






昨天的文章《将WORD简历数据汇总到Excel,用Power Query竟然这么简单?》里提到,有的word文档因为是一些从网络下载的格式化文档,本身带了html的标记,所以可以直接用Web.Page函数来进行解析。
但大多数普通的word文档,是不能直接用Web.Page函数来解析的,一般需要另存为html文件,才能用Power Query来读取。
实际上,这——

因为,Power Query实在太强大,完全可以直接将普通的word文件通过二进制数据的方式读取后给(替换)加上html标记,然后通过Web.Page函数来读取!
也就是说——
普通Word文档的表格
也能用PQ直接读!!!
不过,这个过程比较复杂,对于我等普通的用户来说,只要学会抱大腿就行了(本文核心代码参考pqfans文章https://pqfans.com/2447.html)。

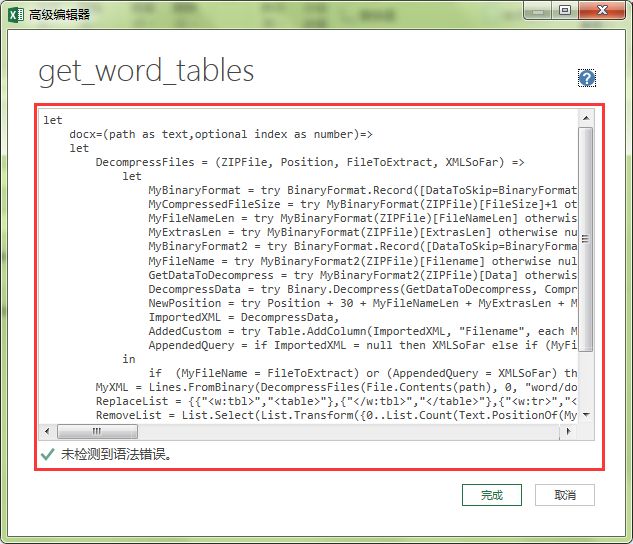
将下面的代码复制到高级编辑器里:
let docx=(path as text,optional index as number)=> let DecompressFiles = (ZIPFile, Position, FileToExtract, XMLSoFar) => let MyBinaryFormat = try BinaryFormat.Record([DataToSkip=BinaryFormat.Binary(Position),MiscHeader=BinaryFormat.Binary(18),FileSize=BinaryFormat.ByteOrder(BinaryFormat.UnsignedInteger32, ByteOrder.LittleEndian),UnCompressedFileSize=BinaryFormat.Binary(4),FileNameLen=BinaryFormat.ByteOrder(BinaryFormat.UnsignedInteger16, ByteOrder.LittleEndian),ExtrasLen=BinaryFormat.ByteOrder(BinaryFormat.UnsignedInteger16,ByteOrder.LittleEndian),TheRest=BinaryFormat.Binary()]) otherwise null, MyCompressedFileSize = try MyBinaryFormat(ZIPFile)[FileSize]+1 otherwise null, MyFileNameLen = try MyBinaryFormat(ZIPFile)[FileNameLen] otherwise null, MyExtrasLen = try MyBinaryFormat(ZIPFile)[ExtrasLen] otherwise null, MyBinaryFormat2 = try BinaryFormat.Record([DataToSkip=BinaryFormat.Binary(Position), Header=BinaryFormat.Binary(30), Filename=BinaryFormat.Text(MyFileNameLen), Extras=BinaryFormat.Binary(MyExtrasLen), Data=BinaryFormat.Binary(MyCompressedFileSize), TheRest=BinaryFormat.Binary()]) otherwise null, MyFileName = try MyBinaryFormat2(ZIPFile)[Filename] otherwise null, GetDataToDecompress = try MyBinaryFormat2(ZIPFile)[Data] otherwise null, DecompressData = try Binary.Decompress(GetDataToDecompress, Compression.Deflate) otherwise null, NewPosition = try Position + 30 + MyFileNameLen + MyExtrasLen + MyCompressedFileSize - 1 otherwise null, ImportedXML = DecompressData, AddedCustom = try Table.AddColumn(ImportedXML, "Filename", each MyFileName) otherwise ImportedXML, AppendedQuery = if ImportedXML = null then XMLSoFar else if (MyFileName = FileToExtract) then AddedCustom else if (FileToExtract = "") and Position <> 0 then Table.Combine({AddedCustom, XMLSoFar}) else AddedCustom in if (MyFileName = FileToExtract) or (AppendedQuery = XMLSoFar) then AppendedQuery else @DecompressFiles(ZIPFile, NewPosition, FileToExtract, AppendedQuery), MyXML = Lines.FromBinary(DecompressFiles(File.Contents(path), 0, "word/document.xml", "")){1}, ReplaceList = {{"",""},{"",""},{"",""},{"",""},{""," RemoveList = List.Select(List.Transform({0..List.Count(Text.PositionOf(MyXML,",2))-1},each "&Text.BetweenDelimiters(MyXML,",">",_)&">"),each not List.Contains(List.Zip(ReplaceList){0},_)), Result = List.RemoveLastN(Web.Page(List.Accumulate(List.Transform(RemoveList,each {_}&{""})&ReplaceList,MyXML,(s,c)=>Text.Replace(s,c{0},c{1})))[Data]) in try Result{index-1} otherwise Resultin docx
完成后马上得到一个自定义函数:
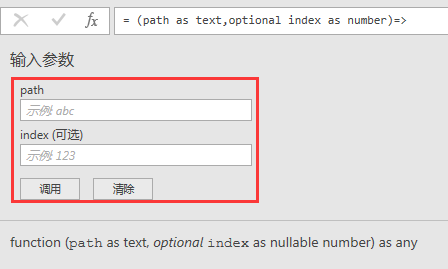
这个时候,只要将word文档的路径深入到函数的path参数即可。而对于index表示要返回的是word里的第几个表,比如填1就返回第1个,如果不填,则返回全部表。
如下读取示例word文件中的多个表格:
将路径信息(也可以按前面文章所提按文件夹导入,然后筛选出docx格式文档,然后通过上面生成的自定义函数来直接解析)填入path参数中,index参数留空:
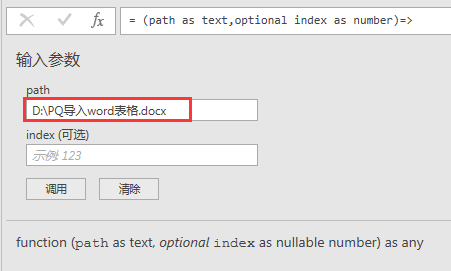
稍等一会儿,显然,word文件中的表被识别出来了:
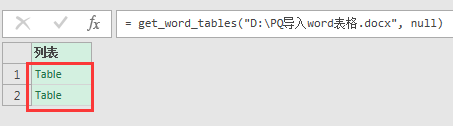
深化(点击)其中第一个表(Table),将得到结果如下:
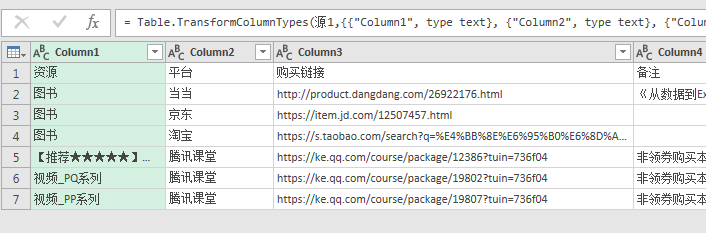
至此,word中表格的数据读取完毕,其中没有借助任何的其他工具或对文件进行任何改动!!!
实在是——

Power新书榜第1 | 最适合入门打基础
当当京东超低折扣进行中
- 最通俗易懂Power系列视频 -
购书领60元视频券 or 直购视频送签名书

点“阅读原文”看视频
更易理解,学得更快
本文配套材料下载
(按文章发布日期确定对应文件)
https://share.weiyun.com/5YKFr4Z
点亮“在看”,
向大神们致敬!














 4652
4652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









