





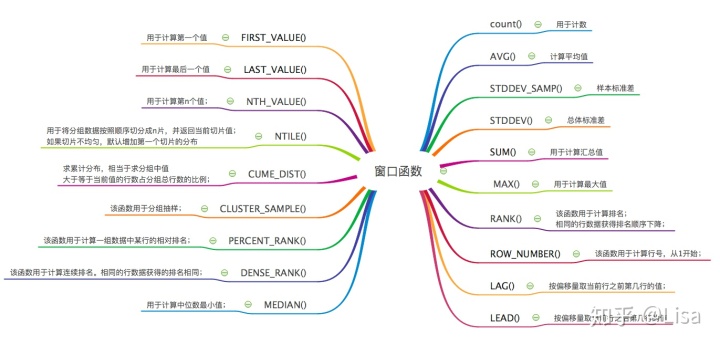
ODPS SQL 窗口函数
1. count():用于计数
-- 准备表
create table if not exists tmp_data3(
id bigint,
num double
)
;
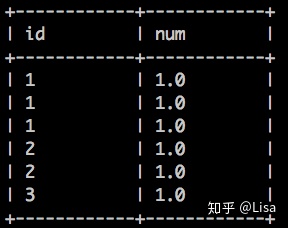
-- 插入数据
insert into table tmp_data3
(id,num)
VALUES
(1,1),
(1,1),
(1,1),
(2,1),
(2,1),
(3,1)
;
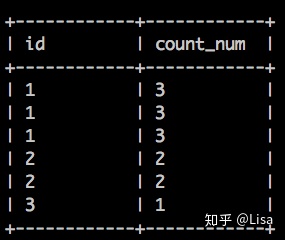
-- count()窗口函数查询
select
id,
count(num) over (partition by id) as count_num
from tmp_data3
;
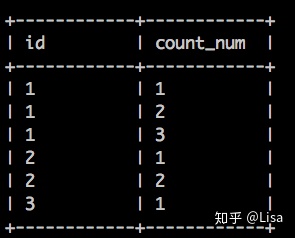
-- count()窗口函数查询加上order by
-- 加上order by 时,返回累计计数值
select
id,
count(num) over (partition by id order by id asc) as count_num
from tmp_data3
;
--********************************************************************--
2. AVG():计算平均值
-- 准备表
create table if not exists tmp_data3(
id bigint,
num double
)
;
-- 插入数据
insert into table tmp_data3
(id,num)
VALUES
(1,1.5),
(1,2.0),
(1,3.0),
(2,4.0),
(2,5.0),
(3,6.0)
;
-- 数据查询
select * from tmp_data3;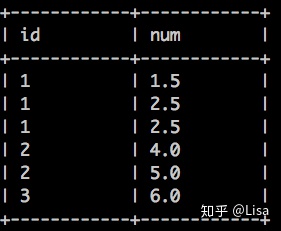
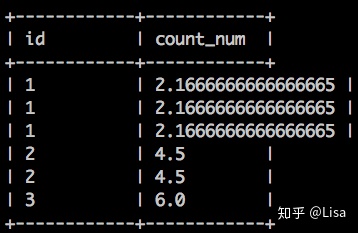
-- AVG()窗口函数查询
select
id,
AVG(num) over (partition by id ) as count_num
from tmp_data3
;
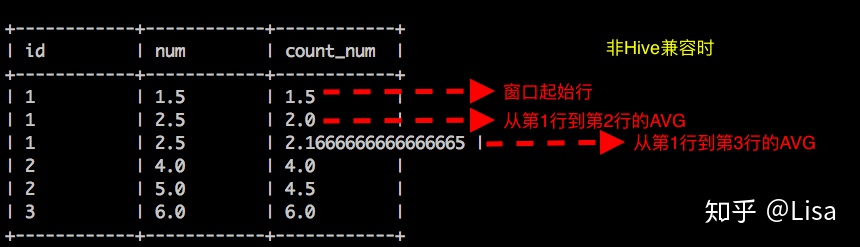
-- AVG() 加上 order by
-- 当非Hive兼容时,返回值为各自行的AVG。
set odps.sql.hive.compatible=false;
select
id,
num,
AVG(num) over (partition by id order by num asc) as count_num
from tmp_data3
;
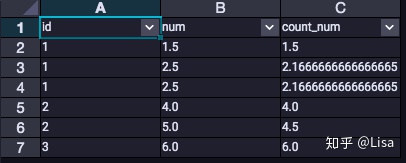
-- 当Hive兼容时,返回值为相同值的最后一行的AVG
set odps.sql.hive.compatible=true;
select
id,
num,
AVG(num) over (partition by id order by num asc) as count_num
from tmp_data3
;
--********************************************************************--
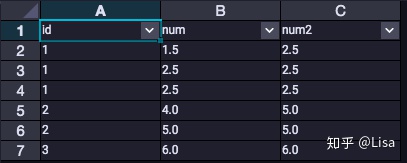
3. MAX():用于计算最大值
select
id,
num,
MAX(num) over (partition by id) as num2
from tmp_data3
;
--********************************************************************--
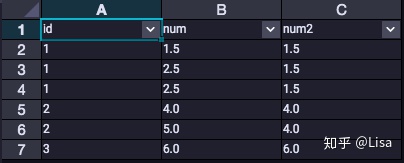
4. MIN():用于计算最小值
-- MIN ()
select
id,
num,
MIN(num) over (partition by id order by num asc) as num2
from tmp_data3
;
--********************************************************************--
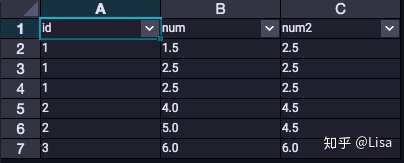
5. MEDIAN():用于计算中位数最小值
-- MEDIAN()
select
id,
num,
MEDIAN(num) over (partition by id) as num2
from tmp_data3
;
--********************************************************************--
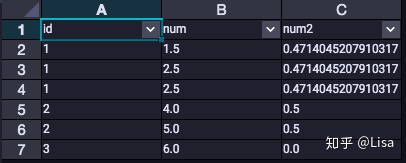
6.STDDEV():总体标准差
select
id,
num,
STDDEV(num) over (partition by id) as num2
from tmp_data3
;
--********************************************************************--
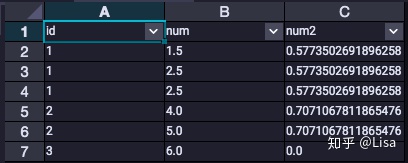
7.STDDEV_SAMP():样本标准差
select
id,
num,
STDDEV_SAMP(num) over (partition by id) as num2
from tmp_data3
;
--********************************************************************--
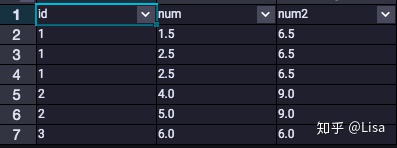
8.SUM():用于计算汇总值
select
id,
num,
SUM(num) over (partition by id) as num2
from tmp_data3
;
--********************************************************************--
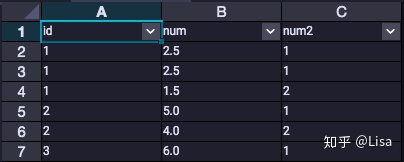
9.DENSE_RANK():该函数用于计算连续排名。相同的行数据获得的排名相同。
select
id,
num,
DENSE_RANK() over (partition by id order by num desc) as num2
from tmp_data3
;
--********************************************************************--
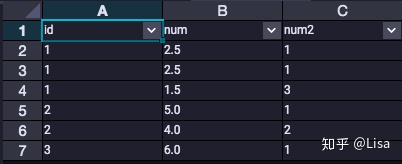
10.RANK():该函数用于计算排名。相同的行数据获得排名顺序下降。
select
id,
num,
RANK() over (partition by id order by num desc) as num2
from tmp_data3
;
--********************************************************************--
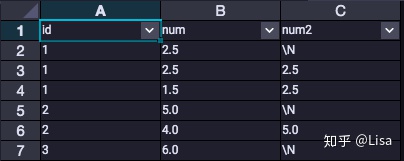
11.LAG():按偏移量取当前行之前第几行的值。
select
id,
num,
LAG(num,1,null) over (partition by id order by num desc) as num2
from tmp_data3
;
--********************************************************************--
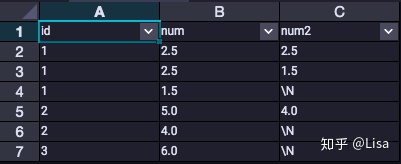
12.LEAD():按偏移量取当前行之后第几行的值。
select
id,
num,
LEAD(num,1,null) over (partition by id order by num desc) as num2
from tmp_data3
;
--********************************************************************--
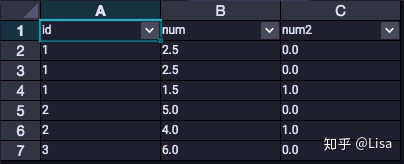
13.PERCENT_RANK():该函数用于计算一组数据中某行的相对排名。
select
id,
num,
PERCENT_RANK() over (partition by id order by num desc) as num2
from tmp_data3
;
--********************************************************************--
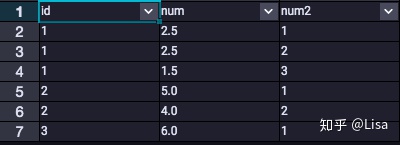
14.ROW_NUMBER():该函数用于计算行号,从1开始。
select
id,
num,
row_number() over (partition by id order by num desc) as num2
from tmp_data3
;
--********************************************************************--
15.CLUSTER_SAMPLE():该函数用于分组抽样。
select
id,
num,
cluster_sample(10,1) over (partition by id) as num2
from tmp_data3
;
-- 从窗口中抽取10%的值,并从每组窗口中抽取1份记录;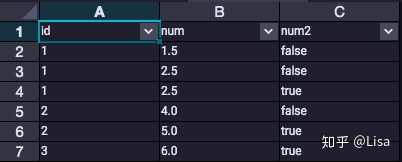
--********************************************************************--
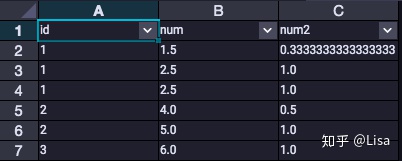
16.CUME_DIST():求累计分布,相当于求分组中值大于等于当前值的行数占分组总行数的比例。
例子:求自己的工资在同一组内的前百分之几;
select
id,
num,
cume_dist() over (partition by id order by num asc) as num2
from tmp_data3
;
--********************************************************************--
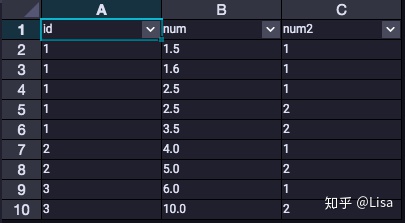
17.NTILE():用于将分组数据按照顺序切分成n片,并返回当前切片值。如果切片不均匀,默认增加第一个切片的分布。
例子:计算自己的工资在组内的序号;
-- 准备表
create table if not exists tmp_data3(
id bigint,
num double
)
;
-- 插入数据
insert into table tmp_data3
(id,num)
VALUES
(1,1.5),
(1,1.6),
(1,2.5),
(1,2.5),
(1,3.5),
(2,4.0),
(2,5.0),
(3,6.0),
(3,10.0)
;
-- 查询
select
id,
num,
ntile(2) over (partition by id order by num asc) as num2
from tmp_data3
;
--********************************************************************--
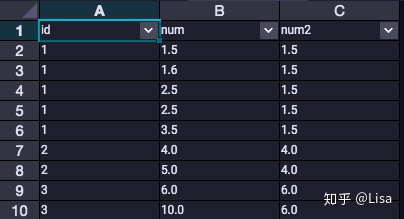
18.FIRST_VALUE():用于计算第一个值。
select
id,
num,
first_value(num) over (partition by id ) as num2
from tmp_data3
;
--********************************************************************--
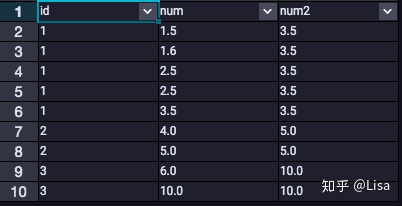
19.LAST_VALUE():用于计算最后一个值。
select
id,
num,
LAST_VALUE(num) over (partition by id ) as num2
from tmp_data3
;
--********************************************************************--
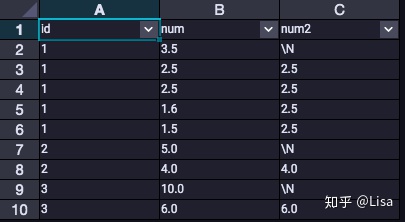
20.NTH_VALUE():用于计算第n个值。
select
id,
num,
NTH_VALUE(num,2) over (partition by id order by num desc) as num2
from tmp_data3
;
--********************************************************************--














 1919
1919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









