






论文标题:A Cascade Approach to Neural Abstractive Summarization with Content Selection and Fusion 源文链接: https:// arxiv.org/abs/2010.0372 2 论文出处:AACL-IJCNLP2020 源码链接:ucfnlp/cascaded-summ 转载请注明出处:学习NLP的皮皮虾
Abstract
这篇文章提出了一个当前摘要研究中的问题,尽管摘要任务中各种方法的实践大不相同,但是除了新闻摘要之外,很少有其他任务能够提供大量训练数据来满足端到端神经摘要模型。
并且作者认为,目前的摘要模型主要功能就是联合内容选择和表面实现(surface realization)来生成摘要。这种范式的摘要模型实际上在评估上有很大的挑战,它要求在评估内容选择准确性的同时评估摘要生成。事实上就是后者还是一个未解难题。
为此,本文提出了一个经验结果,展现了首先独立识别重要内容,然后再将其拼接润色成一个流畅句子的级联pipeline的表现不输于端到端的系统,并且pipeline系统对于内容选择是灵活可控的相比于端到端系统的黑箱性质。
最后还讨论了如何利用级联pipeline来优化以后摘要系统的搭建。
Introduction
近年来有设计优秀的摘要场景比如:放射学报告、国会报告以及会议对话等。但是他们都没有充足的标注数据来满足端到端模型的训练。在缺少标注资源的情况下,端到端模型就不一定是摘要任务的“最优解”了。
为此,越来越多人放弃了端到端的黑盒便利性,选择开发通用的内容选择器和神经文本生成器来挖掘神经生成式摘要的真正潜力。
而这篇文章旨在验证级联pipeline摘要系统的可行性。具体来说研究了一种受限的摘要任务,在这种任务中,通过级联管道一次只创建一个摘要,该pipeline架构从源文档中选择一个或两个句子,然后突出显示它们值得总结的部分,并使用它们作为组成总结句子的基础。需要注意的是,当一对句子被选择时,确保它们是可融合的是很重要的。即有衔接手段将两个句子连接在一起,形成一个连贯的文本,以避免产生无意义的输出。
作者认为突出显示句子片段允许执行细粒度的内容选择,这将指导神经文本生成器将选定的片段润色成连贯的句子。
A Cascade Approach
作者提出的级联方法并不针对深度抽象的要求,而是对文本采用如裁剪、转述以及融合的操作进行浅度抽象,并不需要像深度抽象一样对文档进行完整分析。
这种方法基于选择好的内容进行摘要生成有助于生成包含重要信息的摘要,更重要的是,忠于原文。
对于具体方法,主要分成两个部分:从文档中选择单个句子或句子对,并在高亮显式的情况下执行摘要生成的方法。
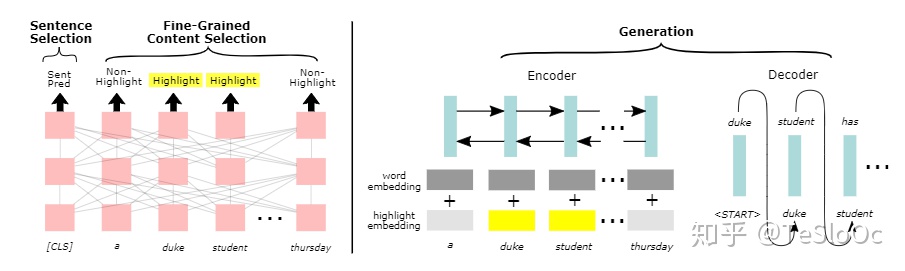
Selection of Singletons and Pairs
作者内容选择的方法是从输入文档中迭代地选择一个或两个句子;它们是组成一个摘要句的基础;存在研究表明,60%到85%的手写摘要都是从原文中对一个句子进行压缩或者对两个句子进行融合。
因此基于这个研究,提出从粗糙到细致的选择策略,这个策略首先选择源文档中的单句和句子对,然后高亮其中重要部分。重要的是,这个策略允许操控哪些片段组合成一个摘要句子;相反,当文档的重要部分同时提供给神经生成器时,可能会发生这样的情况:生成器随意地将不相关的句子中的文本片段拼接在一起,生成包含错误内容的摘要,而无法保留原始文档的含义
因此如果一个句子包含显著的一致性,则期望它从文档中分离出来。此外,一对句子应该包含彼此兼容的内容。给定文档中的一个句子或一对句子,模型预测它是否是一个可以被压缩或合并以形成摘要的有效实例。
这里的判断工作主要交给BERT来执行。BERT除了在多层迭代过程中对输入片段进行细化表示之外,通过[CLS]获得一个全句表示。并通过对本文的任务进行fine-tune以获得一个是否对生成摘要有效的预测分数:
Fine-Grained Content Selection
这部分主要是通过上述BERT获得的,对于每个token细化表示之后的进一步预测操作:
当选择两个句子来生成一个融合句子时,需要从这些句子中识别出可能彼此兼容的文本片段;这种由粗到细的方法允许检查中间结果,并将其与黄金摘要进行比较。
具体来说,这个过程主要是在每个token的最终表示
然后在预测上述一个句子或两个句子的是否需要被选择时再通过一个系数
Information Fusion
然后对于选择器选择得到的单句或者是句子对以及其派生出来的高亮标注,主要通过一个PGN对其内容进行整合生成,具体用法就是在模型中加入一个highlight embedding,对于形如01的highlight序列进行highlight on/off编码,并于word embedding进行融合,一同进行训练。
作者认为这样融合高亮部分信息是直接粗暴但是对于浅度抽象来说确实足够而且有价值的,并且对于前面句子选择器的构建也有许多可替代的方案,并且以序列标注的方法进行内容选择相对来说内容无关性大一些,可以潜在地迁移到新领域中。
Experimental Results
Data and Annotation
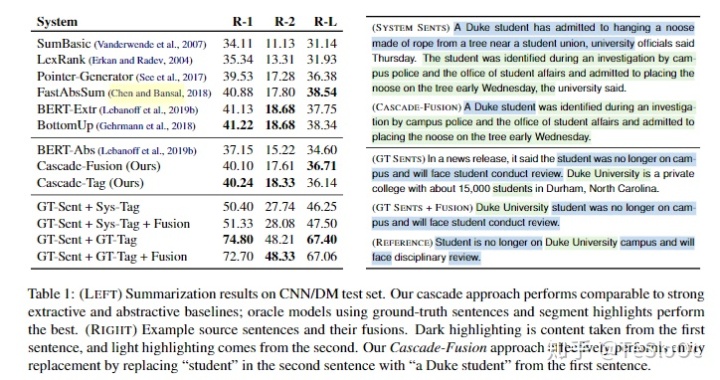
为了与主流的端到端模型,本文选择了流行的CNN/DM数据集来验证这种级联方法。然后,针对上述内容选择器的任务,对数据进行标注:每个样例有一到两个候选句,如果对该样例的候选句子进行压缩或合并,就能形成基础黄金摘要句,则为positive的样例,否则为negative的样例。
而针对positive样例,还高亮了所有在摘要中出现过的非标点的unigram单词。
Summarization Results
Conclusion
这篇文章提出了通过pipeline系统来构建神经生成式摘要系统,这在预训练模型以及端到端策略大行其道的2020年看起来确实有些逆势而为,并且从结果来看本文模型的一些结果也并没有全面超远所有基线,可以说甚至不如一些早期基线模型;但是这篇文章抛出的问题个人认为还是十分有价值的:
1、对摘要任务建模的局限性:目前主流的摘要模型大多只能在CNN/DM数据集上得到验证,然而并不是所有摘要任务对于摘要的要求都和CNN/DM数据集的要求相同或相似的,端到端的黑盒训练模式是否能够很好地将新闻摘要的模型迁移到其他领域的数据集上仍值得商榷,同时对于摘要乃至生成任务的评价也依然没有一个全面准确的方法,不论是BLEU还是ROUGE或是Meteor都或多或少在评价时顾此失彼。而更深层次的一些句子逻辑性以及事实性就更加难以通过目前这些指标进行评价。
2、端到端还是pipeline:是否所有任务都适合通过端到端策略进行训练,比如对于这篇文章的摘要任务,若深度抽象无法在现有的技术和条件下达成很好的效果那么是否可以退回浅度抽象,重新设计这个任务。如果一步到位的端到端策略无法很好解决这个问题,那么不如退回较没那么先进的pipeline策略,把摘要任务拆解成顺序的子任务,通过借助每个子任务中SOTA的方法或许也能比端到端的表现更加优秀。
总的来说这篇文章其实没有提出新的算法或者模型,只是在现有的一些成果下做了一定的验证实验,但是这篇文章留下的空白和可挖掘的空间其实还是非常大的,从这个pipeline结构出发,原本一步到位的摘要任务就被转变成了以highlight原文内容任务为主的pipeline生成任务。
因此,无论是在对内容选择策略上的改进还是神经生成器上的改进,亦或者时对于其中的多任务训练策略的设计上,都有许多可以进一步深挖优化的方向。















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









