






最近在学习的过程中,遇到了Segment fault(段错误)的问题,经过一番查找资料,学到了一些相关知识,这里做一个梳理,以防以后在遇到类似的问题,并且希望能够帮助到大家一丝丝!
什么是Segment fault?
在操作系统中,内存被划分为多个段(Segments),每个段存储着不同类型的数据,如代码段、数据段等。Segmentation Fault(段错误)是一种常见的程序错误,它通常发生在程序试图访问无效的内存地址或未初始化的内存区域,或者指针操作不当、数组越界、动态内存分配问题等原因造成的。这种错误通常由于程序编写错误或指针使用不当导致。当程序执行过程中发生Segmentation Fault错误时,操作系统会向程序发送一个SIGSEGV信号,导致程序停止运行。
Segmentation Fault的常见原因
- 指针操作不当:当指针未初始化、指向无效地址或已释放的内存时,程序会尝试访问这些地址,导致
Segmentation Fault错误,非法指针:使用空指针,或者随意使用指针转换。一个指向一段内存的指针,除非确定这段内存原先就分配为某种结构或类型,或者这种结构或类型的数组,否则不要将它转换为这种结构或类型的指针,而应该将这段内存拷贝到一个这种结构或类型中,再访问这个结构或类型。这是因为如果这段内存的开始地址不是按照这种结构或类型对齐的,那么访问它时就很容易因为bus error而core dump。。 - 数组越界:程序在访问数组时,如果索引超出数组的实际范围,将会访问到无效的内存区域,从而引发
Segmentation Fault。 - 动态内存分配问题:在使用动态内存分配函数(如malloc、new等)时,如果分配的内存未初始化或已释放,程序仍然尝试访问这些内存,同样会导致
Segmentation Fault。 - 堆栈溢出.不要使用大的局部变量(因为局部变量都分配在栈上),这样容易造成堆栈溢出,破坏系统的栈和堆结构,导致出现莫名其妙的错误。
如何解决Segmentation Fault错误。
实际上,我们可以通过仔细检查代码去逐一排查错误发生点,但是面对一个庞大的项目,涉及到的内容很多的时候,我们一一排查就会很吃力,有时候也是徒劳的。这时,我们就可以借助一些调试工具,来检查错误的位置。
下面来讲一下,在Linux系统中,如何借助gdb查看core文件来定位错误!
什么是core文件?
在Linux系统下,当程序不寻常退出时,内核会在当前工作目录下生成一个core文件(是一个内存映像,同时加上调试信息,编译时需要加上 -g -Wall)。我们使用gdb来查看core文件,可以指示出导致程序出错的代码所在文件和行数。
如何生成core文件和大小限制
当系统程序运行产生 Segmentation Fault 而不是显示Segmentation fault (core dumped) 这说明,并没有产生code文件,我们需要执行以下命令来生成code文件,并限制文件大小。
- 使用
ulimit -c命令查看core文件的生成开关,如果结果为 0,则表示关闭了此功能,不会生成core文件。 - 使用
ulimit -c filesize命令,可以限制core文件的大小(filesize的单位为kbyte)。 - 但是如果生成的信息超过我们限制的文件大小,信息将会被裁剪,最终生成一个不完整的core文件或者根本就不生成,同时在调试此core文件的时候,gdb也会提示错误。所以我们常使用
ulimit -c unlimited来表示core文件的大小不受限制。 - 执行
ulimit -a察看当前系统设置
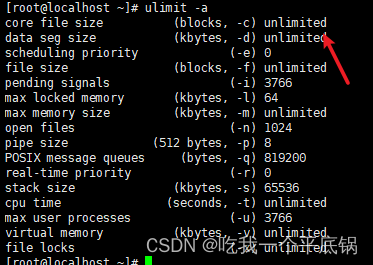
注意:,这只对一个终端有效,再打开一个终端就无效了,要想整体修改,我们需要在系统 /etc/profile文件的最后,添加以下一行:
ulimit -c unlimited
然后,执行以下命令,使其生效:
source /etc/profile
这时候我们再次运行程序,就会发现Segmentation fault (core dumped),说明已经生成了code文件,但是它在哪呢?
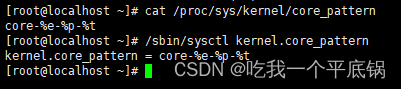
查询core dump文件路径,可以通过以下命令查询:
cat /proc/sys/kernel/core_pattern
或者
/sbin/sysctl kernel.core_pattern
core文件的名称: core文件生成路径:输入可执行文件运行命令的同一路径下。若系统生成的core文件不带其它任何扩展名称,则全部命名为core。新的core文件生成将覆盖原来的core文件。
/proc/sys/kernel/core_uses_pid可以控制core文件的文件名中是否添加pid作为扩展。
文件内容为1,表示添加pid作为扩展名,生成的core文件格式为core.xxxx;为0则表示生成的core文件同一命名为core。
可通过以下命令修改此文件:
echo "1" > /proc/sys/kernel/core_uses_pid
修改core文件保存位置和文件名格:
修改/proc/sys/kernel/core_pattern, 可通过以下命令修改此文件:
echo "/corefile/core-%e-%p-%t" > core_pattern
可以将core文件统一生成到/corefile目录(必须保证有这个目录)下,也可以自己指定生成路径,产生的文件名为core-命令名-pid-时间戳,以下是参数列表:
%p - insert pid into filename 添加pid
%u - insert current uid into filename 添加当前uid
%g - insert current gid into filename 添加当前gid
%s - insert signal that caused the coredump into the filename 添加导致产生core的信号
%t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间
%h - insert hostname where the coredump happened into filename 添加主机名
%e - insert coredumping executable name into filename 添加命令名
注意:
- 目录proc文件系统是一个伪文件系统,以文件系统的方式为访问系统内核数据的操作提供接口。/proc目录的内容为系统启动时自动生成的,某写文件可改,某写文件不可改。比如可以通过修改proc的文件微调内核参数。使用vi可能无法成功编辑
proc/sys/kernel/core_pattern,只能使用echo命令修改或者命令sysctl修改。sysctl命令如下:
sysctl -w "kernel.core_pattern=$core_dir/core_%e_%t" >/dev/null
sysctl -w "kernel.core_uses_pid=0" >/dev/null
此时,我们就产生了code文件

如何利用code文件进行调试呢?
- 安装gdb
yum install -y gdb.x86_64
- gdb进行查看core文件的内容, 以定位文件中引发core dump的行,gdb格式如下:
gdb [exec file] [core file]
[exec file]表示之前使用gcc编译的程序
[core file]表示之前产生的dump文件 - 基本GDB命令
启动程序:run
设置断点:b 行号|函数名
删除断点:delete 断点编号
禁用断点:disable 断点编号
启用断点:enable 断点编号
单步跟踪:next (简写 n)
单步跟踪:step (简写 s)
打印变量:print 变量名字 (简写p)
设置变量:set var=value
查看变量类型:ptype var
顺序执行到结束:cont
顺序执行到某一行: util lineno
打印堆栈信息:bt - 切记:要在编译时,加上-g选项
举个栗子吧~
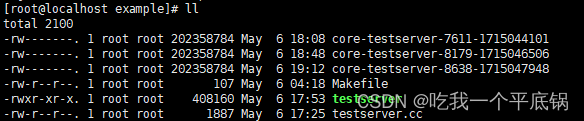
这里我们看到我们的code文件,接下来,使用以下命令,进行调试:

产生了以下结果: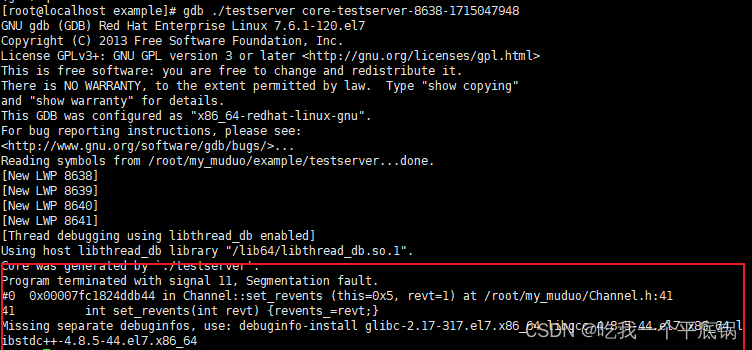
这里就会知道我们出现错误的位置。
新的问题又来了,我们从上图可以看出,缺少缺失独立的调试信息,该怎么办呢?
何为“独立的调试信息”?如果编写代码后使用gcc编译器进行编译时,若不加上-g编译参数,或后期使用strip工具进行二次处理,生成的二进制文件中将不带调试段信息,而gdb的调试都是基于该调试段进行的,在linux世界这部分内容往往也被称作debuginfo。
其次,各大发行版提供的二进制软件包为了缩小体积,且用户往往不需要对软件(包括内核、libc这类基础设施)本身进行调试,因此往往不带调试信息。由于在Linux环境下绝大部分程序都依赖于libc(包括最简单的hello world),若系统预装的libc未带调试段信息,将影响gdb对目标程序进行调试操作。
该如何解决呢?
- 首先,执行以下命令
vim /etc/yum.repos.d/CentOS-Debuginfo.repo
将enable改为1

- 安装glibc
yum install glibc
yum install yum-utils
debuginfo-install glibc-2.17-326.el7_9.x86_64 libgcc-4.8.5-44.el7.x86_64 libstdc++-4.8.5-44.el7.x86_64
实际上,最后一句命令就是图片中提示的。

再次使用gdb,就发现不会提示Missing separate debuginfos, u.....啦~
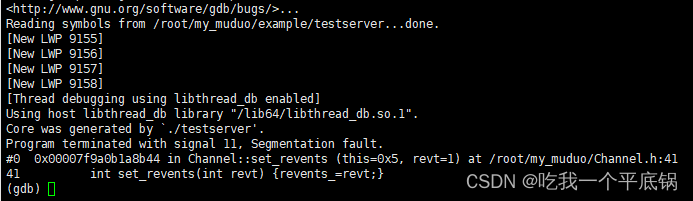
通过where,我们可以看一些具体的细节:
















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









