






毕加索的作品风格丰富多样,后人常用“毕加索永远是年轻的”的说法形容毕加索多变的艺术形式,可见一斑。那么想不想看看出自毕加索的蒙娜丽莎?想不想让毕加索做个动漫?本文将用最简单的方法带大家实现这个小小愿望。


 详情请参考StyleProNet论文:
https://arxiv.org/abs/2003.07694
详情请参考StyleProNet论文:
https://arxiv.org/abs/2003.07694
 模型中定义的python接口为:
模型中定义的python接口为:
 save_path表示我们保存图片的位置,且仅当visualization为True时,此值存在。
save_path表示我们保存图片的位置,且仅当visualization为True时,此值存在。
 推荐阅读
推荐阅读
实践效果
毕加索画风的蒙娜丽莎
毕加索画风的BadApple MV
实践方法
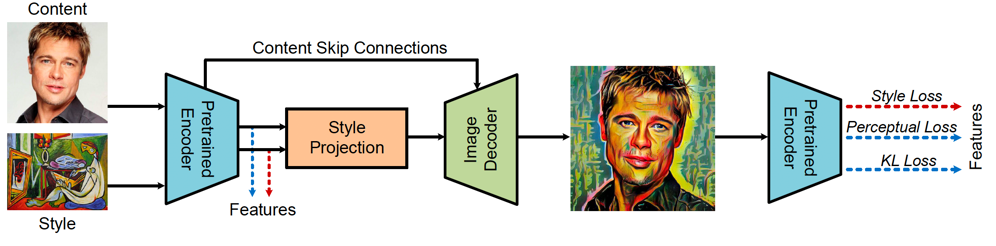
想要实现毕加索风格的蒙娜丽莎和动漫,不仅需要数据,还要搭建网络结构,在这里给小伙伴们推荐一个好玩的Hub — PaddleHub。 PaddleHub中有很多CV和NPL方向的预训练模型。 在这里我使用的是stylepro_artistic模型,该模型整体采用全卷积神经网络架构(FCNs),通过encoder-decoder重建艺术风格图片。 StyleProNet的核心是无参数化的内容-风格融合算法Style Projection ,模型规模小、响应速度快。模型训练的损失函数包括style loss、content perceptual loss和content KL loss,确保模型高保真还原内容图片的语义细节信息与风格图片的风格信息。预训练数据集采用MS-COCO数据集作为内容端图像,WikiArt数据集作为风格端图像,二者可以任意转换。
详情请参考StyleProNet论文:
https://arxiv.org/abs/2003.07694
模型中定义的python接口为:
def style_transfer(self,
images=None,
alpha=1,
use_gpu=False,
visualization=True,
output_dir='transfer_result'):- images (list[dict]): ndarray 格式的图片数据。每一个元素都为一个 dict,有关键字 content, styles, weights(可选),相应取值为:
- content (numpy.ndarray): 待转换的图片,shape 为 [H, W, C],BGR格式;
- styles (list[numpy.ndarray]) : 作为底色的风格图片组成的列表,各个图片数组的shape 都是 [H, W, C],BGR格式;
- weights (list[float], optioal) : 各个 style 对应的权重。当不设置 weights 时,默认各个 style 有着相同的权重。
- alpha (float) : 转换的强度,[0, 1] 之间,默认值为1;
- use_gpu (bool): 是否使用 GPU,使用GPU可以用来加快处理速度;
- visualization (bool): 是否将结果保存为图片,默认为 False;
- output_dir (str): 图片的保存路径,默认设为 transfer_result 。
1. 毕加索画风的蒙娜丽莎实现
风格迁移代码:# 导入必要的包import cv2import paddlehub as hub# 导入并加载模型
stylepro_artistic = hub.Module(name="stylepro_artistic")# 风格转换
result = stylepro_artistic.style_transfer(
images=[{'content': cv2.imread('target.jpg'), # 载入《蒙娜丽莎》图像'styles': [cv2.imread('style.jpg')], # 风格采用了《双臂抱胸的女人》'weights':[1] # 由于上面只选取了一个图片,所以这里只能有一个数字组成的数组
}],
alpha = 1.0,
use_gpu = False,
visualization=True,
output_dir='transvideo_result')[{'data': array([[[108, 166, 133],
[ 62, 107, 84],
[133, 169, 134],
...,
[ 83, 141, 159],
[ 85, 145, 169],
[ 85, 142, 169]],
[[106, 164, 132],
[ 64, 109, 84],
[134, 170, 136],
...,
[ 91, 142, 161],
[ 90, 144, 169],
[ 90, 142, 170]],
[[109, 164, 133],
[ 65, 110, 86],
[136, 171, 139],
...,
[ 95, 141, 160],
[100, 147, 173],
[ 95, 144, 172]],
...,
[[ 71, 71, 82],
[ 72, 72, 83],
[ 71, 66, 74],
...,
[ 31, 30, 40],
[ 84, 93, 113],
[ 64, 77, 111]],
[[ 71, 71, 83],
[ 71, 71, 85],
[ 70, 65, 75],
...,
[ 30, 29, 39],
[ 87, 96, 117],
[ 69, 84, 119]],
[[ 71, 71, 83],
[ 72, 71, 85],
[ 70, 64, 76],
...,
[ 31, 30, 39],
[ 87, 97, 118],
[ 71, 83, 118]]], dtype=uint8), 'save_path': 'transfer_result/ndarray_1588391023.5056114.jpg'}]import matplotlib.pyplot as plt
plt.imshow(result[0]['data'])2. 毕加索画风的BadApple MV实现
首先我们通过cv2的视频读取功能,将视频的每一帧都进行与同一张照片的融合,然后再将融合的图片再整合成视频,就搞定了。每帧融合代码:
这是一个漫长的过程,如果只是用单CPU需要16个小时,如果 使用GPU加速不到1个小时 就可以了(可以去AI Studio蹭个算力:)。%env CUDA_VISIBLE_DEVICES=0 # 指定GPU,很重要# 导入必要的包import cv2import paddlehub as hubfrom tqdm import tqdm
stylepro_artistic = hub.Module(name="stylepro_artistic")
video = cv2.VideoCapture("work/badapple.mp4")# 获取帧数/s
fps = video.get(cv2.CAP_PROP_FPS)# 获取总帧数
frameCount = video.get(cv2.CAP_PROP_FRAME_COUNT)# 获取视频的尺寸信息
size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))
print("总共的帧数为:",frameCount)
success, frame = video.read()
file_paths = []
index = 0for i in tqdm(range(int(frameCount))):# 判断是否读取帧成功,且前33帧为黑屏帧,这里不做处理,加快进度if success and index > 33:
result = stylepro_artistic.style_transfer(
images=[{'content': frame,'styles': [cv2.imread('work/pics/8.jpg')]
}],
use_gpu=True, # 有GPU时,简易使用GPU可以加速
visualization=True,
output_dir='transvideo_result')
file_paths.append(result[0]['save_path'])elif success:
filep = 'transvideo_result/'+str(index)+'.jpg'
cv2.imwrite(filep, frame)
file_paths.append(filep)
success, frame = video.read()
index += 1整合代码:
这一过程就很快了,主要是将每一帧加载在一起,形成视频。import os
import cv2
import datetime
file_dict = {}
video = cv2.VideoCapture("work/badapple.mp4")
fps = video.get(cv2.CAP_PROP_FPS)
frameCount = video.get(cv2.CAP_PROP_FRAME_COUNT)
size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))# 读取图像并根据unix时间戳进行排序for i in os.listdir('transvideo_result/'):
file_dict['transvideo_result/'+i] = float(i.replace('ndarray_','').replace('.jpg',''))
file_dict = sorted(file_dict.items(),key = lambda x:x[1])
videoWriter = cv2.VideoWriter('trans.avi', cv2.VideoWriter_fourcc(*"MJPG"), fps, size)
flag = Truefor i in file_dict:if flag:# 前34帧我们直接填充黑屏帧for j in range(34):
videoWriter.write(cv2.imread('work/target/0.jpg'))
flag = False
videoWriter.write(cv2.imread(i[0]))
videoWriter.release()实践总结
大家在使用AI Studio的过程需要注意下面两点: 1. 使用GPU时,一定要设置GPU环境变量 (%env CUDA_VISIBLE_DEVICES=0)。 2. 图像整合为视频时,最后一定要有释放对象这一命令 (videoWriter.release()),不然整合后的视频无法打开。 从PaddleHub的stylepro_artistic模型的预测效果看,蒙娜丽莎的微笑与毕加索的画风很像,但是在动漫中效果并不十分理想,但是大胆的着色跟毕加索风格还是很相似的。总之,PaddleHub还是给了我非常多的惊喜,同学们也可以动手试试看:)本文作者
姚晓雨,中国科学技术大学材料学博士研究生,主要研究深度学习在材料设计领域的应用
推荐阅读
源码解析容器底层cgroup的实现
Perl 7正在路上,6呢?
Windows Terminal 2.0路线图公布
Git中写下master的开发者反省“错误”,这些术语错了吗?
微软正式推出gRPC-Web for .NET


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









