






OpenMMLab AI实战营 第2课:图像分类与基础视觉模型
一、图像分类简介
不做赘述
二、卷积神经网络
- AlexNet(2012)
- Going Deeper(2012~2014)
- VGG
- 3x3 卷积
- GoogLeNet
- Inception Block
- VGG
- ResNet(2015)
- Basic Block
- Bottleneck Block
- ResNet是深浅模型的集成
- 残差链接让损失曲面更光滑
- ResNet B/C/D 残差模块的改进
- ResNeXt
- SEResNet
三、更强的图像分类模型
- 神经结构搜索 Neutral Architecture Search(2016+)
- Vision Transformers(2020+)
- Vision Transformer(2020)
- Swin Transformer(2021)
- ConvNeXt(2022)
四、轻量化卷积神经网络
- 卷积的参数量和计算量
input feature
X
∈
R
H
×
W
×
C
X \in \mathbb{R} ^ {H \times W \times C}
X∈RH×W×C
output feature
Y
∈
R
H
′
×
W
′
×
C
′
Y \in \mathbb{R} ^ {H' \times W' \times C'}
Y∈RH′×W′×C′
C
′
C'
C′个
C
C
C通道的卷积核
K
∈
R
C
′
×
K
×
K
×
C
′
K \in \mathbb{R} ^ {C' \times K \times K \times C'}
K∈RC′×K×K×C′
C
′
C'
C′个偏置值
b
∈
R
C
′
b \in \mathbb{R} ^ {C'}
b∈RC′
参数量:
C
′
×
(
C
×
K
×
K
+
1
)
=
C
′
C
K
2
+
C
′
C' \times (C \times K \times K + 1) = C'CK^2 + C'
C′×(C×K×K+1)=C′CK2+C′
计算量:
H
′
×
W
′
×
C
′
×
K
×
K
×
C
=
H
′
W
′
C
′
C
K
2
H' \times W' \times C' \times K \times K \times C = H'W'C'CK^2
H′×W′×C′×K×K×C=H′W′C′CK2
-
降低模型参数量和计算量
- 降低通道数
C
′
C'
C′和
C
C
C(平方级别)
- ResNet使用1x1卷积压缩通道
- 减小卷积核
K
K
K(平方级别)
- GoogLeNet使用不同大小的卷积核
- 降低通道数
C
′
C'
C′和
C
C
C(平方级别)
-
可分离卷积
- 参数量: C × K × K + C × C ′ C \times K \times K + C \times C' C×K×K+C×C′
- 计算量: H ′ × W ′ × C × K × K × + C ′ × H ′ × W ′ × C = H ′ W ′ C K 2 + H ′ W ′ C ′ C H' \times W' \times C \times K \times K \times + C' \times H' \times W' \times C = H'W'CK^2 + H'W'C'C H′×W′×C×K×K×+C′×H′×W′×C=H′W′CK2+H′W′C′C
- 模型
- MobileNets V1V3(20172019)
- V1:深度可分离卷积
- V2:Inverted Residuals
- V3:NAS + SE
- ResNeXt
- MobileNets V1V3(20172019)
五、Vision Transformer
- 注意力机制
- 卷积
- 权重是可学习参数,但与输入无关
- 只能建模局部关系,远距离关系只能通过多层卷积实现
- 注意力机制
- 权重是输入的函数
- 可以不局限于邻域,显示建模远距离关系
- 卷积
- Attention实现
- QKV
- 多头注意力
- Vision Transformer(2020)
- 将图像切分成若干 16×16 的小块,当作一列"词向量",经多层 Transformer Encoder 变换产生特征
- 图块之外加入额外的 token,用于 query 其他 patch 的特征并给出最后分类
- 注意力模块基于全局感受野,复杂度为尺寸的 4 次方
- Swin Transformer(ICCV 2021 Best Paper)
- 分层结构
- Split Window
- Shifted Window Multi-Head Self-Attention
六、模型学习
- 模型学习范式
- 监督学习
- 交叉熵损失
- 优化目标
- SGD
- Momentum SGD
- 自监督学习
- 监督学习
七、学习率与优化器策略
-
权重初始化
- 随机初始化
- 朴素方法:均匀分布、高斯分别
- Xavier初始化
- Kaiming初始化
- 预训练权重
- 随机初始化
-
学习率调整策略
- Annealing
- Warmup
- Linear Scaling Rule
- 针对同一训练任务,当batch size扩大到原来的k倍时,学习率也应该扩大k倍
- 这样可以保证每个样本带来的梯度下降步长相同

-
自适应梯度算法
不同的参数需要不同的学习率,根据梯度的历史幅度自动调整学习率- Adagrad
- Adam/AdamW
-
正则化与权重衰减
-
早停策略
-
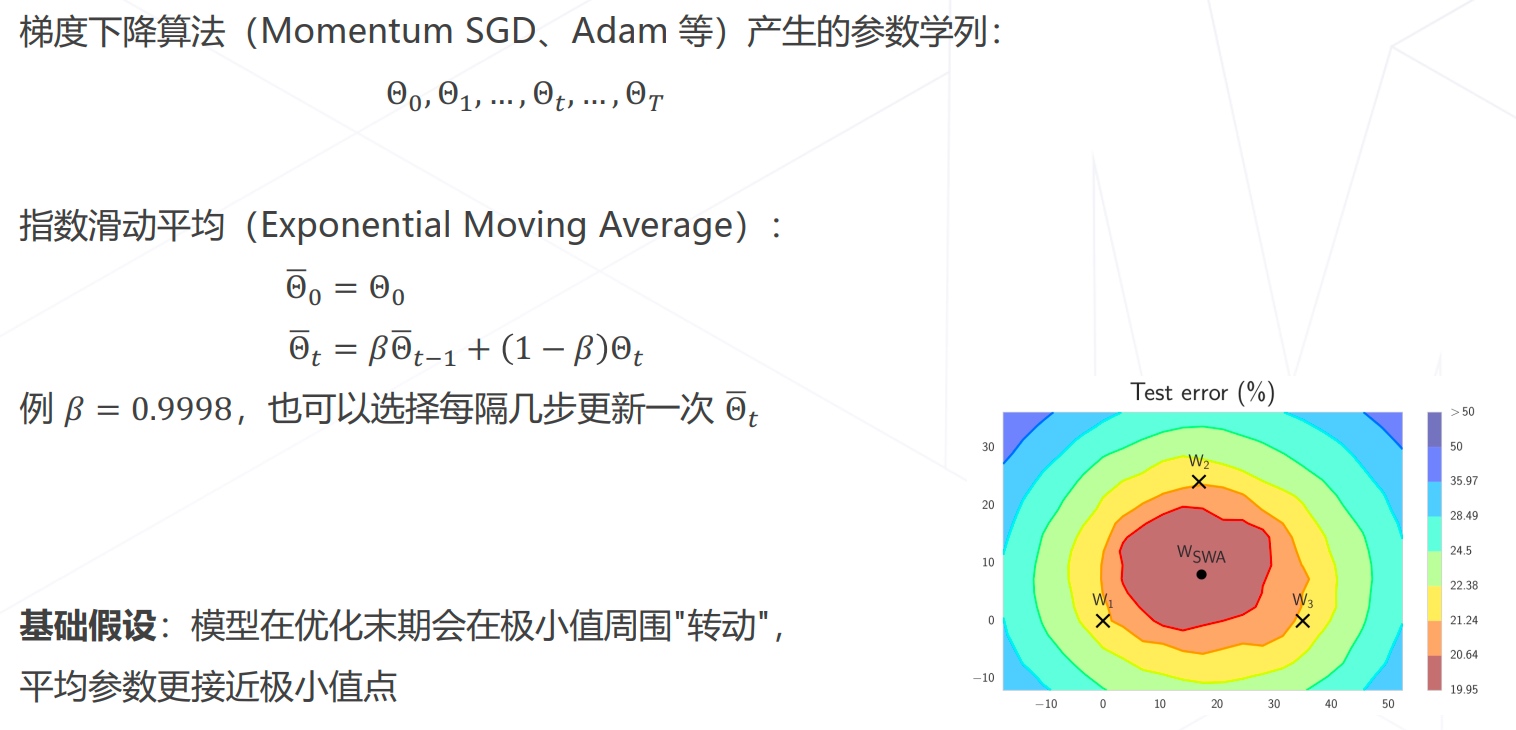
模型权重平均EMA
-
模型权重平均SWA

八、数据增强
- 组合数据增强
- AutoAugment
- RandomAugment
- 组合图形
- Mixup
- CutMix
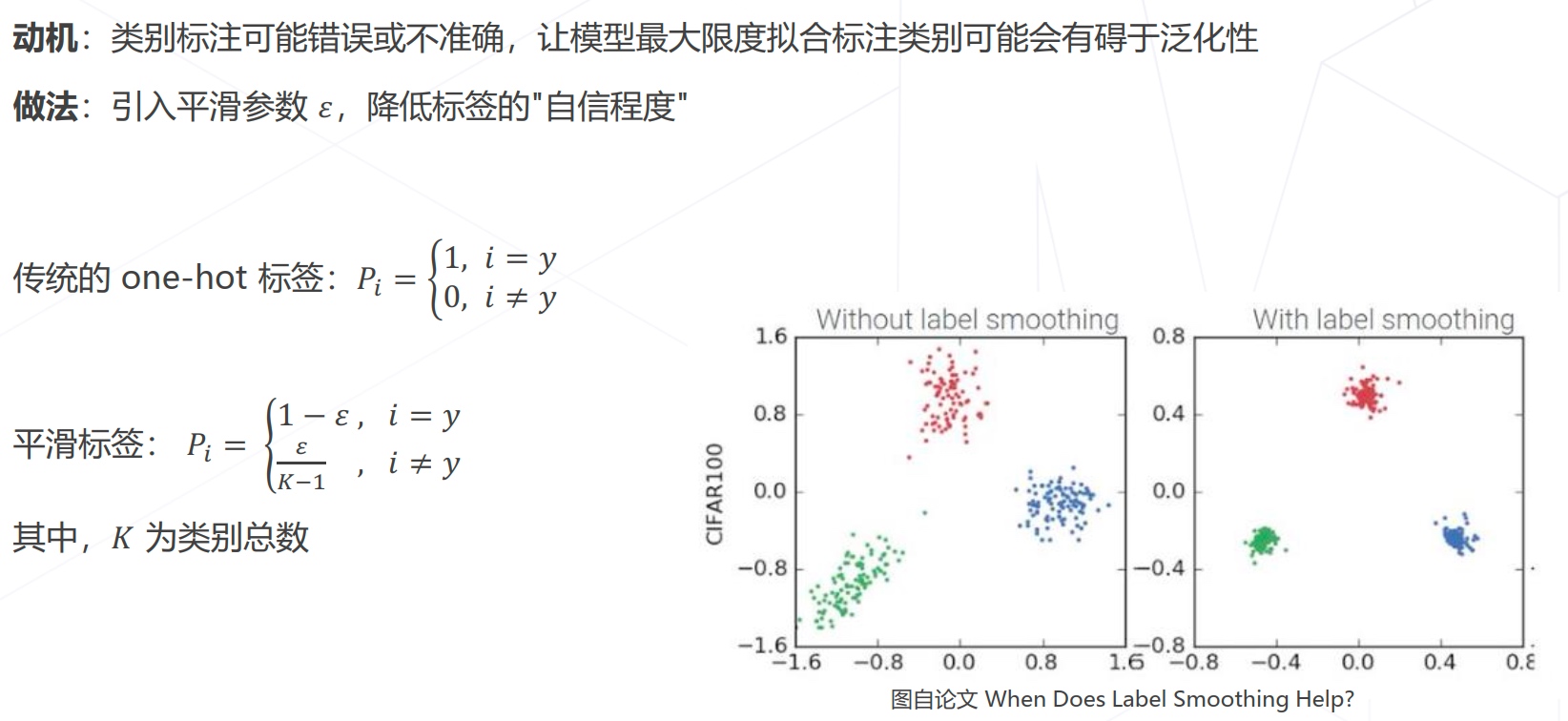
- 标签平滑
九、模型相关策略
- Dropout
- Stochastic Depth

十、自监督学习
- 自监督学习的场景类型
- 基于代理任务
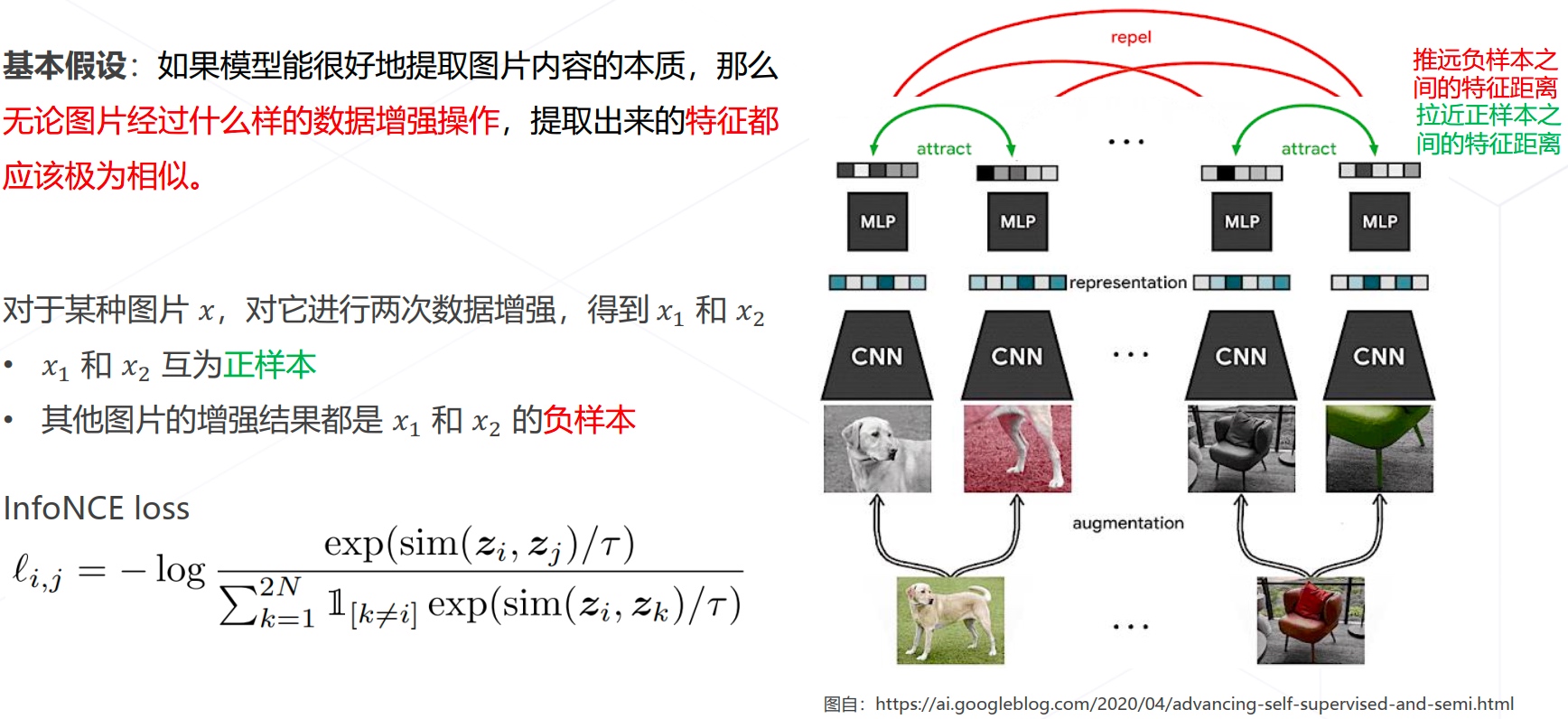
- 基于对比学习
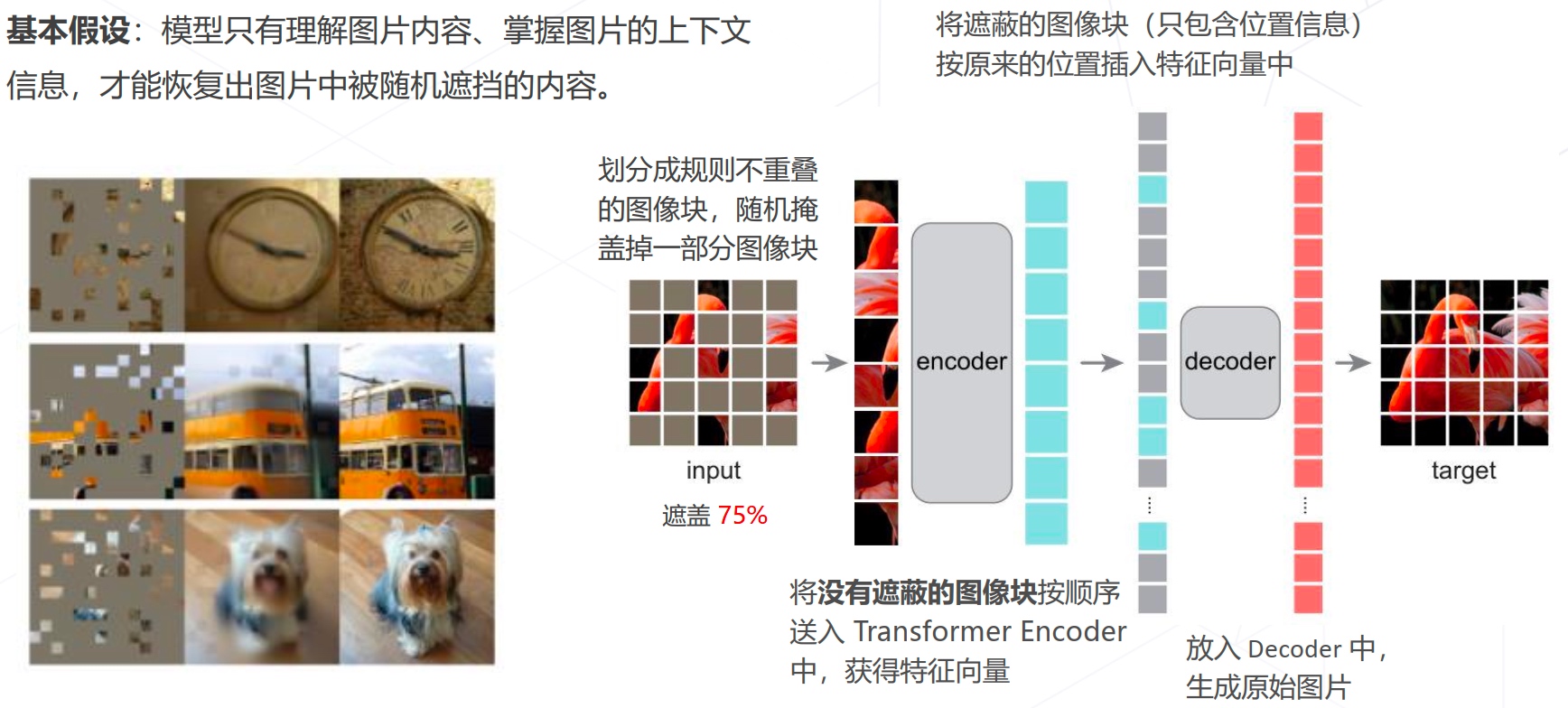
- 基于掩码学习
- Relative Location(ICCV2015)

- SimCLR(ICML2020)
- MAE(CVPR2022)
十一、MMClassification介绍
这里直接看视频讲解和PPT即可。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









