





摘要: 最强NLP模型谷歌BERT狂破11项纪录,全面超越人类,本文通过可视化带你直观了解它。

2018年是自然语言处理(Natural Language Processing, NLP)领域的转折点,一系列深度学习模型在智能问答及情感分类等NLP任务中均取得了最先进的成果。近期,谷歌提出了BERT模型,在各种任务上表现卓越,有人称其为“一个解决所有问题的模型”。
BERT模型的核心思想有两点,对推动NLP的发展有着重要的作用:(1)Transformer结构;(2)无监督的预训练。Transformer是一个只基于注意力(Attention)机制的序列模型,《Attention is all you need》一文中指出,它摒弃了固有的定式,没有采用RNN的结构。BERT模型同时需要预训练,从两个无监督任务中获取权重:语言建模(给定左右上下文,预测丢失的单词)以及下一个句子预测(预测一个句子是否跟在另一个句子后面)。
BERT是个“多头怪”
BERT与传统的注意力模型有所不同,它并非在RNN的隐藏状态上直接连接注意力机制。BERT拥有多层注意力结构(12层或24层,取决于模型),并且在每个层(12层或16层)中都包含有多个“头”。由于模型的权重不在层与层之间共享,一个BERT模型相当于拥有24×16=384种不同的注意力机制。
BERT可视化
BERT模型较为复杂,难以直接理解它学习的权重的含义。深度学习模型的可解释性通常不强,但我们可以通过一些可视化工具对其进行理解。Tensor2Tensor提供了出色的工具对注意力进行可视化,我结合PyTorch对BERT进行了可视化。点击查看详情。
该工具将注意力可视化为连接被更新位置(左)和被关注位置(右)之间的连线。不同的颜色对应不同的“注意力头”,线段宽度反映注意力值的大小。在该工具的顶部,用户可以选择模型层,以及一个或者多个“注意力头”(通过点击顶部颜色切换,一共包含12个不同的“头”)
BERT到底学习什么?
该工具能用于探索预先训练的BERT模型的各个层以及头部的注意模式。以下列输入值为例进行详解:
句子A:I went to the store.
句子B:At the store, I bought fresh strawberries.
BERT采用WordPiece tokenization对原始句子进行解析,并使用[CLS]对token进行分类以及[SEP]对token进行分隔,则输入的句子变为:[CLS] i went to the store. [SEP] at the store, i bought fresh straw ##berries. [SEP]
接下来我将确定6个关键模式,并展示每个模式特定层/头的可视化效果。
模式1:下一个单词的注意力(Attention to next word)
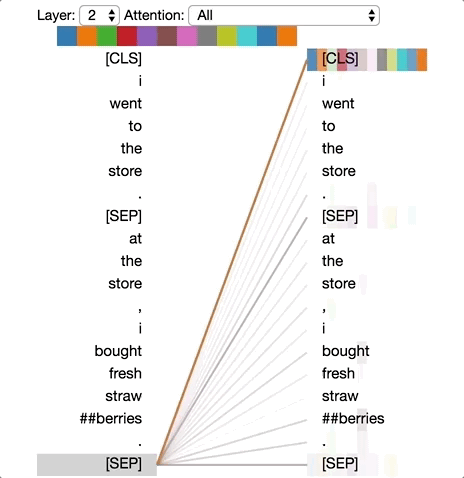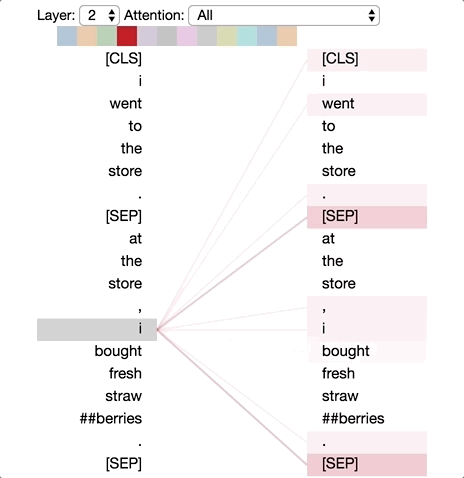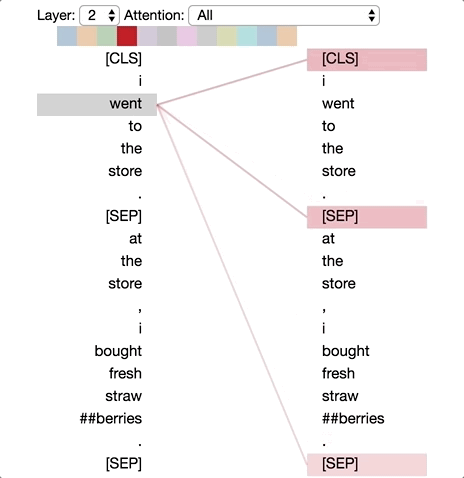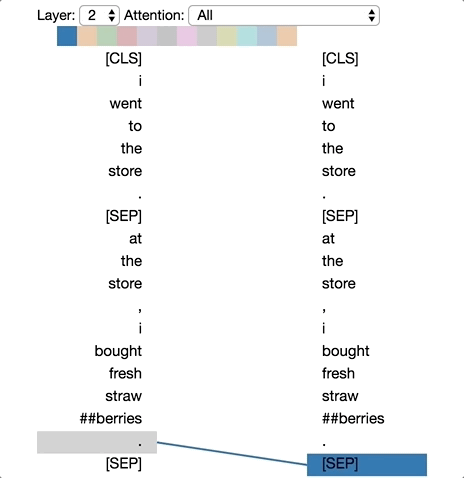
在该模式下,特定单词的大部分注意力都集中在序列中该单词的下一个token处。如下图所示,我们以第二层的head 0为例(所选头部由顶部颜色栏中突出显示的正方形表示)。左边图中展示了所有token的注意力,右边则显示了特定token(“i”)的注意力。“i”几乎所有的注意力都集中在它的下一个token,即“went”处。

左图中,[SEP]指向了[CLS],而非“at”,也就是说,指向下一个单词的这种模式只在句子中起作用,而在句子间的效果较弱。该模式类似于RNN中的backward,状态从右往左依次更新。
模式2:前一个单词的注意力(Attention to previous word)
在该模式下,特定单词的大部分注意力都集中在序列中该单词的前一个token处。本例中,“went”的大部分注意力集中于它的前一个单词“i”。模式2不如模式1明显,特定的单词注意力有所分散。该过程与RNN中的forward类似。

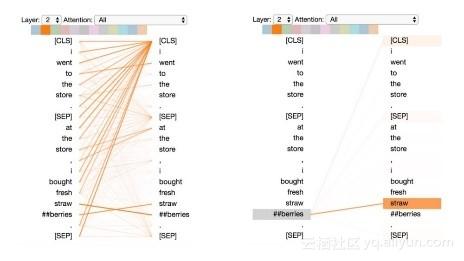
模式3:相同/相关单词的注意力(Attention to identical/related words)
在该模式下,特定单词的大部分注意力集中于与其相同或者相关的单词,包括该单词本身。下图中,“store”的大部分注意力集中在它本身。由于注意力有所分散,该模式也不明显。
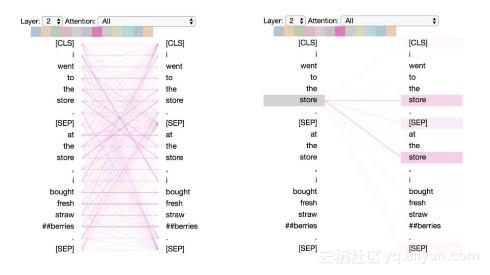
模式4:其它句子中相同/相关单词的注意力(Attention to identical/related words in other sentence)
在该模式中,注意力集中在其它句子中与指定单词相同或者相似的单词。如下图,第二个句子中的“store”与第一个句子中的“store”关联最强。这对于下一个句子预测任务非常有帮助,它能够帮助识别句子之间的关系。
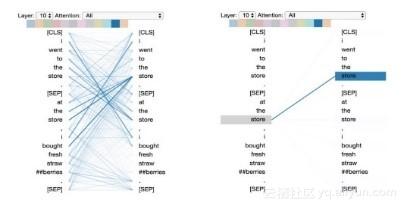
模式5:预测单词的注意力(Attention)
在该模式下,注意力集中于其它可以预测源单词的单词上,且不包括源单词本身。如下图,“straw”的注意力主要集中于“##berries”,而“##berries”的注意力主要集中于“straw”。
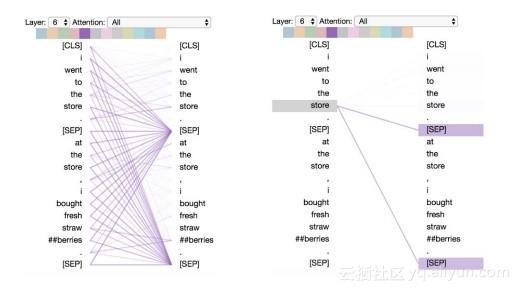
模式6:分隔符标记的注意力(Attention to delimiter tokens)
在该模式下,特定单词的注意力主要集中于分隔符,[CLS]或[SEP]中。如下图,大多数的注意力都集中在两个[SEP]中,这或许是模型将语句级别状态传递到各个token中的一种方法。
作者信息
Jesse Vig
本文由阿里云云栖社区组织翻译。
文章原标题《Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters》,译者:Elaine,审校:袁虎。















 3966
3966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









