的深度。深度越浅,容易造成欠拟合;而深度越深,则会过拟合。我们建立一个列表,罗列不同的深度,建立模型进行尝试,最终选择在测试集上表现最好的模型。
我们看到,随着深度的增加,模型在训练集上的准确率越来越高,而在测试集上的效果则越来越差,这是过拟合的表现,而在深度为5的时候,测试集的准确率为73.39,达到最高值,所以这组模型为决策树的最佳模型。

绘制混淆矩阵查看模型效果:
dt_model = DecisionTreeClassifier(max_depth=5)dt_model.fit(x_train_scaled,y_train)predictions = dt_model.predict(x_test_scaled)test_accuracy = dt_model.score(x_test_scaled,y_test)print(classification_report(y_test,predictions))print('决策树的准确率:{:2f}%'.format(test_accuracy*100))cnf_matrix = confusion_matrix(y_test,predictions)plot_confusion_matrix(cnf_matrix, classes=[0,1], )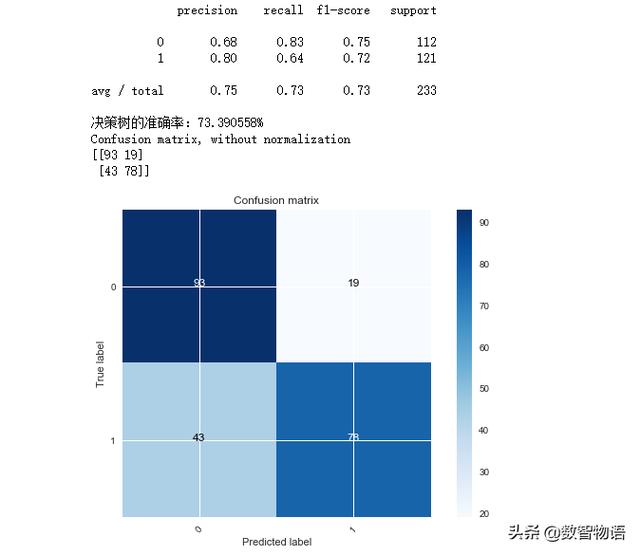
*横坐标是预测值,即“模型认为该店铺为差评/优质店铺”,纵坐标代表真实值,即“该店铺为差评/优质店铺”。0为差评,1为优质
模型在预测优质店铺上容易误杀,把优质店铺预测为差评店铺,错误达到43个,不过店铺茫茫多,错过这个还有下个,本着宁可错杀,不能放过的原则,模型还是可以的。
模型二:KNN
k_values = range(3,13)for k_value in k_values: knn_model = KNeighborsClassifier(n_neighbors=k_value) knn_model.fit(x_train_scaled,y_train) train_accuracy = knn_model.score(x_train_scaled,y_train) test_accuracy = knn_model.score(x_test_scaled,y_test) print('k value:',k_value) print('训练集上的准确率:{:2f}%'.format(train_accuracy*100)) print('测试集上的准确率:{:2f}%'.format(test_accuracy*100))K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法。 KNN算法的指导思想是“近朱者赤,近墨者黑”——由你的邻居来推断出你的类别。
KNN同样需要调节超参数,我们需要选取不同的邻近点个数,调试模型达到最优状态。

参数n_neighbors达到10的时候,效果最棒
knn_model = KNeighborsClassifier(n_neighbors=10)knn_model.fit(x_train_scaled,y_train)predictions = knn_model.predict(x_test_scaled)print(classification_report(y_test,predictions))accuracy = knn_model.score(x_test_scaled,y_test)print('KNN预测准确率:{:2f}%'.format(accuracy*100))cnf_matrix = confusion_matrix(y_test,predictions)plot_confusion_matrix(cnf_matrix, classes=[0,1], )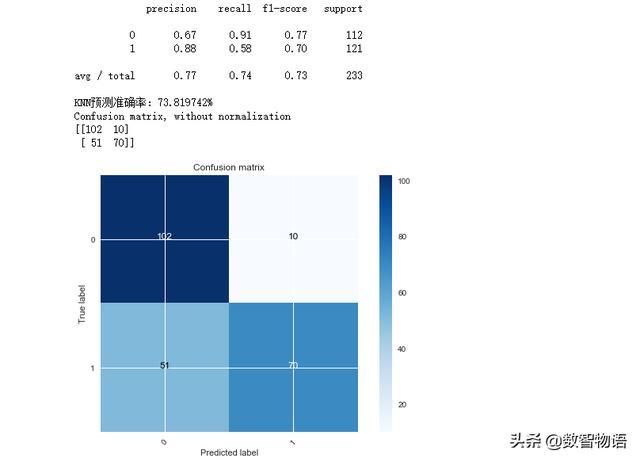
*横坐标是预测值,即“模型认为该店铺为差评/优质店铺”,纵坐标代表真实值,即“该店铺为差评/优质店铺”。0为差评,1为优质
模型在判断差评店铺方面效果比决策树更好,但错杀优质店铺的数量也达到51,好像多了一点。
模型三:逻辑回归
c_list = [0.01,0.1,1,1e1,1e2,1e3,1e4]for c in c_list: lg_model = LogisticRegression(C=c) lg_model.fit(x_train_scaled,y_train) train_accuracy = lg_model.score(x_train_scaled,y_train) test_accuracy = lg_model.score(x_test_scaled,y_test) print('C value:',c) print('训练集上的准确率:{:2f}%'.format(train_accuracy*100)) print('测试集上的准确率:{:2f}%'.format(test_accuracy*100))回归分析是一种预测建模技术的方法,研究因变量(目标)和自变量(预测器)之前的关系。逻辑回归是一种广泛应用于分类问题的回归方法。
逻辑回归是一种广义线性回归,原理是在线性回归的结果外套用sigmoid函数,
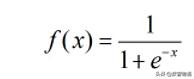
把输出结果压缩在0-1之间,如果结果>0.5,也就意味着概率大于一半,我们把它判定为1,反之为-1,从而起到分类的作用。
Sklearn的逻辑回归中,默认加入正则化超参数用于防止过拟合。可调节的参数是C,C越小、抵抗过拟合的力度越大;C越大则效果越小,我们也需要根据实际情况调节。
*参数中1e1,1e2……为科学计数法,表示10,100……以此类推

我们看到C在100的时候,效果就已经达到最优,而C越小模型的拟合程度越差,所以并不是任何情况,都需要使用过拟合调节。
lg_model = LogisticRegression(C=100)lg_model.fit(x_train_scaled,y_train)predictions = lg_model.predict(x_test_scaled)print(classification_report(y_test,predictions))accuracy = lg_model.score(x_test_scaled,y_test)print('逻辑回归预测准确率:{:2f}%'.format(accuracy*100))cnf_matrix = confusion_matrix(y_test,predictions)plot_confusion_matrix(cnf_matrix, classes=[0,1], )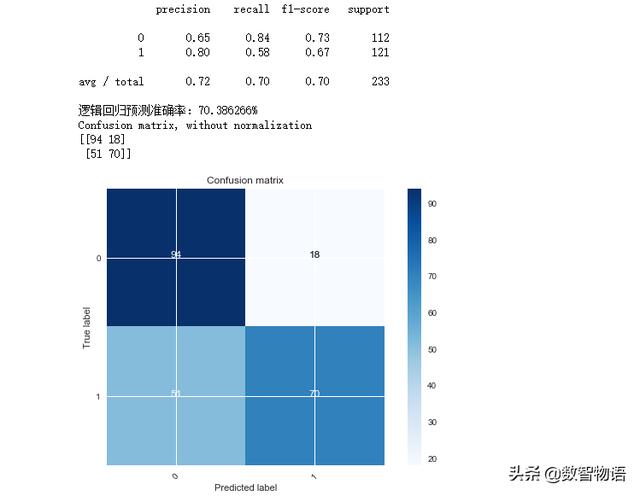
*横坐标是预测值,即“模型认为该店铺为差评/优质店铺”,纵坐标代表真实值,即“该店铺为差评/优质店铺”。0为差评,1为优质
预测准确率约为70.39%,效果相较于前两个模型要差一点。错杀还是51,也不少~
模型四:支持向量机
c_list = [1,1e1,1e2,1e3,1e4,1e5,1e6]for c in c_list: svm_model = SVC(C=c) svm_model.fit(x_train_scaled,y_train) train_accuracy = svm_model.score(x_train_scaled,y_train) test_accuracy = svm_model.score(x_test_scaled,y_test) print('C value:',c) print('训练集上的准确率:{:2f}%'.format(train_accuracy*100)) print('测试集上的准确率:{:2f}%'.format(test_accuracy*100))什么是SVM:支持向量机就是使用一条直线(二维)或超平面(多维)将数据分成两类,同时保证离超平面最近的点与超平面的间隔尽可能小。就像下图那样。
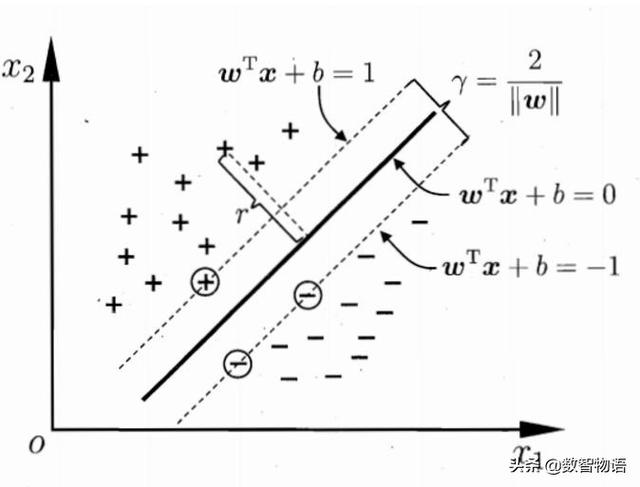
C为惩罚项,同样是为了防止过拟合。不同的C值可以有不同的结果:
svm_model = SVC(C=1e6)svm_model.fit(x_train_scaled,y_train)predictions = svm_model.predict(x_test_scaled)print(classification_report(y_test,predictions))accuracy = svm_model.score(x_test_scaled,y_test)print('支持向量机预测准确率:{:2f}%'.format(accuracy*100))cnf_matrix = confusion_matrix(y_test,predictions)plot_confusion_matrix(cnf_matrix, classes=[0,1], )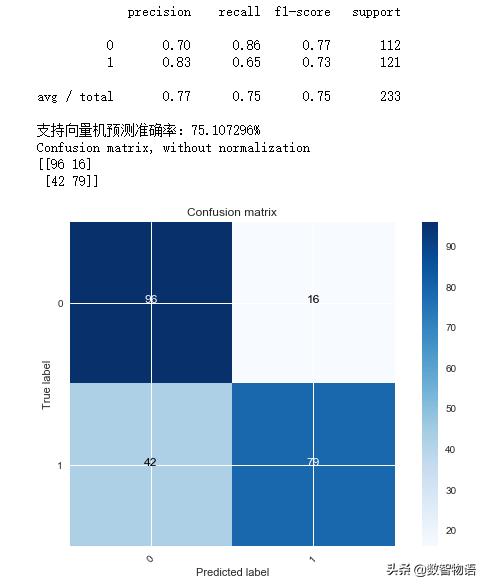
预测准确率为75.11%,是目前为止效果最好的模型了~
模型五:神经网络
mlp =MLPClassifier(hidden_layer_sizes=(100,50),max_iter=1000,activation='relu')mlp.fit(x_train_scaled,y_train)train_accuracy = mlp.score(x_train_scaled,y_train)test_accuracy = mlp.score(x_test_scaled,y_test) print('训练集上的准确率:{:2f}%'.format(train_accuracy*100))print('测试集上的准确率:{:2f}%'.format(test_accuracy*100))predictions = mlp.predict(x_test_scaled)cnf_matrix = confusion_matrix(y_test,predictions)plot_confusion_matrix(cnf_matrix, classes=[0,1], )*这个原理比较复杂,文末提供了参考资料供大家阅读~
使用sklearn中BP神经网络的包,建立神经网络模型进行预测,我们可以调节的超参数有神经网络隐藏层的层数,激活函数等。
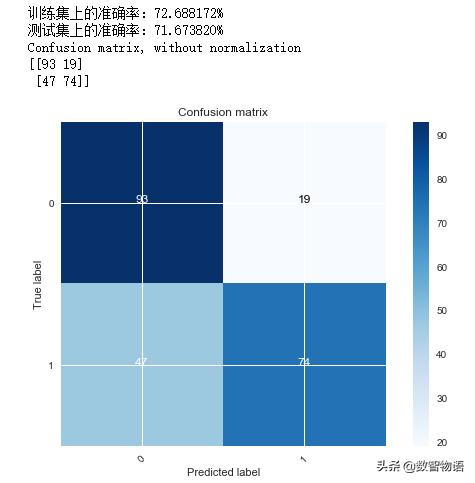
预测准确率为71.67%,结果一般般吧~
我们用了这么多模型,我相信有同学一定会问,每个模型都有一种甚至数种超参数需要调节,那么哪种排列组合是最佳组合呢?
呵呵~~~这个问题难度有点高哦!如果我说每次都是蒙的,你会信吗?
▼
如何调节超参数
对于模型的超参数调节,并没有固定的套路,通常需要经过数轮尝试和以往的经验才能找到最正确的那个。当然,每次手动调节也确实是一件挺麻烦的事,所以,这里分享一个一劳永逸的方法——网格搜索,交叉验证。
原理很简单,我们把测试集再分成数份作为验证集。比如分成10份,我们叫10折,然后选取一组参数,分别在每个折上进行运行,得到10个结果,求出平均结果作为这一组最后的结果,最后得到最优结果的那一组参数。
好!下面我们来看下具体代码实现过程。
首先建立一个字典,字典里包含我们需要比较的模型,和每个模型中参数的选取范围。
model_dict = { 'Decision Tree':(DecisionTreeClassifier(), {'max_depth':[2,3,4,5,6,7,8,9,10],} ), 'KNN':(KNeighborsClassifier(), {'n_neighbors':list(range(1,21)), 'p':[1,2],} ), 'Logistic Regression':(LogisticRegression(), {'C':[1,1e1,1e2,1e3,1e4,1e5,1e6],} ), 'SVM':(SVC(), {'C':[1,1e1,1e2,1e3,1e4,1e5,1e6],} ), 'MLP':(MLPClassifier(), {'hidden_layer_sizes':[(100,50),(100,30),(100,50,30),(100,100)], 'max_iter':[200,500,1000,5000,10000], 'activation':['relu','logistic','tanh'] } ), }然后我们使用GridSearchCV,遍历参数,并排列组合,然后再进行交叉验证,选取最佳参数组合。我们采用5折对训练集进行划分:
for model_name,(model,model_params) in model_dict.items(): clf = GridSearchCV(estimator=model,param_grid=model_params,cv=5) clf.fit(x_train_scaled,y_train) best_model = clf.best_estimator_ acc = best_model.score(x_test_scaled,y_test) print('{}模型预测准确率:{:2f}%'.format(model_name,acc*100)) print('{}模型最佳参数:{}'.format(model_name,clf.best_params_))
因为经过了验证集进一步的验证,最后的结果有所变化,神经网络模型的结果为最优结果,并且这里罗列了每个模型的最佳参数组合。
我们使用了5种模型,并通过反复调节,正确率达到了74.3%,显然,这并不是一个十分满意的结果。那么是否还有其他更强大的模型,可以再进一步提升呢?
▼
更强大的模型:随机森林
既然任何的一种模型都达不到要求,那么我们就用许多模型,把他们组合在一起,这叫强强联手。对于这类把许多模型组合在一起,成为一个整体的模型我们称之为集成模型。
下面,我使用一种集成模型——随机森林来进一步探索数据。主要原理是构建多棵决策树,每棵决策树都会有一个结果,最后通过投票机制,选出最终结果。
from sklearn.ensemble import RandomForestClassifiertree_param_grid = {'n_estimators':[10,20,30,50,80], 'min_samples_split':[2,8,10,20,30,50,60,70,80], 'min_samples_leaf':[2,5,10,20,30,50], 'random_state':[2] }grid = GridSearchCV(RandomForestClassifier(),param_grid=tree_param_grid,cv=5)grid.fit(x_train_scaled,y_train)best_model = grid.best_estimator_acc1 = best_model.score(x_train_scaled,y_train)acc2 = best_model.score(x_test_scaled,y_test)print('随机森林模型训练准确率:{:2f}%'.format(acc1*100))print('随机森林模型预测准确率:{:2f}%'.format(acc2*100))print('随机森林模型最佳参数:{}'.format(grid.best_params_))同样采用交叉验证来调节参数。特别注意的是random_state参数,一定要限定一下随机数种子,否则每次运行模型,采用的是不同的随机数,呈现的结果不同,就无法对比了。
随机森林模型训练准确率:76.559140%随机森林模型预测准确率:78.111588%随机森林模型最佳参数:{'min_samples_leaf': 2, 'min_samples_split': 70, 'n_estimators': 50, 'random_state': 2}从结果上看,有了比较明显的提升,在预测集上达到了78.11%的准确率,对比前面的模型有了较大的提升。
集成模型有很多种,每一种都尝试下,最终的准确率应该可以达到80%。但是,相比起模型,数据更为重要。受限于数据量,数据精度和数据维度,模型离愿望中的90%准确性还有很大的距离。如果有更大的样本,比如2W条数据,更精细的分类,比如score精确到小数点后一位4.0,4.1,4.2……和更多的字段,比如成交金额,成交数量,店铺年份等等,那么模型一定会更精确。
毕竟模型不是魔法,我们讨论的也只是科学而不是玄学。最后,最重要的不是买买买,学到模型才是正事,再来了解下跟模型相关的算法吧。
















 4255
4255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









