







批次是物料管理中的常见概念,特别是在化工、制药、快消等行业,由于生产工艺或材料的原因,不同批次的产品或原料,在具体的属性上有区别,或出于保质期、质量追溯等原因,需要对同一物料,不同批次的产品或原料进行区别,那么,启用批次管理可以很好的达到此目的。 通常,批次管理依赖于分类保存批次属性,详细的配置过程如下:
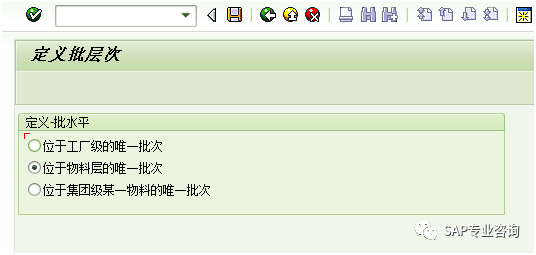
1、激活批次管理并指定批次的级别 在此处激活系统的批次管理功能;批次级别是指批次号的生产范围,由小到大可以选择是工厂级别、物料级别或集团级别,意义就是批次号在哪个级别是唯一的,比如选择了物料级别,那么当接受到物料时生产一个批次号,但当这个物料被转移到别一个工厂时仍保持这个批次不变;

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4921
4921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









