





Pubmed 摘要文本分析是文本挖掘(生物医学方向)的基础任务。Hiplot 近期上线了一个网页工具 Pubmed Text-Extract 用于完成一些基础的 PubMed 摘要分析工作:将 PubMed 摘要格式化为 Excel 文件、提取感兴趣关键词共存的具体句子、提取 URLs。
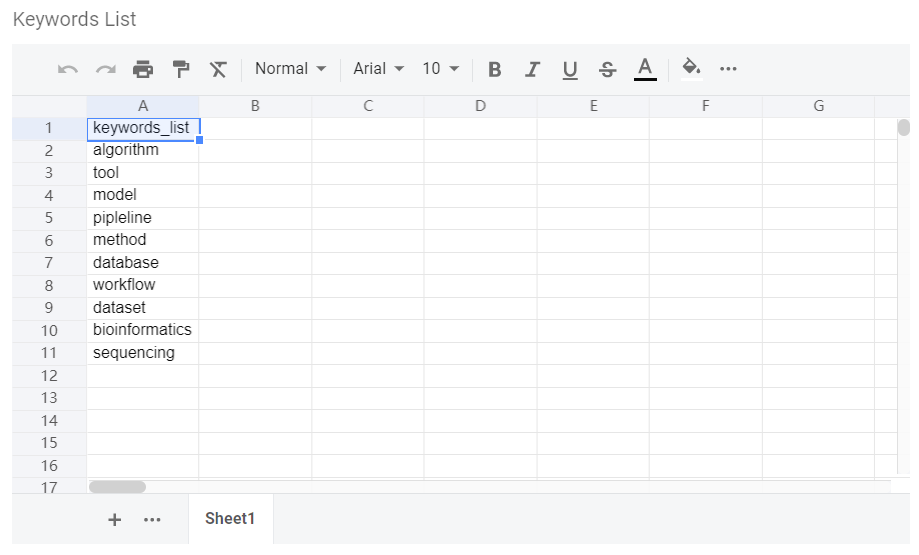
数据输入:PubMed 检索词 + 感兴趣关键词(如基因名+某些表型)。
知乎视频www.zhihu.com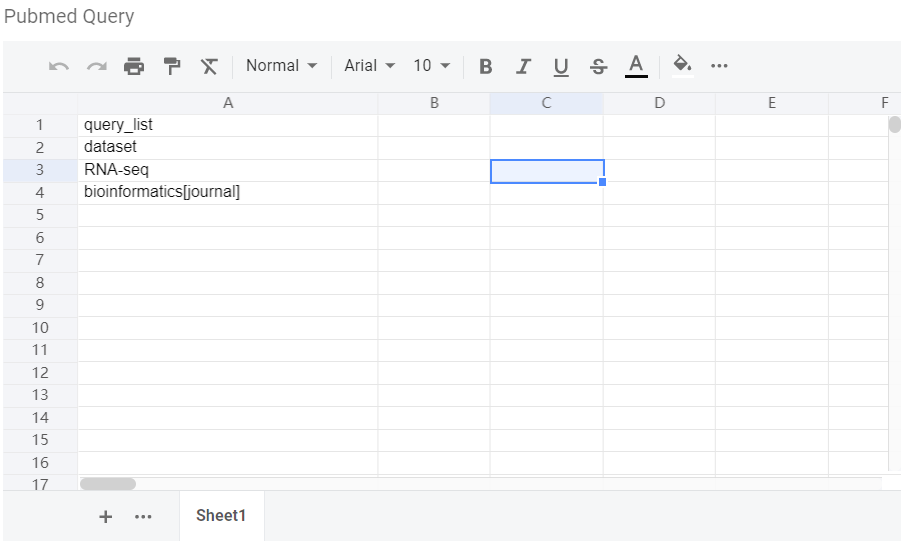
其他参数:
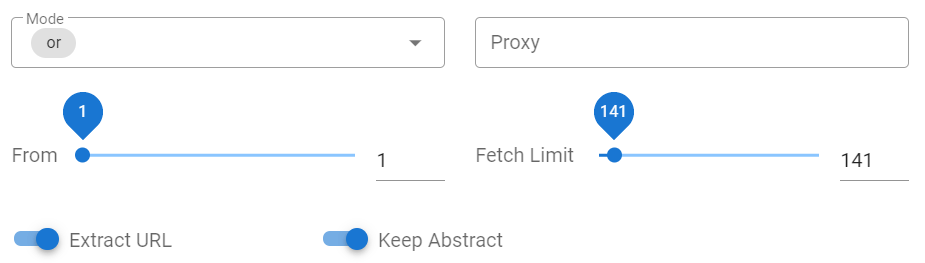
- Mode 可以用于设置 PubMed 检索词的组合关系(AND 和 OR 可选)。
- Proxy 用于设置网络代理。如果在拉取的条目数较多时,推荐设置该参数。因为我们的服务器访问 PubMed 速度不是太快,可能会导致数据请求不全或拖慢任务完成的速度。
- From 参数用于设置抓取记录的起始点(最大限制为 9999)。
- Fetch Limit 用于控制任务拉取的最大条目数(最大 2000)。
- Extract URL 用于控制是否提取摘要文本中的 URL 链接。
- Keep Abstract 用于控制是否保留摘要文本。
结果输出:
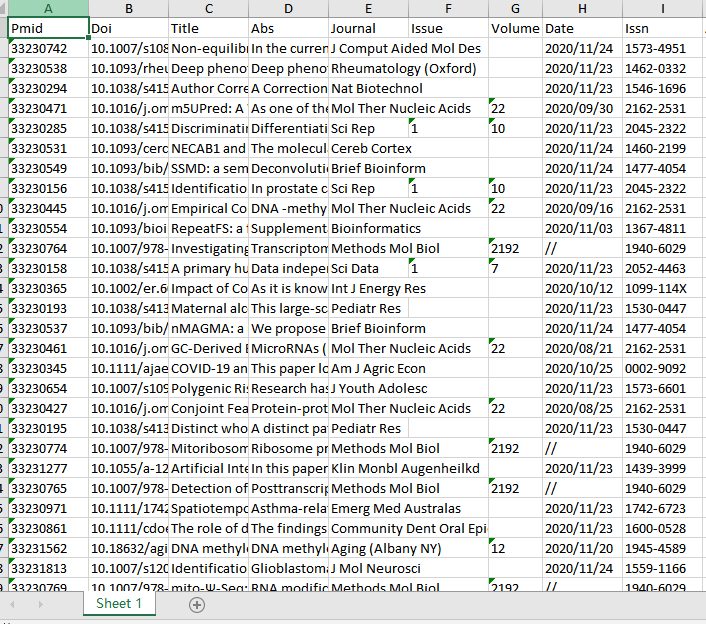
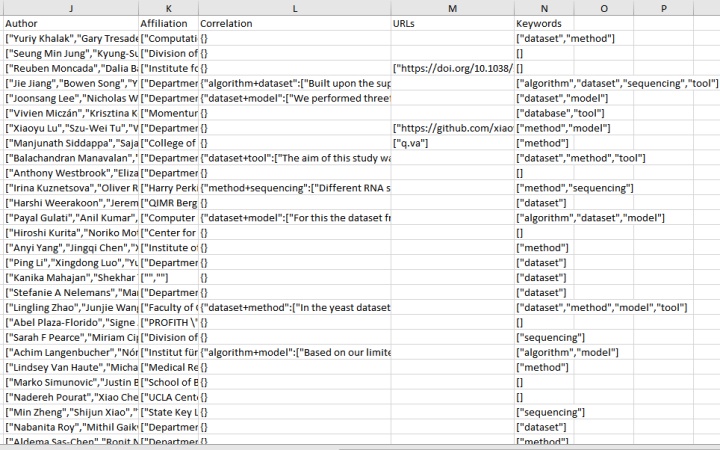
结果文件将主要包括以下数据列:
- Pmid
- Doi
- Title
- Abs
- Journal
- Issue
- Volume
- Date
- Issn
- Author
- Affiliation
- Correlation
- URLs
- Keywords
其中 Keywords 为文本中检测到的关键词(如 ["algorithm","model"]),Correlation 字段将包含所有关键词及其出现的具体句子,如
{"algorithm+dataset":["Built upon the support vector machine (SVM) algorithm and the biochemical encoding scheme, m5UPred achieved reasonable prediction performance with the area under the receiver operating haracteristic curve (AUC) greater than 0.954 by 5-fold cross-validation and independent testing datasets."]}
URLs 为提取的 URL 链接结果,如 ["https://github.com/xiaoyulu95/SSMD"]。
Hiplothiplot.com.cn














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









