





寄存器设计验证在IC前端周期占据着相当的分量。如果能通过输入某种格式的文件,输出寄存器RTL, uvm register model, HTML描述,FW API...那对工作效率将是极大的提升。这里以uvm register model为例,介绍一种通过python模板制作代码生成器的方法,抛砖引玉。
输入格式选择
常用的寄存器输入格式有:tcl, excel, XML(IP_XACT). synopsys的ral gen一开始采用的就类似tcl的语法,处理起来很方便,然而写输入的人大概会很痛苦。不过最痛苦的莫过于直写XML,读起来头都要大两圈,通常会作为GUI工具的中间文件。为了使用者方便,这里选择了excel作为最终格式。
既然要用excel格式,那么需要使用第三方插件openpyxl处理excel文件,当然如果你习惯使用xlsxwriter, xlrd/xlwt也是一样的。

结构
寄存器在结构上自上而下依次为:block->register->field, 有两个明显的特点,
- 每一层结构又带有该层特有的信息
- 每一层节点有1~N个子节点
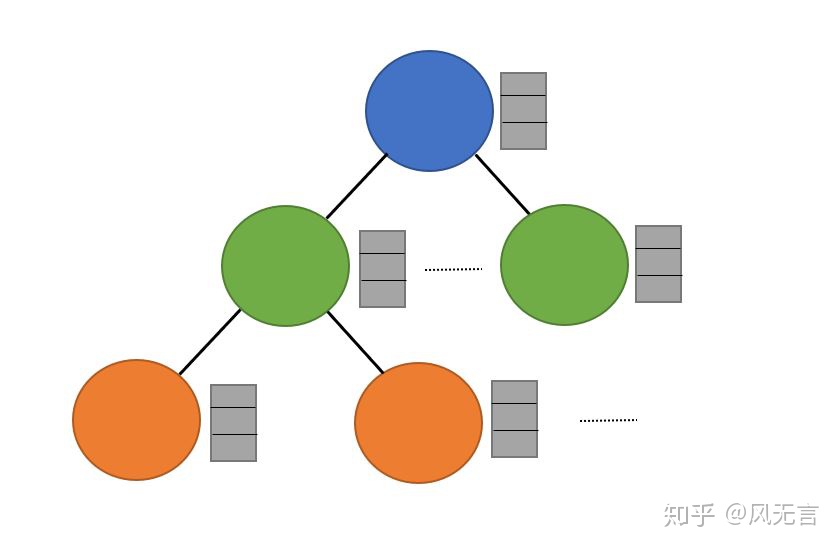
这不就是颗多叉树么?实现的方式多种多样,可以用嵌套字典,也可以用class, 这里采用了后者。接下来构造这样的一棵树:
class 为了未来使用的方便,将Node改造成可迭代的:
def 填充完__setitem__, __getitem__等一众方法之后,一颗寄存器树就做好了。
提取信息
我们的需求,无非是将文件从一种格式的文件映射为另一种格式。就本例而言,就是讲excel的信息抽取出来存入tree中,再讲tree渲染为目标格式文件。
要提取excel的信息,首先要分析表头究竟有哪些信息:
if 这是分析表头函数的代码片段。在excel的表头信息分为两类,一类是有重名的,一类是无重名的。offset属于有重名的一类,block有offset, register也可能有offset.处理这一类型的cell,需要判断其位置来确定他的归属。另一类是无重名的,例如width,这一类只需匹配到关键字就能定位了。
当然,为了简便,我们可以将所有有重名的表头信息加上特定的前缀做成所有信息都是无重名类型。这就需要在使用便捷性与设计的方便之间做出权衡,在项目中我们经常会遇到这样的取舍。
确定完表头,就可以开始从表里提取信息了:
def 这里set_attr()是一个很简单的属性添加方法,实现如下:
def 之所以绕那么大圈子,只因python的lamdba函数不支持直接赋值>.<
稍微要注意一下的是,这里一共有两处权衡。对于reset和offset数据,用户可能会给出不同格式的数据,有可能是hex, dec,也有可能是sv风格的'hxxx.正如前面提到的一样,如果需要支持的类型多,脚本里就要多加判断;反之事先约束好用户的输入,代码就不用写的那么复杂。在这里折中了一下,并不允许'h类型的数据输入,仅支持十进制或0x开头的hex数据。此其一。
def 其二,对于field的范围表示,用户往往习惯于[m:n]给出范围,或者单bit field直接丢出一个十进制数值,而对于reg model来说,输入函数参数需要的是size以及lsb position. 这里采用脚本内部解析来沟通两者需求。
def 代码生成
最后把树的信息输出成特定格式。为了方便将来功能扩展,可以采用模板的方式来实现功能。python有很多种成熟的模板类型:jinja2, mako, cheetah. 因为某种原因,这里采用了jinja2模板。
模板不仅仅是简单的变量替换,他可以使用控制结构,也可以赋值,使用filter和test对渲染出的代码进行控制,否则用sed岂不是更加简单又快捷?例如这里渲染reg中field的例化部分:
virtual 使用for循环遍历reg node中的field node,并将field的信息填入代码,必要的时候还能使用upper()函数将字符串转换为大写,用起来相当直观与顺手。
然后调用template的render方法渲染输入代码,去掉多余的空行:
template_dir 实际操作中会通过write()输出到文件中。
最后附上完整项目代码,DEMO仅供参考,如有需要可以自行制作期望的模板:
seabeam/uvm_reg_gengithub.com














 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









