






开言
下面这一段代码中会报错。
1
2
3
4
5
6
7
8
9
10
11import org.springframework.util.Base64Utils;
import sun.misc.BASE64Encoder;
public class Test{
public static void main(String[] args){
byte[] content = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa".getBytes();
String encrypted = new BASE64Encoder().encode(content);
byte[] decrypted = Base64Utils.decodeFromString(encrypted);
System.out.println(new String(decrypted));
}
}

接下来我们分别查看一些这两个代码,我们发现BASE64Encoder().encode在进行base64编码的时候进行了换行,换行符的ascii编码对应的是0x0a,所以刚好命中这个报错。
sun.misc.BASE64Decoder
代码实现如下,进行分别拆解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public void decodeBuffer(InputStream var1, OutputStream var2) throws IOException{
int var4 = 0;
PushbackInputStream var5 = new PushbackInputStream(var1);
this.decodeBufferPrefix(var5, var2);
while(true) {
try {
int var6 = this.decodeLinePrefix(var5, var2);
int var3;
for(var3 = 0; var3 + this.bytesPerAtom() < var6; var3 += this.bytesPerAtom()) {
this.decodeAtom(var5, var2, this.bytesPerAtom());
var4 += this.bytesPerAtom();
}
if (var3 + this.bytesPerAtom() == var6) {
this.decodeAtom(var5, var2, this.bytesPerAtom());
var4 += this.bytesPerAtom();
} else {
this.decodeAtom(var5, var2, var6 - var3);
var4 += var6 - var3;
}
this.decodeLineSuffix(var5, var2);
} catch (CEStreamExhausted var8) {
this.decodeBufferSuffix(var5, var2);
return;
}
}
}
首先 decodeLinePrefix 返回的是 bytesPerLine 定义的长度72。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public void decodeBuffer(InputStream var1, OutputStream var2) throws IOException{
int var4 = 0;
PushbackInputStream var5 = new PushbackInputStream(var1);
this.decodeBufferPrefix(var5, var2);
while(true) {
try {
int var6 = this.decodeLinePrefix(var5, var2);
protected int decodeLinePrefix(PushbackInputStream var1, OutputStream var2) throws IOException{
return this.bytesPerLine();
}
protected int bytesPerLine(){
return 72;
}
紧接着调用 decodeAtom 进行处理,其中 bytesPerAtom 定义的数值是4。
1
2
3
4
5
6
7
8
9int var3;
for(var3 = 0; var3 + this.bytesPerAtom() < var6; var3 += this.bytesPerAtom()) {
this.decodeAtom(var5, var2, this.bytesPerAtom());
var4 += this.bytesPerAtom();
}
protected int bytesPerAtom(){
return 4;
}
我们看看 decodeAtom 进行处理,先看看 readFully 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18protected void decodeAtom(PushbackInputStream var1, OutputStream var2, int var3) throws IOException{
byte var5 = -1;
byte var6 = -1;
byte var7 = -1;
byte var8 = -1;
if (var3 < 2) {
throw new CEFormatException("BASE64Decoder: Not enough bytes for an atom.");
} else {
int var4;
do {
var4 = var1.read();
if (var4 == -1) {
throw new CEStreamExhausted();
}
} while(var4 == 10 || var4 == 13);
this.decode_buffer[0] = (byte)var4;
var4 = this.readFully(var1, this.decode_buffer, 1, var3 - 1);
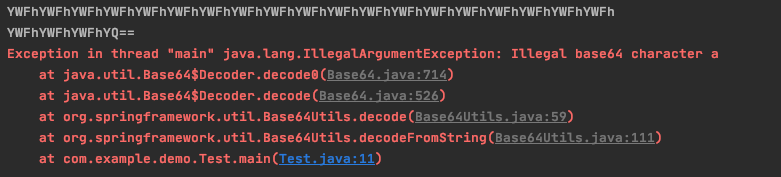
在 readFully 当中,4个字节为一个单位组合,经过处理之后,结果是[89,87,70,104]。
189,87,70,104,61
接着会继续循环,那我们知道,这玩意吗会按照4个字节为一个list去处理,前四个数据处理完之后,接下来的list是[61,,,],也就是说在readFully循环处理的过程中,返回结果是-1
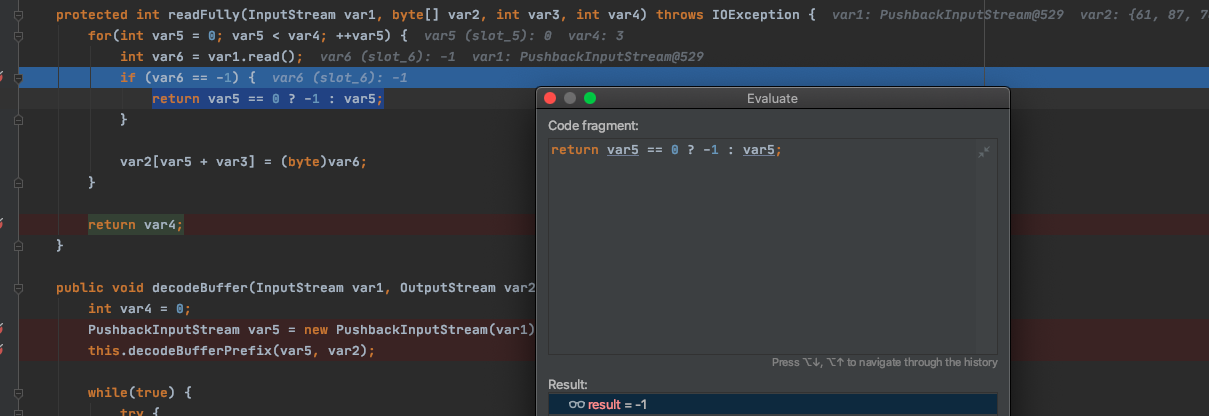
当返回结果是-1的时候会进入 CEStreamExhausted 进行处理。
1
2if (var4 == -1) {
throw new CEStreamExhausted();
处理经过返回null,也就是说在这个异常里面是不会报错退出的。
那我们继续看看,假设我们把后面字节补齐,变成
189,87,70,104,61,61,61,61
可以看到经过处理之后变成[61,61,61,61]

0x61 在ascii编码里面代表 = ,进入到case 2进行处理。
189,87,70,104,61,61,61,61
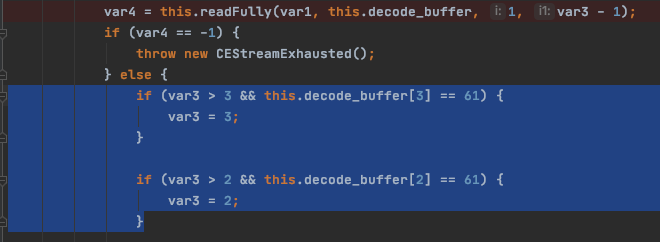

实际可以看到 decode 处理数据是[97,97,97,-1]

java.util.base64.decode
我们在看看java.util.base64.decode这个decode词法解析器,在这里面会进行两种base64判断。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28private int decode0(byte[] src, int sp, int sl, byte[] dst){
int[] base64 = isURL ? fromBase64URL : fromBase64;
int dp = 0;
int bits = 0;
int shiftto = 18; // pos of first byte of 4-byte atom
while (sp < sl) {
int b = src[sp++] & 0xff;
if ((b = base64[b]) < 0) {
if (b == -2) { // padding byte '='
// = shiftto==18 unnecessary padding
// x= shiftto==12 a dangling single x
// x to be handled together with non-padding case
// xx= shiftto==6&&sp==sl missing last =
// xx=y shiftto==6 last is not =
if (shiftto == 6 && (sp == sl || src[sp++] != '=') ||
shiftto == 18) {
throw new IllegalArgumentException(
"Input byte array has wrong 4-byte ending unit");
}
break;
}
if (isMIME) // skip if for rfc2045
continue;
else
throw new IllegalArgumentException(
"Illegal base64 character " +
Integer.toString(src[sp - 1], 16));
}
一种是判断YWFh=中最后的=,也就是说[89,87,70,104,61]这个list经过运算之后如果是=,就会进行下面判断,不符合规则就会报错Input byte array has wrong 4-byte ending unit。
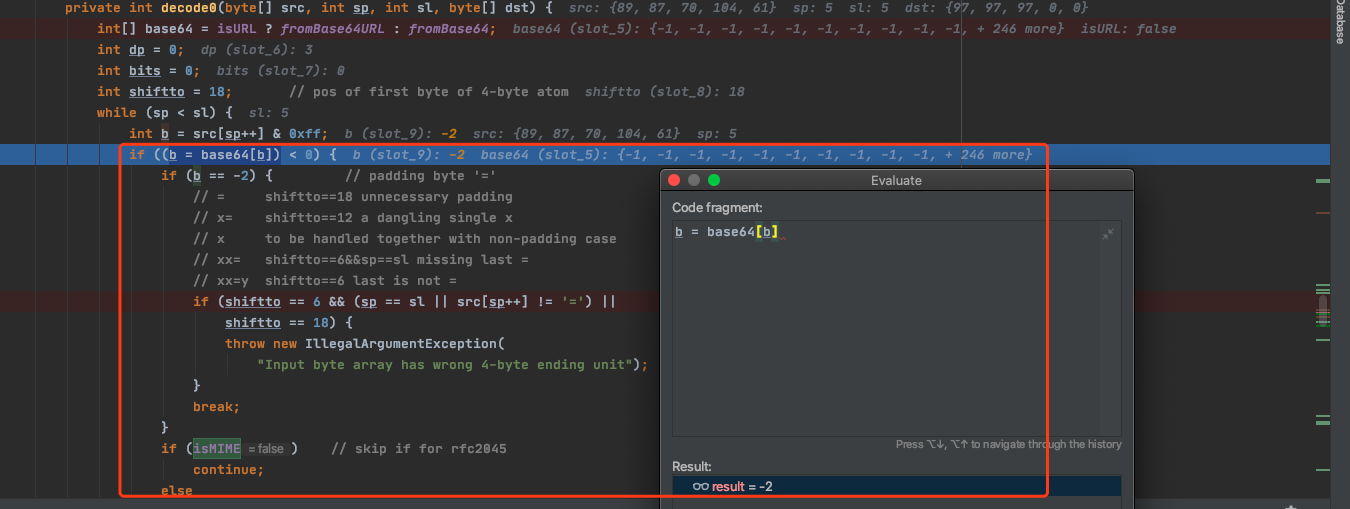
而下面 isMIME 判断是来自Decoder.RFC4648,默认是 false 。
1
2
3
4
5
6
7
8
9public static byte[] decode(byte[] src) {
return src.length == 0 ? src : Base64.getDecoder().decode(src);
}
public static Decoder getDecoder(){
return Decoder.RFC4648;
}
static final Decoder RFC4648 = new Decoder(false, false);
static final Decoder RFC4648_URLSAFE = new Decoder(true, false);
static final Decoder RFC2045 = new Decoder(false, true);
结语
简单做个总结,也就是说用sun.misc.BASE64Decoder这个方法做base64解码的时候,针对base64的兼容性更高,你在base64的字符串后面无论加多少个=都没关系,但是在例如java.util.base64.decode这类型严格按照base64规范的进行解码的方法下,就会出现报错。
那有啥用呢,比如在一些base64编码环境下,可能检测用的是java.util.base64.decode方法,实际后面业务解码用的是sun.misc.BASE64Decoder这样在前后不一致的情况下,会出现绕过的问题。

















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









