







实际上,当你打开这个表,会比较失望,因为根本看不懂这张表里面记录了什么,所以知道这张表的存在就好,实际上我们不需要看这样的表,去对应的View --- pg_stats 才是给相关人员可以识别的数据。
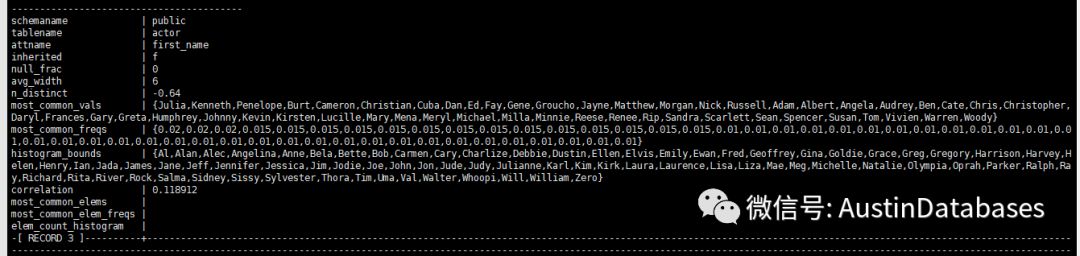
借用上图来看看能从这个pg_stats 读出一些什么。
1 表所处的schema
2 表名
3 表的字段名
4 这列的数据的平均宽度(bytes单位)
5 表中的这列值(高频)占总体的行数比,一般用负数来表示,这里 -0.64表示,first_name 这列里面的值平均分布为 0.64%
6 这列的值的体现于具体的占比,与直方图与那些值进行了绑定(值的分配区间)
7 数据的物理存储于列的值分布顺序
等等这些信息。有了这些信息,则对这个表是要走索引或者是表扫描,已经有了底。
另外POSTGRESQL还有自己的特性,继承,由于文字的长度这里就不提了。
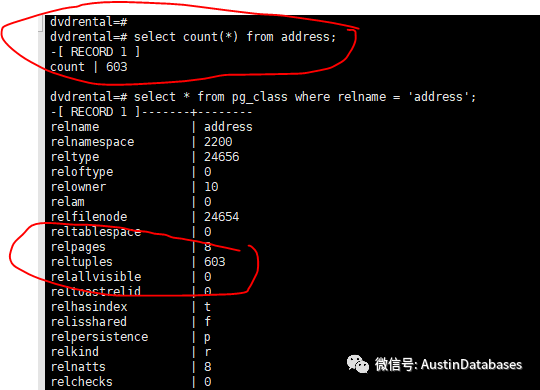
这里提一句题外话,使用MYSQL 其实如果 select count(*) 一个大表要求的数据不是很严谨,只是一个大概的值的要求,可以从系统表里面提取一个表的行数,这里postgresql 也可以这样做。(这样的行数的值不一定准确,使用的时候要看逻辑,如果特别要精准的,就不要考虑了)
这时一定有人会问,
1 怎么收集统计信息
2 统计信息怎么能更精确
3 是否可以差异化来做,避免对所有表进行统计信息
1 一般来说收集表的统计信息,使用的命令 analyze 来进行,对大表,ANALYZE会对表内容进行随机抽样,不会监测每一行。所以analyze 大表的速度并不会特别慢。而analyze 如果不指定表名,则针对当前数据库的所有表,分区表,继承表,物化视图等。所以建议如果没有特殊的需求,还是给出表名,有针对的进行手动的统计数据更新。

另外根据POSTGRESQL 的版本不同,PG 12 是可以在analyze 时进行 skip_locked 的设置,但PG12 以下的版本是不可以的。所以如果你还没有使用PG 并且要上PG 那越新的版本,也会让你有更多惊喜。
2 - 3 统计信息上面说了,是对表的内容进行随机抽样,而如何让一个表的统计信息更准确,则需要针对你的需要,来调整某个表,可能有人想,都调整了不行吗,这里会牵扯两个问题
1 是否有必要 ,一个基础表,你要那么详尽的统计信息,并且他也长时间不变化,所以调整必然是针对某些业务表,并且是数据量大的,经常被查询的
2 统计信息的精确度,精确度越高,耗费的存储空间就会越大,统计的时间就会越长。
这里默认的统计的质量是100 ,我们可以通过alter table命令来将默认值进行改变,在执行ANALYZE 这个表就会以新的统计质量来收集数据。
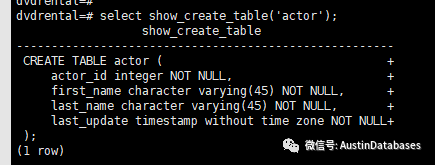

通过对表中的某个字段(这个字段要不就是经常查询的,并且有具体的代表性意义的,如果是性别,或者值分布比价单一的,就不建议了)进行状态收集的精度的调整。
这样就可以有针对性的对一些表进行特殊的统计信息的处理,也可以手动定期的对表进行统计信息的收集。(可以写脚本,晚间定期运行)
那可能还有人要问,我设置了,怎么知道设置OK 了
OK 今天就到这里,其实还有扩展 statistics 今天就不说了。
I Love PG关于我们
中国开源软件推进联盟PostgreSQL分会(简称:PG分会)于2017年成立,由国内多家PG生态企业所共同发起,业务上接受工信部产业发展研究院指导。PG分会致力于构建PG产业生态,推动PG产学研用发展,是国内一家PG行业协会组织。
欢迎投稿
做你的舞台,show出自己的才华 。
投稿邮箱:partner@postgresqlchina.com
——愿能安放你不羁的灵魂
技术文章精彩回顾PostgreSQL学习的九层宝塔PostgreSQL职业发展与学习攻略搞懂PostgreSQL数据库透明数据加密之加密算法介绍一文读懂PostgreSQL-12分区表PostgreSQL源码学习之:RegularLockPostgresql源码学习之词法和语法分析PostgreSQL buffer管理最佳实践—PG数据库系统表空间重建PostgreSQL V12中的流复制配置2019,年度数据库舍 PostgreSQL 其谁?PostgreSQL使用分片(sharding)实现水平可扩展性一文搞懂PostgreSQL物化视图PostgreSQL原理解析之:PostgreSQL备机是否做checkpointPostgreSQL复制技术概述PG活动精彩回顾见证精彩|PostgresConf.CN2019大会盛大开幕PostgresConf.CN2019大会DAY2|三大分论坛,精彩不断PostgresConf.CN2019培训日|爆满!Training Day现场速递!「PCC-Training Day」培训日Day2圆满结束,PCC2019完美收官创建PG全球生态!PostgresConf.CN2019大会盛大召开首站起航!2019“让PG‘象’前行”上海站成功举行走进蓉城丨2019“让PG‘象’前行”成都站成功举行中国PG象牙塔计划发布,首批合作高校授牌仪式在天津举行PostgreSQL实训基地落户沈阳航空航天大学和渤海大学,高校数据库课改正当时群英论道聚北京,共话PostgreSQL相聚巴厘岛| PG Conf.Asia 2019 DAY0、DAY1简报相知巴厘岛| PG Conf.Asia 2019 DAY2简报相惜巴厘岛| PG Conf.Asia 2019 DAY3简报独家|硅谷Postgres大会简报全球规模最大的PostgreSQL会议等你来!PG培训认证精彩回顾关于中国PostgreSQL培训认证,你想知道的都在这里!首批中国PGCA培训圆满结束,首批认证考试将于10月18日和20日举行!中国首批PGCA认证考试圆满结束,203位考生成功获得认证!中国第二批PGCA认证考试圆满结束,115位考生喜获认证!请查收:中国首批PGCA证书!重要通知:三方共建,中国PostgreSQL认证权威升级!一场考试迎新年 | 12月28日,首次PGCE中级认证考试开考!近500人参与!首次PGCE中级、第三批次PGCA初级认证考试落幕!















 253
253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









