





在本文中,我们提供了Windows Azure存储体系结构的概述,以便了解它的工作原理。Windows Azure存储是Microsoft完全为云构建的分布式存储软件堆栈。
在深入了解这篇文章的细节之前,请阅读之前在Windows Azure存储抽象及其可伸缩性目标上发布的内容,以了解所提供的存储抽象(Blob,表和队列)以及分区的概念。
3层架构
存储访问体系结构具有以下3个基本层:
前端(FE)层 - 此层接收传入请求,对请求进行身份验证和授权,然后将它们路由到分区层中的分区服务器。前端知道将每个请求转发到哪个分区服务器,因为每个前端服务器都缓存一个分区映射。分区映射会跟踪正在访问的服务(Blob,表或队列)的分区以及分区服务器控制(服务)对系统中每个分区的访问权限。
分区层 - 该层管理系统中所有数据对象的分区。如先前发布中所述,所有对象都具有分区键。对象属于单个分区,每个分区仅由一个分区服务器提供服务。这是管理在哪个分区服务器上提供分区的层。此外,它还提供跨服务器的分区的自动负载平衡,以满足Blob,表和队列的流量需求。单个分区服务器可以服务于许多分区。
分布式和复制文件系统(DFS)层 - 这是实际将位存储在磁盘上的层,负责跨多个服务器分发和复制数据以保持其持久性。这里要理解的一个关键概念是数据由DFS层存储,但所有DFS服务器(以及存储在DFS层中的所有数据)都可以从任何分区服务器访问。
这些图层和高级概述如下图所示:
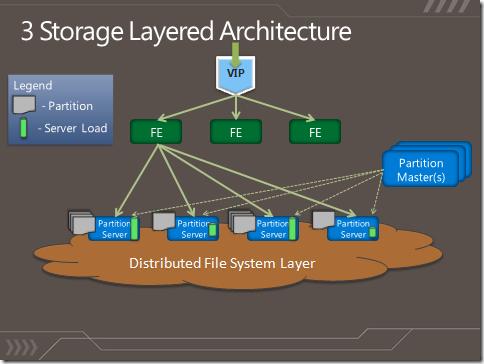
图1 3层存储架构
在这里,我们可以看到前端层接收传入请求,并且给定的前端服务器可以与所需的所有分区服务器通信,以便处理传入的请求。分区层由所有分区服务器组成,主系统用于执行自动负载平衡(如下所述)和分区分配。如图所示,为每个分区服务器分配一组对象分区(Blob,实体,队列)。分区主服务器不断监视每个分区服务器以及各个分区的总负载,并将其用于负载平衡。然后,存储体系结构的最低层是分布式文件系统层,它存储和复制数据,所有分区服务器都可以访问任何DFS服务器。
请求的生命周期
要了解架构的工作原理,让我们首先了解请求流经系统的生命周期。Blob,实体和消息请求的过程相同:
DNS查找 - 对Windows Azure存储执行的请求对正在访问的对象的Uri的域名执行DNS解析。例如,blob请求的域名是“ 。blob.core.windows.net”。这用于将请求定向到分配存储帐户的地理位置(子区域),以及该地理位置中的Blob服务。
前端服务器进程请求 - 请求到达前端,执行以下操作:
- 对请求执行身份验证和授权
- 使用请求的分区键在分区视图中查找以查找为分区服务的分区服务器。有关请求的分区键的说明,请参阅此文章。
- 将请求发送到相应的分区服务器
- 从分区服务器获取响应,并将其发送回客户端。
分区服务器进程请求 - 请求到达分区服务器,并且根据请求是GET(读取操作)还是PUT / POST / DELETE(写入操作)发生以下情况:
GET
查看数据是否缓存在分区服务器的内存中。如果是这样,直接从内存返回数据。否则,向其中一个DFS服务器发送读取请求,其中包含正在读取的数据的副本之一。
PUT / POST / DELETE
将请求发送到主DFS服务器(请参阅下面的详细信息),保存数据以执行插入/更新/删除。
DFS服务器进程请求 - 从持久存储中读取/插入/更新/删除数据,并返回状态(和读取的数据)。注意,对于插入/更新/删除,在成功返回到客户端之前,数据将在多个DFS服务器之间复制(有关详细信息,请参阅下文)。
大多数请求都是单个分区,但列出Blob容器,Blob,表和队列以及表查询可以跨多个分区。当跨越分区的列表/查询请求到达FE服务器时,我们通过分区映射知道需要联系以执行查询的一组分区服务器。根据查询和查询的分区数量,查询可能只需要转到单个分区服务器来处理其请求。如果分区映射显示查询需要转到多个分区服务器,我们通过在分区键顺序中排序的那些分区服务器上执行查询来序列化查询。然后在分区服务器边界,或者当我们达到1,000个查询结果时,或者当我们达到5秒的处理时间时,如果我们还没有完成查询,我们返回到目前为止累积的结果和一个延续令牌。然后,当客户端重新传递延续令牌以继续列表/查询时,我们知道要从中继续列表/查询的主键。
故障域和服务器故障
现在我们想谈谈在面对硬件故障时我们如何保持可用性。第一个概念是跨不同的故障域分布服务器,因此如果发生硬件故障,只有一小部分服务器受到影响。这3层服务器分布在不同的故障域上,因此如果给定的故障域(机架,网络交换机,电源)发生故障,该服务仍可用于提供服务数据。
以下是我们如何处理三个不同层中每个层的节点故障:
前端服务器故障 - 如果前端服务器无响应,则负载均衡器将实现此功能并将其从提供来自传入VIP的请求的可用服务器中取出。这可确保将命中VIP的请求发送到等待处理请求的实时前端服务器。
分区服务器故障 - 如果存储系统确定分区服务器不可用,它会立即将其服务的所有分区重新分配给其他可用分区服务器,并更新前端服务器的分区映射以反映此更改(所以前面 -结束可以正确定位重新分配的分区)。请注意,将分区分配给不同的分区服务器时,没有数据在磁盘上移动,因为所有分区数据都存储在DFS服务器层中,并且可以从任何分区服务器访问。存储系统确保始终提供所有分区。
DFS服务器故障 - 如果存储系统确定DFS服务器不可用,则分区层在不可用时停止使用DFS服务器进行读写。相反,分区层使用包含数据的其他副本的其他可用DFS服务器。如果DFS服务器不可用太长时间,我们会生成数据的其他副本,以便将数据保持在健康数量的重复项以保持持久性。
升级域和滚动升级
与故障域正交的概念就是我们所说的升级域。3层中每层的服务器均匀分布在不同的故障域上,并升级存储服务的域。这样,如果故障域发生故障,我们最多会丢失给定层的1 / X服务器,其中X是故障域的数量。同样,在服务升级期间,给定层的服务器最多1 / Y在给定时间升级,其中Y是升级域的数量。为实现此目的,我们使用滚动升级,这使我们能够在升级存储服务时保持高可用性。
每个层中的服务器都通过一组升级域进行分解,我们一次升级一个升级域。例如,如果我们有10个升级域,那么升级单个域可能会一次从每个层升级最多10%的服务器。升级域的描述和使用滚动升级的示例在PDC 2009关于为Windows Azure构建可伸缩和可靠应用程序的模式的讨论中(25:00)。
我们使用滚动升级一次为我们的存储服务升级单个域。在升级期间维护可用性的关键部分是,在升级给定域之前,我们主动卸载在该升级域中的分区服务器上提供的所有分区。此外,我们将升级域中的DFS服务器标记为已升级,以便在升级过程中不使用它们。此准备工作在升级域之前完成,因此在升级时我们会减少对服务的影响以保持高可用性。
升级域完成升级后,我们允许该域中的服务器再次提供数据。此外,在我们升级给定域之后,我们会在进入下一个升级域之前验证服务是否正常运行。在升级整个服务之前,此过程允许我们在前几个升级域中的一小部分服务器上验证我们所做的预发布测试之上和之外的生产配置。通常情况下,如果在升级过程中出现问题,则在升级第一个或两个升级域时会出现问题,如果看起来不太正确,我们会暂停升级以进行调查,我们甚至可以回滚到之前的版本生产软件,如果需要的话。
现在,我们将从DFS层开始更详细地介绍系统的较低层到层。
DFS层和复制
Windows Azure存储的持久性是通过复制数据提供的,其中所有数据都被多次复制。底层复制层是分布式文件系统(DFS),数据分布在数百个存储节点上。由于底层复制层是分布式文件系统,因此可以从所有分区服务器以及其他DFS服务器访问副本。
DFS层将数据存储在所谓的“范围”中。这是磁盘上的存储单元和复制单元,其中每个扩展区都被复制多次。典型的范围大小范围从大约100MB到1GB。
将Blob存储在Blob容器,表中的实体或队列中的消息时,持久数据存储在一个或多个范围中。这些范围中的每一个都具有多个副本,这些副本在提供“数据传播”的不同DFS服务器上随机分布。例如,可以跨10个1 GB范围存储10GB blob,如果每个范围有3个副本,则此Blob的相应30个范围副本可以分布在30个不同的DFS服务器上进行存储。此设计允许Blob,表和队列跨越多个磁盘驱动器和DFS服务器,因为数据被分解为块(扩展区),DFS层将扩展区分布在许多不同的DFS服务器上。此设计还允许更多数量的IOps和网络BW访问Blob,表格,和队列相比,单个存储DFS服务器上的IOps / BW。这是数据分布在多个范围内的直接结果,而这些范围又分布在不同的磁盘和不同的DFS服务器上,因为范围的任何副本都可用于读取数据。
在给定的范围内,DFS具有主服务器和多个辅助服务器。所有写入都通过主服务器,然后主服务器将写入发送到辅助服务器。一旦将数据写入至少3个DFS服务器,成功将从主服务器返回到客户端。如果在执行写操作时无法访问其中一个DFS服务器,则DFS层将选择更多服务器来写入数据,以便(a)所有数据更新至少写入3次(3个单独的磁盘/服务器在3个单独的故障中+在将成功返回到客户端之前升级域和(b)写入可以在DFS服务器无法访问时前进。可以从任何最新的扩展区副本(主要副本或辅助副本)处理读取,因此可以从其辅助DFS服务器上的扩展区副本成功处理读取。
扩展区的多个副本分布在不同的故障域和升级域上,因此扩展区中没有两个副本将放置在同一故障域或升级域中。为每个数据项保留多个副本,因此如果一个故障域出现故障,仍然会有健康的副本来访问数据,系统将动态地重新复制数据以将其恢复到健康数量的副本。在升级期间,每个升级域将单独升级,如上所述。如果数据的扩展区副本位于当前正在升级的某个域中,则扩展区数据将从未升级的其他升级域中的一个当前可用副本提供。
复制层的关键原则是动态重新复制并具有低MTTR(平均恢复时间)。如果给定的DFS服务器丢失或驱动器发生故障,则会快速重新复制在丢失的节点/驱动器上具有副本的所有扩展区,以使这些扩展区恢复到正常数量的副本。重新复制很快就完成了,因为受影响的扩展区的其他健康副本随机分布在不同故障/升级域中的许多DFS服务器上,从而提供足够的磁盘/网络带宽来非常快速地重建副本。例如,要重新复制具有许多TB数据的故障DFS服务器,可能有数十万个丢失的扩展区副本,这些扩展区的健康副本可能分布在数百到数千个存储节点和驱动器中。为了将这些范围恢复到健康数量的副本,所有这些存储节点和驱动器都可用于(a)从健康的剩余副本中读取,以及(b)将丢失副本的另一个副本写入到随机节点中范围的不同故障/升级域。此恢复过程允许我们利用存储服务中所有节点上的可用网络/磁盘资源,可能在几分钟内重新复制丢失的存储节点,这是具有低MTTR以防止数据丢失的关键属性。
DFS复制层的另一个重要特性是检查和扫描数据以查找位腐烂。写入的所有数据都有一个校验和(存储系统内部)。通过读取数据并验证校验和,连续扫描数据的位腐蚀。此外,我们总是在读取客户端请求的数据时验证此内部校验和。如果通过其中一个检查发现扩展副本已损坏,则会丢弃损坏的副本,并使用其中一个有效副本重新复制扩展区,以使扩展区恢复到正常的复制级别。
地域复制
Windows Azure存储通过不断维护数据的多个健康副本来提供持久性。为实现此目的,如上所述,跨越不同的故障和升级域在单个位置(例如,美国南部)内提供复制。这在给定位置内提供耐久性。但是,如果某个地点发生区域性灾难(例如,野火,地震等)可能会影响许多英里的区域,该怎么办?
我们正致力于提供一项称为地理复制的功能,该功能可在两个地点之间(即美国北部和南部之间,北欧和西欧之间以及东亚和东南亚之间)复制数百英里的客户数据,以便提供灾难恢复。区域性灾害。地理复制是在上述单个位置内由DFS层维护的多个副本的补充。我们将在未来的博客文章中详细介绍地理复制如何工作以及如何提供地理多样性,以便在发生区域性灾难时提供灾难恢复。
负载平衡热DFS服务器
Windows Azure存储在分区层和DFS层都具有负载平衡。分区负载平衡解决了分区服务器每秒获取过多请求以使其处理其所服务的分区的问题,并在其他分区服务器之间对这些分区进行负载平衡以均衡负载。相反,DFS层专注于将I / O负载负载平衡到其磁盘,将网络BW负载平衡到其服务器。
DFS服务器在I / O和BW负载方面可能会过热,我们为DFS服务器提供自动负载平衡以解决此问题。我们在DFS层提供两种形式的负载平衡:
阅读负载平衡 - DFS层通过它保留的多个副本维护多个数据副本,并构建系统以允许从任何最新的副本副本中读取。系统会跟踪DFS服务器上的负载。如果DFS服务器请求处理的请求太多,则尝试访问该DFS服务器的分区服务器将被路由以从其他DFS服务器读取,这些服务器保存分区服务器尝试访问的数据的副本。当给定的DFS服务器过热时,这有效地平衡了DFS服务器上的读取。如果所有DFS服务器对于从分区服务器访问的给定数据集来说都太热,我们可以选择增加DFS层中数据的副本数以提供更多吞吐量。但是,热数据主要由分区层处理,
写入负载平衡 - 对给定数据的所有写入都将转到主DFS服务器,该服务器协调对扩展区的辅助DFS服务器的写入。如果任何DFS服务器变得太热而无法为请求提供服务,则存储系统将选择不同的DFS服务器来将数据写入。
为什么分区层和DFS层?
在描述体系结构时,我们得到的一个问题是为什么我们同时拥有分区层和DFS层,而不是只存储数据和提供负载平衡的一层?
DFS层可以被认为是我们的文件系统层,它理解文件(这些大块存储称为扩展区),如何存储它们,如何复制它们等,但它不了解更高级别的对象构造,也不了解它们语义。分区层专门用于管理和理解更高级别的数据抽象,并将它们存储在DFS之上。
分区层了解事务对给定对象类型(Blob,实体,消息)的含义。此外,它还提供并行事务的排序和不同类型对象的强一致性。最后,分区层跨多个DFS服务器块(称为扩展区)扩展大对象,以便可以存储大对象(例如,1 TB Blob),而不必担心单个磁盘或DFS服务器上的空间不足,因为大blob分布在许多DFS服务器和磁盘上。
分区和分区服务器
当我们说分区服务器正在为分区服务时,我们的意思是分区服务器已被指定为服务器(暂时),它控制对该分区中对象的所有访问。我们这样做是为了对于给定的一组对象,有一个服务器向这些对象排序事务并提供强一致性和乐观并发性,因为单个服务器控制着给定对象分区的访问。
在先前的可伸缩性目标帖子中,我们描述了单个分区每秒最多可处理500个实体/消息。这是因为对单个分区的所有请求都必须由分配的分区服务器提供服务。因此,在设计解决方案时,了解Blob,表和队列的可伸缩性目标和分区键非常重要(有关更多信息,请参阅即将发布的有关充分利用Blob,表和队列的帖子)。
负载平衡热分区服务器
重要的是要理解分区没有绑定到特定的分区服务器,因为数据存储在DFS层中。因此,分区层可以轻松地进行负载平衡并将分区分配给不同的分区服务器,因为任何分区服务器都可以提供对任何分区的访问。
分区层根据每个分区的负载将分区分配给分区服务器。给定的分区服务器可以为许多分区提供服务,分区主服务器会持续监视所有分区服务器上的负载。如果它发现分区服务器负载过大,分区层将自动将一些分区从该分区服务器负载平衡到低负载的分区服务器。
将分区从一个分区服务器重新分配给另一个分区服务器时,该分区仅在几秒钟内脱机,以保持该分区的高可用性。然后,为了确保我们不会过多地移动分区并且做出太快的决策,决定对热分区服务器进行负载均衡所花费的时间大约为几分钟。
总结
Windows Azure存储体系结构有三个主要层 - 前端层,分区层和DFS层。对于可用性,每个层都有自己的自动负载平衡形式,并处理故障和恢复,以便在访问数据时提供高可用性。对于持久性,这是由DFS层提供的,它保留数据的多个副本,并使用数据传播在发生故障时保持较低的MTTR。为了保持一致性,分区层通过确保单个分区服务器始终订购并提供对每个数据分区的访问来提供强一致性和乐观并发性。














 2473
2473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









