





今天给大家分享一些机器学习小知识
目录
- 离散化
- 离散型变量的编码方式——one-hot与哑变量(dummy variable)
- 特征归一化的好处
- pandas 之切割 cut 与 qcut 功能与区别
- 交叉验证
离散化原因
数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间。分段的原则有基于等距离、等频率或优化的方法。数据离散化的原因主要有以下几点:
- 算法需要
比如决策树、朴素贝叶斯等算法,都是基于离散型的数据展开的。如果要使用该类算法,必须将离散型的数据进行。有效的离散化能减小算法的时间和空间开销,提高系统对样本的分类聚类能力和抗噪声能力。
- 离散化的特征相对于连续型特征更易理解,更接近知识层面的表达
比如工资收入,月薪2000和月薪20000,从连续型特征来看高低薪的差异还要通过数值层面才能理解,但将其转换为离散型数据(底薪、高薪),则可以更加直观的表达出了我们心中所想的高薪和底薪。
- 可以有效的克服数据中隐藏的缺陷,使模型结果更加稳定
离散化的优势
在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
离散型变量的编码方式——one-hot与哑变量(dummy variable)
我们在用模型去解决机器学习问题的时候,要提前进行“特征工程”。而特征工程中很重要的就是对特征的预处理。当你使用的是logistic回归这样的模型的时候,模型要求所有特征都应该是数值型变量,即连续的。但我们生活中常常遇到类别型变量(categorical variable),例如著名的Kaggle泰坦尼克生还预测这个比赛中,乘客从哪里上船(Embarked)这个变量就是类别型变量。这三个登船点两两之间的相关度应该是一样的,即S市和C市,与S市与Q市的相关度应该一样,这样就意味着如果我给Embarked变量用Embarked=1来表示乘客在S市上船,Embarked=2表示乘客在Q市上船,Embarked=3表示乘客在C市上船,这样就会认为S与Q的“距离”比S和C之间的距离更近,所以这样编码是不合理的。
正因如此,我们引入了离散型变量的编码方式——one-hot与哑变量
one-hot encoding
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

dummy encoding
哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,是不是。(额,当然他现实生活也可能上幼儿园,但是我们统计的样本中他并不是,^-^)。所以,我们用哑变量编码可以将上述5类表示成:

one-hot编码和dummy编码:区别与联系
通过上面的例子,我们可以看出它们的“思想路线”是相同的,只是哑变量编码觉得one-hot编码太罗嗦了(一些很明显的事实还说的这么清楚),所以它就很那么很明显的东西省去了。这种简化不能说到底好不好,这要看使用的场景。下面我们以一个例子来说明:
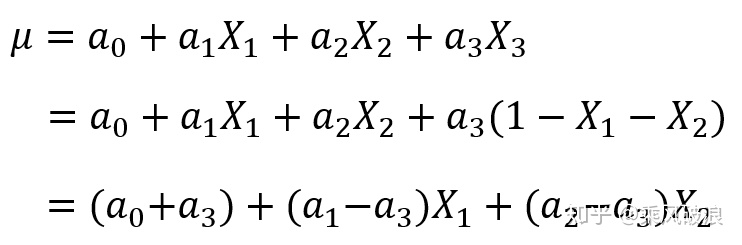
假设我们现在获得了一个模型,这里自变量满足(因为特征是one-hot获得的,所有只有一个状态位为1,其他都为了0,所以它们加和总是等于1),故我们可以用表示第三个特征,将其带入模型中,得到:
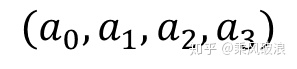
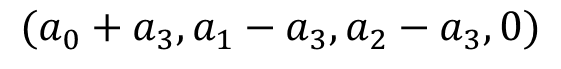
这时,我们就惊奇的发现和这两个参数是等价的!那么我们模型的唯一性就成了一个待解决的问题——难道我们用one-hot编码得到的特征是不唯一的?这肯定是不被允许的。这个问题这么解决呢?有三种方法:
(1)使用
(2)把偏置项
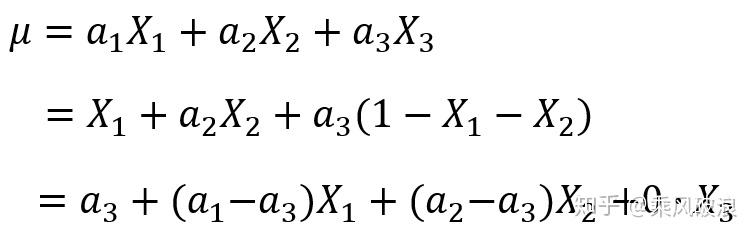
因为有了bias项,所以和我们去掉bias项的模型是完全不同的模型,不存在参数等价的问题。
(3)再加上bias项的前提下,使用哑变量编码代替one-hot编码,这时去除了,也就不存在之前一种特征可以用其他特征表示的问题了。
总结:我们使用one-hot编码时,通常我们的模型不加bias项 或者 加上bias项然后使用正则化手段去约束参数;当我们使用哑变量编码时,通常我们的模型都会加bias项,因为不加bias项会导致固有属性的丢失。
特征归一化的好处
归一化的作用
在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。其中,最典型的就是数据的归一化处理。(可以参考学习:数据标准化/归一化)
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
1)在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在0~1之间是统计的概率分布,归一化在-1~+1之间是统计的坐标分布。
2)奇异样本数据是指相对于其他输入样本特别大或特别小的样本矢量(即特征向量),譬如,下面为具有两个特征的样本数据x1、x2、x3、x4、x5、x6(特征向量—>列向量),其中x6这个样本的两个特征相对其他样本而言相差比较大,因此,x6认为是奇异样本数据。

奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
范例
如果不进行归一化,那么由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长。
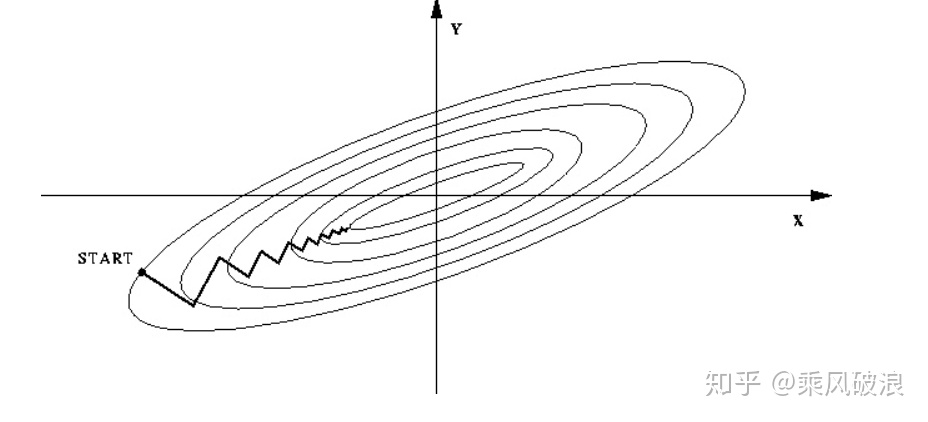
如果进行归一化以后,目标函数会呈现比较“圆”,这样训练速度大大加快,少走很多弯路。
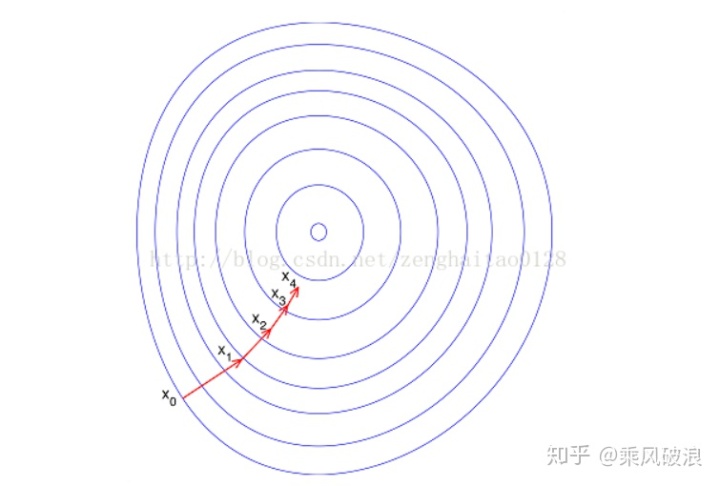
综上可知,归一化有如下好处,即
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度(如KNN)
pandas 之切割 cut 与 qcut 功能与区别
一、功能:
两者功能相似,都是将一个Series切割成若干个分组
api 可以看官网详细介绍,大致如下:
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise')
其中最常用的有个三个参数, x -代表数据集,这里一般是Series
q -为一个整数或数组,代表切割成几组或者具体的切割方式
labels -代表切割后的分组名称
返回值是一个 Categorical 类型,是一个可迭代对象,其中即包含了一个series,即 x中每个元素的分组标记。还包含了整体的分组情况。
二、区别
qcut 是等频切割,即基本保证每个组里的元素个数是相等的
cut是按值切割,即根据数据值的大小范围等分成n组,落入这个范围的分别进入到该组。
交叉验证
交叉验证是在机器学习建立模型和验证模型参数时常用的办法。交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
那么什么时候才需要交叉验证呢?交叉验证用在数据不是很充足的时候。比如在我日常项目里面,对于普通适中问题,如果数据样本量小于一万条,我们就会采用交叉验证来训练优化选择模型。如果样本大于一万条的话,我们一般随机的把数据分成三份,一份为训练集(Training Set),一份为验证集(Validation Set),最后一份为测试集(Test Set)。用训练集来训练模型,用验证集来评估模型预测的好坏和选择模型及其对应的参数。把最终得到的模型再用于测试集,最终决定使用哪个模型以及对应参数。
回到交叉验证,根据切分的方法不同,交叉验证分为下面三种:
第一种是简单交叉验证,所谓的简单,是和其他交叉验证方法相对而言的。首先,我们随机的将样本数据分为两部分(比如: 70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
第二种是S折交叉验证(S-Folder Cross Validation)。和第一种方法不同,S折交叉验证会把样本数据随机的分成S份,每次随机的选择S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择S-1份来训练数据。若干轮(小于S)之后,选择损失函数评估最优的模型和参数。
第三种是留一交叉验证(Leave-one-out Cross Validation),它是第二种情况的特例,此时S等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题,N小于50时,我一般采用留一交叉验证。
通过反复的交叉验证,用损失函数来度量得到的模型的好坏,最终我们可以得到一个较好的模型。那这三种情况,到底我们应该选择哪一种方法呢?一句话总结,如果我们只是对数据做一个初步的模型建立,不是要做深入分析的话,简单交叉验证就可以了。否则就用S折交叉验证。在样本量少的时候,使用S折交叉验证的特例留一交叉验证。
此外还有一种比较特殊的交叉验证方式,也是用于样本量少的时候。叫做自助法(bootstrapping)。比如我们有m个样本(m较小),每次在这m个样本中随机采集一个样本,放入训练集,采样完后把样本放回。这样重复采集m次,我们得到m个样本组成的训练集。当然,这m个样本中很有可能有重复的样本数据。同时,用原始的m个样本做测试集。这样接着进行交叉验证。由于我们的训练集有重复数据,这会改变数据的分布,因而训练结果会有估计偏差,因此,此种方法不是很常用,除非数据量真的很少,比如小于20个。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









