






一、innodb
1.支持事务
事务ACID(atomicity原子性、consistency一致性、isolation隔离性、durability持久性)
A:事务要么全执行,要么全不执行
C:事务执行前后,数据完整性一致
I:多用户并发访问数据库时,数据库为每个用户创建的事务间相互隔离
D:事务一旦被提交,对数据库中数据的改变就是持久的
四个隔离级别
1)Read uncommitted(最低级别)
脏读:事务A读取了事务B未提交的数据,事务B却回滚了。
2)Read committed (可避免脏读)
不可重复读:针对其他事务提交前后,读取数据本身的对比不同,(记录的修改)
3)Repeatable read(避免脏读,不可重复读)
幻读:针对其他事务提交前后,读取的记录的条数不同(记录的增删)
4)Serializable(最高级别,可避免脏读,不可重复读,幻读)
2.支持行级锁定:
仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作
3.存储
基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,
InnoDB 表的大小只受限于操作系统文件的大小
4.索引组织表
使用的聚簇索引、索引就是数据,顺序存储,因此能缓存索引,也能缓存数据
5.服务器数据备份
必须导出SQL来备份,
LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,
解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,
但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
6.使用场景
需要事务支持(具有较好的事务特性)
行级锁定对高并发有很好的适应能力,但需要确保查询是通过索引完成
经常更新的表,适合处理多重并发的更新请求
数据一致性要求较高
硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,尽可能减少磁盘 IO
主键尽可能小,避免给Secondary index带来过大的空间负担
避免全表扫描,因为会导致锁表。(sql语句中含有where条件同时明确主键)
尽可能缓存所有的索引和数据,提高响应速度
在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交
合理设置innodb_flush_log_at_trx_commit参数值,不要过度追求安全性
避免主键更新,因为这会带来大量的数据移动
7.引擎原理
二、MyISAM
1.管理非事务表,提供高速存储和检索,以及全文搜索能力
2.支持表级锁定:
直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作。
如果你是写锁(X锁,排他锁),则其它进程则读也不允许直接锁定整张表,
3.存储
索引和数据是分开的,并且索引是有压缩的。
在磁盘上存储成三个文件。
.frm文件用于存储表的定义,
.MYD文件用于存储表的数据,
.MYI文件,存储的是索引。
操作系统对大文件的操作是比较慢的,这样将表分为三个文件,
那么.MYD这个文件单独来存放数据自然可以优化数据库的查询等操作。
有索引管理和字段管理。
4.堆组织表
使用的是非聚簇索引、索引和文件分开,随机存储,只能缓存索引
5.服务器数据备份
应对错误编码导致的数据恢复速度快。
MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。
在备份和恢复时可单独针对某个表进行操作
6.使用场景
不需要事务支持(不支持)
并发相对较低(锁定机制问题)
插入修改不频繁,查询非常频繁
数据一致性要求不是非常高
尽量索引(缓存机制)
调整读写优先级,根据实际需求确保重要操作更优先
启用延迟插入改善大批量写入性能
尽量顺序操作让insert数据都写入到尾部,减少阻塞
分解大的操作,降低单个操作的阻塞时间
降低并发数,某些高并发场景通过应用来进行排队机制
对于相对静态的数据,充分利用Query Cache可以极大的提高访问效率
MyISAM的Count只有在全表扫描的时候特别高效,带有其他条件的count都需要进行实际的数据访问
7.引擎原理
三、其他
1.如果需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。
2.mysql支持三种锁定级别,行级、页级、表级
四、Innodb和MyIASM的引擎原理
1、Innodb
引擎的索引结构,使用B+Tree作为索引结构。
InnoDB的数据文件本身就是索引文件,数据文件本身就是按B+Tree组织的一个索引
结构,这棵树的叶节点data域保存了完整的数据记录,这种索引就是聚集索引。
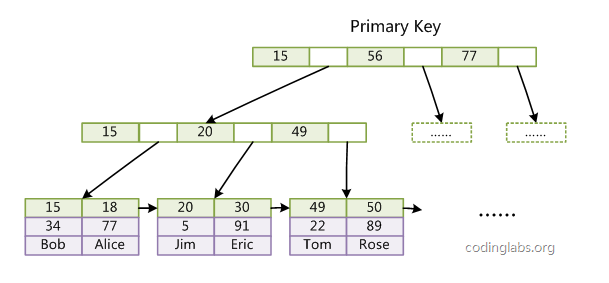
主键索引:
a、因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有)。b、如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键。
c、如果不存在唯一标识数据记录的列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
辅助索引
InnoDB的辅助索引data域存储相应记录主键的值而不是地址即InnoDB的所有辅助索引都引用主键作为data域
2、MyIASM
引擎的索引结构:使用B+Tree作为索引结构
MyISAM索引实现:
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址,即叶节点的data域存放的是数据记录的地址
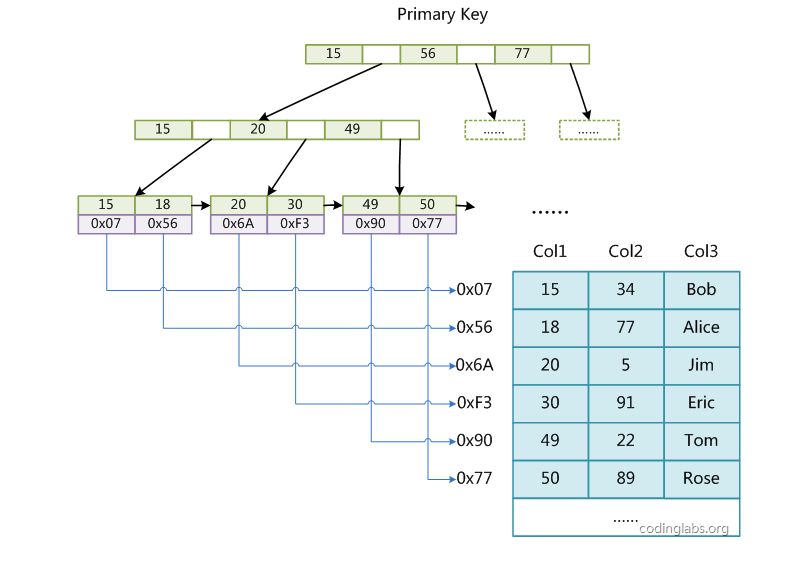
索引检索的算法:
首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
主键索引和辅助索引(结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复)
3、注意
对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在
MyISAM表中,可以和其他字段一起建立联合索引。
InnoDB 中不保存表的具体行数,也就是说,执行select count() fromtable时,
InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行
数即可。注意的是,当count()语句包含where条件时,两种表的操作是一样的
来源:https://m.ifeng.com/miArticle?ch=ref_xmllq_hz1&version=2&aid=ucms_7q7rbVyL69F&mibusinessId=miuibrowser&env=production&ref=browser_news&s=mb&cp=cn-fenghuang-browser&docid=fenghuang_ucms_7q7rbVyL69F&itemtype=news&_miui_bottom_bar=comment&cateCode=rec&category=%E7%A7%91%E6%8A%80&traceId=69EFF0D29A24F938C25321831ABE59B6&share=social&source=liulanqi















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









