





微信公众号:算法狗
【面试经系列】分享最简洁的面试经;如果你觉得对你有帮助,欢迎赞赏
内容目录
LR算法理解逻辑回归适用性逻辑回归的假设损失函数推导梯度下降推导LR的优缺点线性回归与逻辑回归的区别逻辑回归与朴素贝叶斯有什么区别
LR算法理解
一句话概括逻辑回归:假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,达到将数据二分类的目的。包含了以下5个方面 :
1.逻辑回归的假设条件
2.逻辑回归的损失函数
3.逻辑回归的求解方法
4.逻辑回归的目的
5.逻辑回归如何分类
逻辑回归适用性
用于概率预测。
比如根据模型预测在不同的自变量情况下,某种情况的发生的概率有多大。用于分类。
实际上跟预测有些类似,需要设定一个阈值,高于阈值是一类,低于阈值是另一类。各特征之间不需要满足条件独立假设,但各个特征的贡献独立计算。
仅能用于线性问题。只有当目标和特征是线性关系时,才能用逻辑回归。
在应用逻辑回归时注意两点:
1.当知道模型是非线性时,不适用逻辑回归;
2.当使用逻辑回归时,应注意选择和目标为线性关系的特征。
逻辑回归的假设
第一个假设:样本服从伯努利分布
伯努利分布有一个简单的例子是抛硬币,为正面的概率用h表示,那么为负面的概率就是1-h,那么整个模型就可以用下述公式描述:
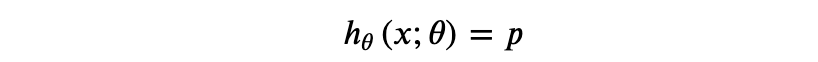
第二个假设:样本为正的概率是:
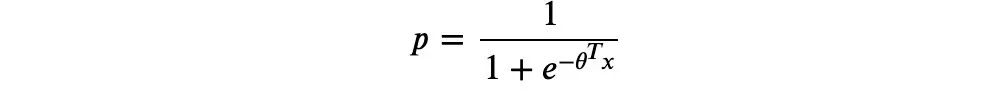
所以逻辑回归的最终形式:
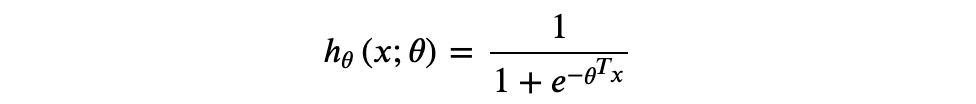
损失函数推导
逻辑回归损失函数:
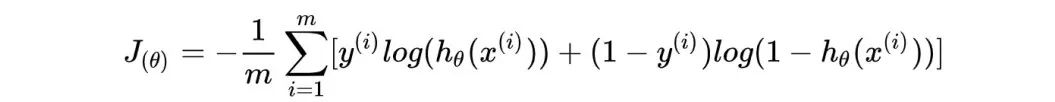
详细推导过程:
0-1分布的分布律为:
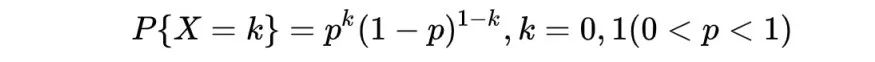
当是来自于样本X1,X2,…Xn的一个样本值,X的分布律为:
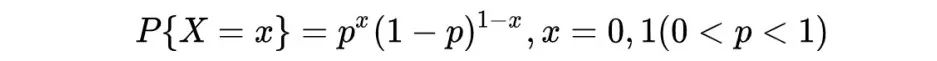
它的似然函数为:
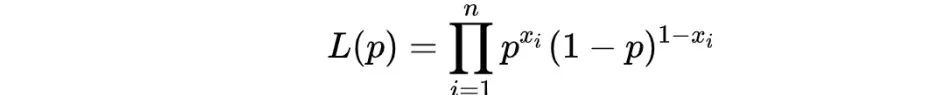
似然函数的对数形式为:
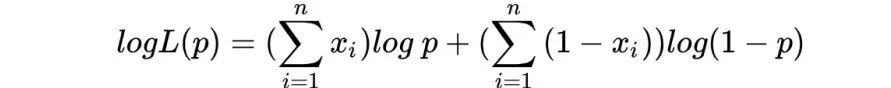
逻辑回归中sigmoid函数为:
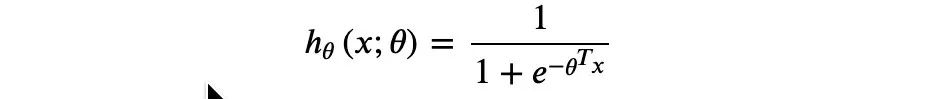
可以用sigmoid函数表示0-1中取1的概率,在这里用于表示逻辑回归中的概率。
根据0-1分布的似然函数,我们可以写出逻辑回归的似然函数:

对数形式为:
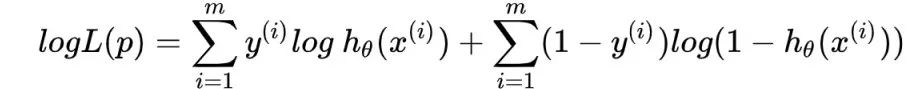
逻辑回归的损失函数为:

损失函数跟对数形式的似然函数很像,只是在前面乘以-1/m,最大似然估计的方法要求logL(p)的最大值,损失函数在其前面加上负号,就是求最小值,这个跟损失函数的特性刚好吻合。
因此,逻辑回归的损失函数求最小值,就是根据最大似然估计的方法来的。
梯度下降推导
逻辑回归通过梯度下降更新 theta:
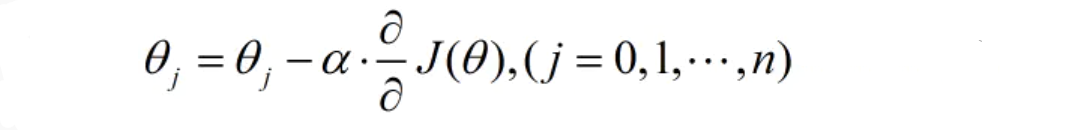
具体过程:
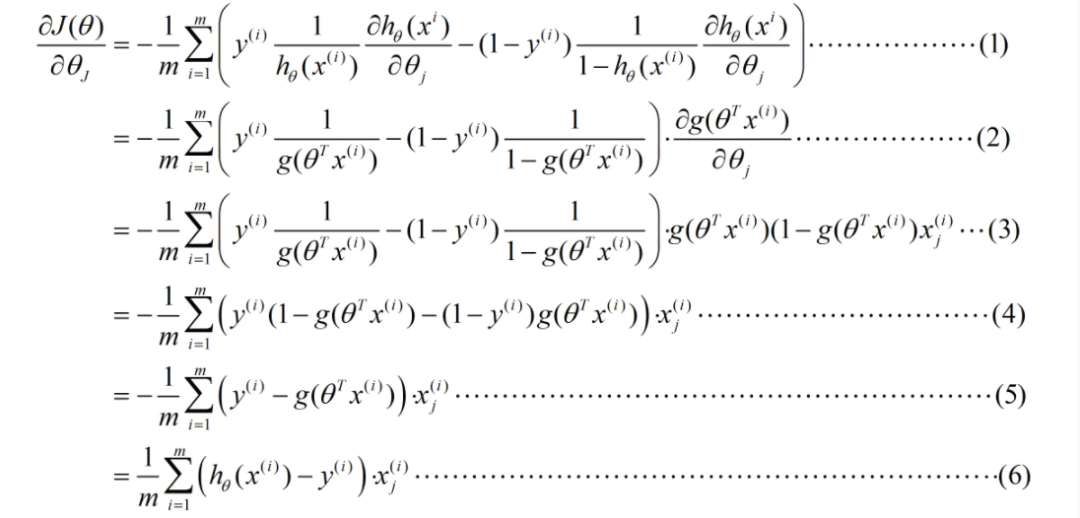
使用到:
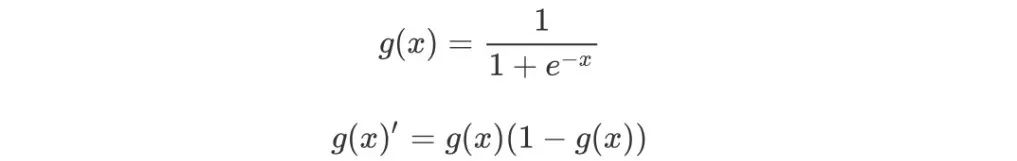
LR的优缺点
优点:
速度快。
简单易于理解,直接看到各个特征的权重。
能容易地更新模型吸收新的数据。
如果想要一个概率框架,动态调整分类阀值。
缺点:
特征处理复杂;
需要归一化和较多的特征工程。
线性回归与逻辑回归的区别
1. 线性回归的样本的输出,都是连续值,而逻辑回归只能取0和1。
2. 对于拟合函数也有本质上的差别:线性回归的拟合函数,是对f(x)的输出变量y的拟合,而逻辑回归的拟合函数是对为1类样本的概率的拟合。
| 模型 | 线性回归 | 逻辑回归 |
|---|---|---|
| 目的 | 预测 | 分类 |
| 预测值 | 未知 | (0,1) |
| 函数 | 拟合函数 | 预测函数 |
| 参数计算方式 | 最小二乘法 | 极大似然估计 |
逻辑回归与朴素贝叶斯有什么区别
逻辑回归是判别模型,朴素贝叶斯是生成模型,所以生成和判别的所有区别它们都有。
朴素贝叶斯属于贝叶斯,逻辑回归是最大似然,两种概率哲学间的区别。
朴素贝叶斯需要条件独立假设。
逻辑回归需要求特征参数间是线性的。















 1954
1954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









