






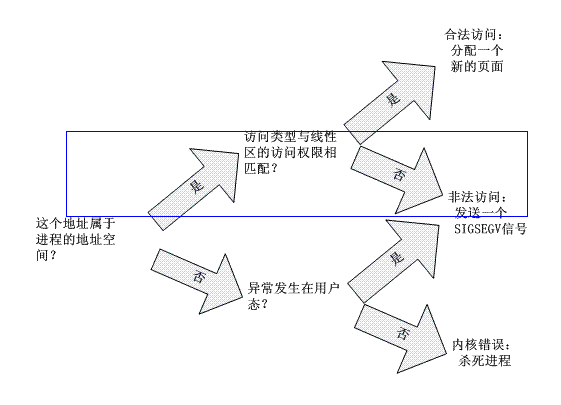
应用层非法访问地址空间的结果和途径
地址空间访问的结果分为三种:
分配一个新的页面。
发送SIGSEGV信号给对应进程。
内核错误杀死进程。
如图所示:
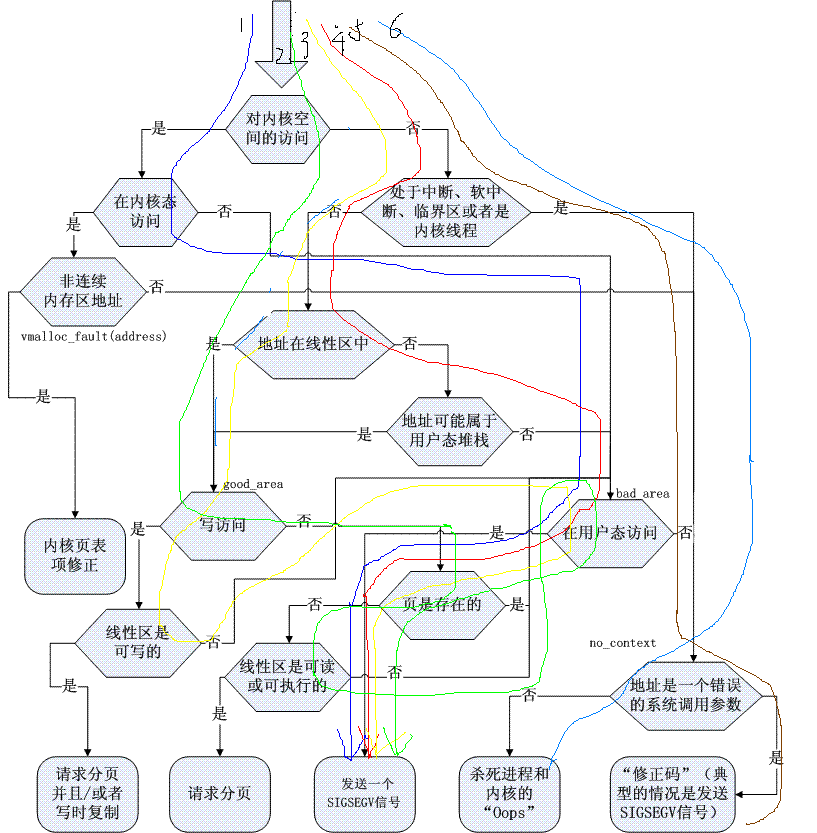
应用程序访问地址的路径,有五种:
应用程序非法访问了内核态地址.
应用程序读取了读保护的线性区地址.
应用程序写入了写保护的线性区地址.
应用程序访问了不存在的用户虚拟地址.
应用程序系统调用参数错误.
如何尽可能捕捉异常打印
内核配置CONFIG_DEBUG_USER
全局变量user_debug
以下是打印具体信号量的code代码行。
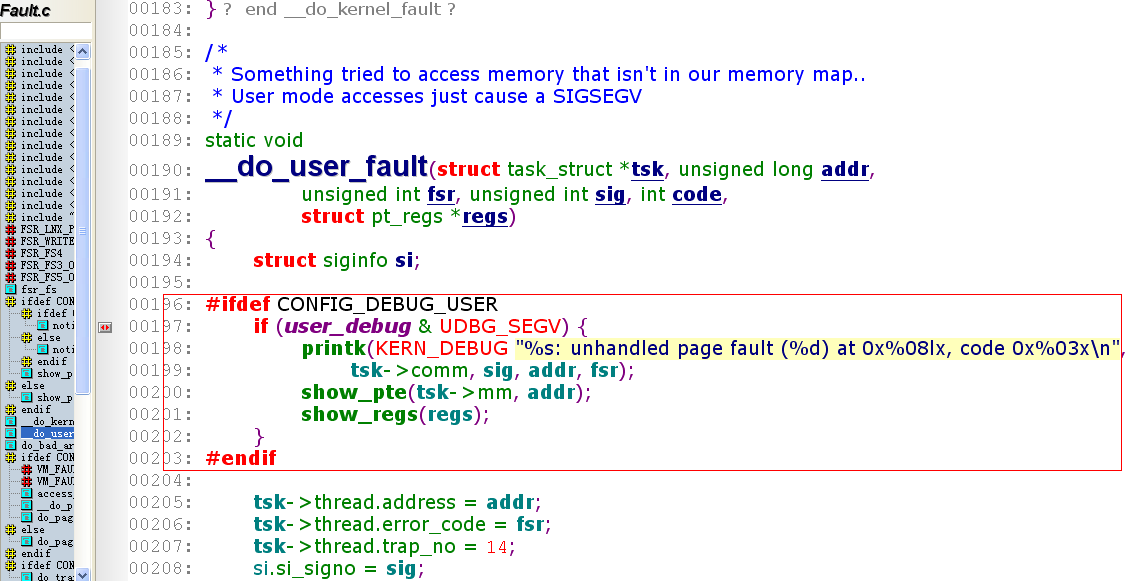
方式1: 修改内核源码
方式2: 修改U-boot的bootargs参数
解析uboot参数的代码如下所示:
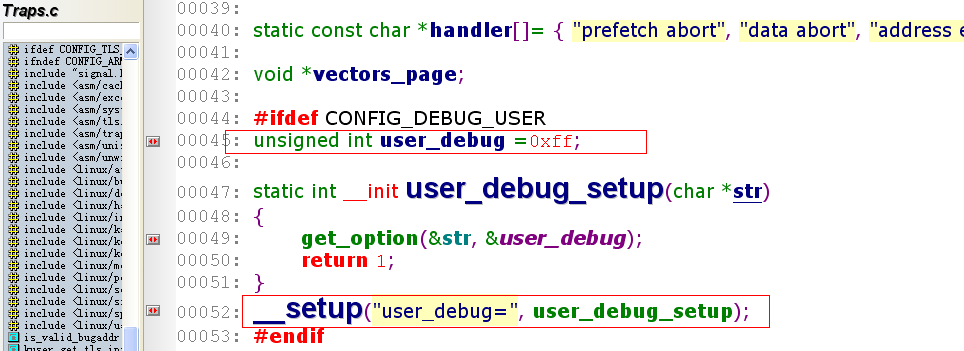
全局变量print_fatal_signals
print_fatal_signals的作用点如下所示:
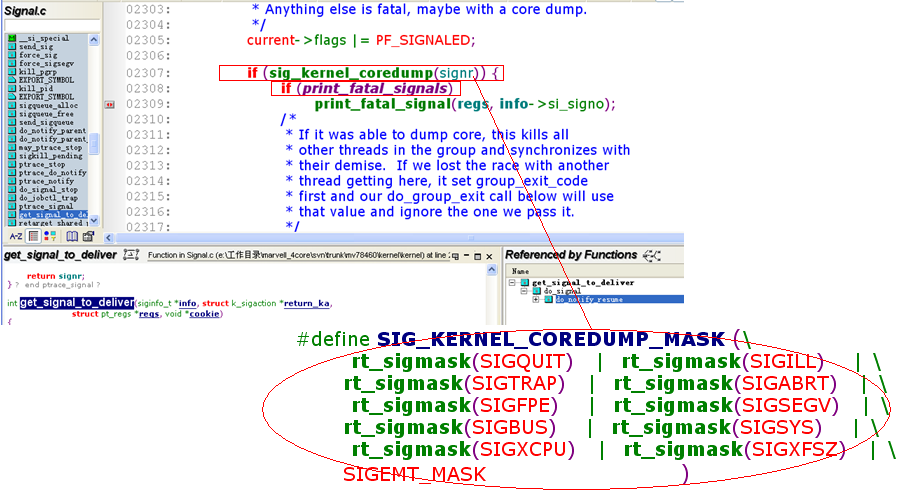
print_fatal_signals的赋值方式同样有两种:
方式1: 修改内核源码
方式2: 修改U-boot的bootargs参数
以下是内核解析print_fatal_signals的相关代码行:

异常信息定位
根据signal num判断错误原因。
获取到进程的虚拟地址空间(/proc/pid/maps),根据内核dump的pc地址进行定位。
使用gdb、objdump进行反汇编辅助定位。
实例1 非法访问导致的SIGSEGV 11信号
实验代码如下所示:
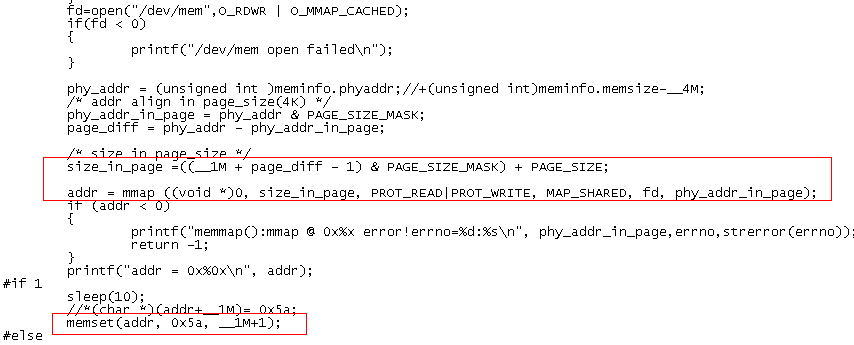
在上面代码中,我们对预留的物理地址进行了映射;
但在访问时,出现了越界,即非法的地址访问。
由于打开了debug user,于是出现了以下打印:
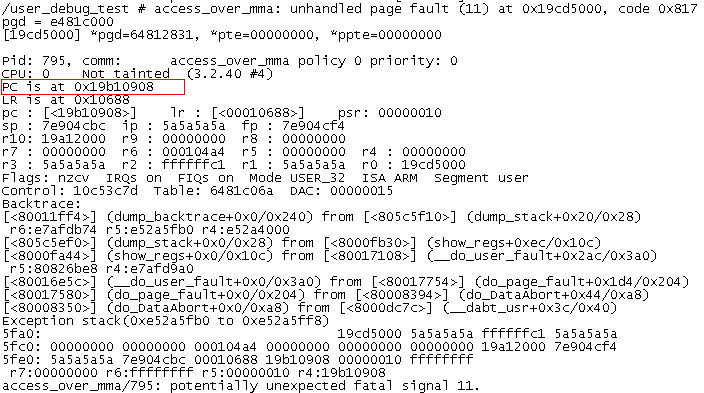
从上面打印可以知道,出现问题时,
触发的信号为signal 11.我们来回顾下之前所描述的,即SIGSEGV:

另外,PC指针在地址0x19b10908,
而这个地址是属于哪里的呢?我们可以通过/proc/pid/maps一探究竟(pid在打印中有显示,为795)
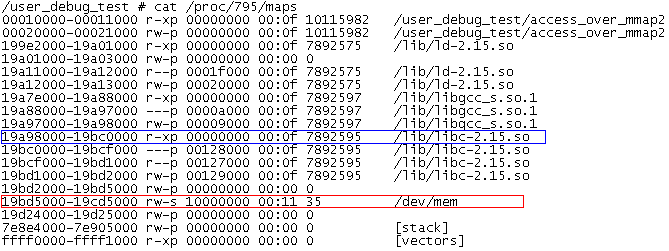
原来出错代码在libc-2.15库对应代码段的偏移
!Offset = 0x19b10908 – 0x19a98000 = 0x78908
而/dev/mem的地址空间在19bd5000-19cd5000,
这显然不是操作预留重映射的地址空间了。
接下来进行反汇编查看,看下glibc中地址偏移为0x78908究竟作了什么操作,
arm-marvell-linux-gnueabi-objdump -S libc-2.15.so > libc-2.15.asm

该句汇编的意思是,取r1地址上的数据放到[r0]+1的地址上。
实际上,78908偏移上的内容无所谓,
我们知道这个地址在glibc中就可以确认:应用层的确出现了异常内存访问。
实例2
代码如下所示:
#include
#define __1M 1024*1024
#define __16K 0x4000
void main(void)
{
void * ptr;
ptr=malloc(__1M);
printf("alloc virtual addr is 0x%0x\n", ptr);
memset(ptr, 0x5a, __1M+4);
while(1);
return 0;
}
示例代码malloc申请了1M的内存,但是,使用时,多访问了4个字节。
运行结果:
/user_debug_test # ./out_of_range2 &
/user_debug_test # alloc virtual addr is 0x19bbe008
/user_debug_test #
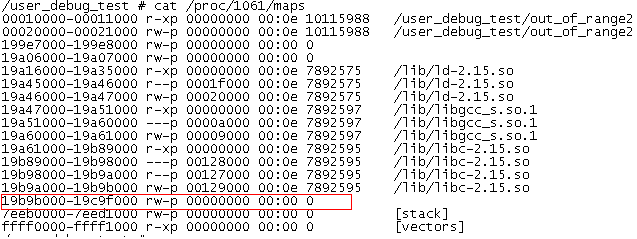
从图中可以确认堆大小为 0x19c9f000-0x19b9b000=0x104000,
而0x19bbe008属于该段地址。
因此即使是多访问了4个字节,也是不会报错的。
实例3 SIGFPE信号8错误

实例4用户空间访问异常地址导致的SIGSEGV 错误
我们用同样的方法来看另一个问题,代码如下所示:

如上所示,用户空间线程访问了0地址(不该访问的内核空间),导致奔溃。
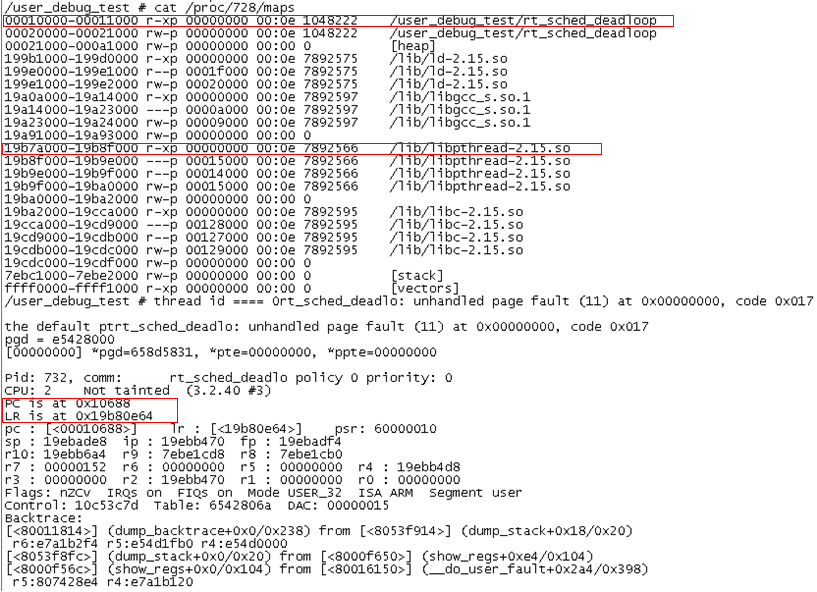
PC地址0x10688在我们示例的代码段中,
而LR地址0x19b80e64在pthread库代码中。
使用反汇编也能证明这点。

总结
首先,内核需要打开相关的选项;然后,根据PC和LR地址,
结合出错pid的maps以及出错的信号,定位出错点。
现在kernel默认没有了USER_DUBUG选项,所以不用在打开
但是要打开如下开关
/proc/sys/kernel/print-fatal-signals
ulimit -c x
objdump汇编出源码查看即可
文档信息
--------------
* 版权声明:自由转载-非商用
* 转载: [最常见的Linux用户程序异常----Segment Fault]















 2717
2717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









