






缓存命中率的介绍
命中:可以直接通过缓存获取到需要的数据。
不命中:无法直接通过缓存获取到想要的数据,需要再次查询数据库或者执行其它的操作。原因可能是由于缓存中根本不存在,或者缓存已经过期。
通常来讲,缓存的命中率越高则表示使用缓存的收益越高,应用的性能越好(响应时间越短、吞吐量越高),抗并发的能力越强。
由此可见,在高并发的互联网系统中,缓存的命中率是至关重要的指标。
如何监控缓存的命中率
如果想学习Java工程化、高性能及分布式、深入浅出。微服务、Spring,MyBatis,Netty源码分析的朋友可以加我的Java高级交流:787707172,群里有阿里大牛直播讲解技术,以及Java大型互联网技术的视频免费分享给大家。
在memcached中,运行state命令可以查看memcached服务的状态信息,其中cmd_get表示总的get次数,get_hits表示get的总命中次数,命中率 = get_hits/cmd_get。
当然,我们也可以通过一些开源的第三方工具对整个memcached集群进行监控,显示会更直观。比较典型的包括:zabbix、MemAdmin等。
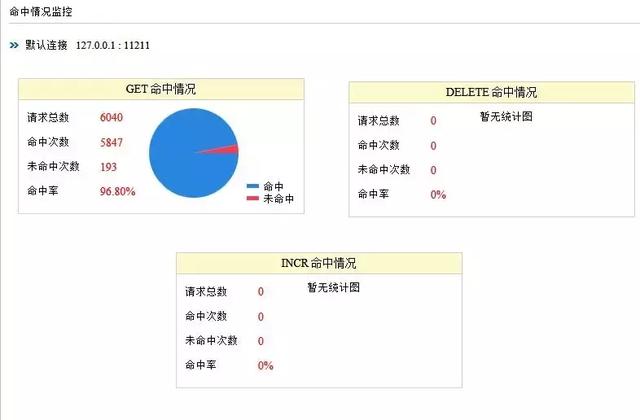
如图:MemAdmin对memcached服务的命中率情况的监控统计
同理,在redis中可以运行info命令查看redis服务的状态信息,其中keyspace_hits为总的命中中次数,keyspace_misses为总的miss次数,命中率=keyspace_hits/(keyspace_hits+keyspace_misses)。
开源工具Redis-star能以图表方式直观redis服务相关信息,同时,zabbix也提供了相关的插件对redis服务进行监控。
影响缓存命中率的几个因素
之前的章节中我们提到了缓存命中率的重要性,下面分析下影响缓存命中率的几个因素。
业务场景和业务需求
缓存适合“读多写少”的业务场景,反之,使用缓存的意义其实并不大,命中率会很低。
业务需求决定了对时效性的要求,直接影响到缓存的过期时间和更新策略。时效性要求越低,就越适合缓存。在相同key和相同请求数的情况下,缓存时间越长,命中率会越高。
互联网应用的大多数业务场景下都是很适合使用缓存的。
缓存的设计(粒度和策略)
通常情况下,缓存的粒度越小,命中率会越高。举个实际的例子说明:
当缓存单个对象的时候(例如:单个用户信息),只有当该对象对应的数据发生变化时,我们才需要更新缓存或者让移除缓存。而当缓存一个集合的时候(例如:所有用户数据),其中任何一个对象对应的数据发生变化时,都需要更新或移除缓存。
还有另一种情况,假设其他地方也需要获取该对象对应的数据时(比如其他地方也需要获取单个用户信息),如果缓存的是单个对象,则可以直接命中缓存,反之,则无法直接命中。这样更加灵活,缓存命中率会更高。
此外,缓存的更新/过期策略也直接影响到缓存的命中率。当数据发生变化时,直接更新缓存的值会比移除缓存(或者让缓存过期)的命中率更高,当然,系统复杂度也会更高。
缓存容量和基础设施
缓存的容量有限,则容易引起缓存失效和被淘汰(目前多数的缓存框架或中间件都采用了LRU算法)。同时,缓存的技术选型也是至关重要的,比如采用应用内置的本地缓存就比较容易出现单机瓶颈,而采用分布式缓存则毕竟容易扩展。所以需要做好系统容量规划,并考虑是否可扩展。此外,不同的缓存框架或中间件,其效率和稳定性也是存在差异的。
其他因素
当缓存节点发生故障时,需要避免缓存失效并最大程度降低影响,这种特殊情况也是架构师需要考虑的。业内比较典型的做法就是通过一致性Hash算法,或者通过节点冗余的方式。
有些朋友可能会有这样的理解误区:既然业务需求对数据时效性要求很高,而缓存时间又会影响到缓存命中率,那么系统就别使用缓存了。其实这忽略了一个重要因素--并发。通常来讲,在相同缓存时间和key的情况下,并发越高,缓存的收益会越高,即便缓存时间很短。
提高缓存命中率的方法
从架构师的角度,需要应用尽可能的通过缓存直接获取数据,并避免缓存失效。这也是比较考验架构师能力的,需要在业务需求,缓存粒度,缓存策略,技术选型等各个方面去通盘考虑并做权衡。尽可能的聚焦在高频访问且时效性要求不高的热点业务上,通过缓存预加载(预热)、增加存储容量、调整缓存粒度、更新缓存等手段来提高命中率。
对于时效性很高(或缓存空间有限),内容跨度很大(或访问很随机),并且访问量不高的应用来说缓存命中率可能长期很低,可能预热后的缓存还没来得被访问就已经过期了
欢迎工作一到八年的Java工程师朋友们加入Java高级交流:787707172
本群提供免费的学习指导 架构资料 以及免费的解答
不懂得问题都可以在本群提出来 之后还会有直播平台和讲师直接交流噢














 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









