





本文中所涉及的代码,在未特殊声明的情况下,都是基于Python3程序设计语言编写的。
建议您在PC浏览器中阅读本文,以获得更好的阅读体验。
如果您未掌握知识提要中的内容,建议您先掌握这些内容之后再阅读本文。
知识提要
1、二叉树
2、递归、栈
3、线索二叉树
4、莫里斯遍历
0
问题描述
实现一个函数,给定一棵二叉树,返回二叉树的中序遍历序列。
如果你不了解二叉树,请先前往如下网站了解:
二叉树_百度百科baike.baidu.com
如果你不了解二叉树的遍历,请先前往如下网站了解:
二叉树遍历_百度百科baike.baidu.com
本题目来源自力扣算法题库的“第94题:二叉树的中序遍历”。为了方便各位读者验证自己的代码,本文中的代码将采用力扣OJ的格式规范,你可以将本文中的代码直接拷贝并粘贴到力扣的OJ提交框中进行提交和验证,不过我更建议你在理解的基础上,尝试自己去实现。力扣官网的官方解法中,对本文中第一种、第二种和第四种思路进行了详细的介绍,各位也可以先去了解一下。这些都是常用解法,所以本人的思路与官网的基本一致,只是增加了个人的理解和解读。官方解法并没有涉及到本文中第三种解法,它比较直观,但不是一个很好的解法,我会在题解中具体说明。
本文涉及到二叉树的结点,其数据结构定义如下:
class 二叉树中序遍历的函数原型如下:
def inorderTraversal(root):
# to be implemented
# root 的类型为TreeNode
pass1
递归遍历
递归实现是最简单,最好理解的实现方式,我将假设你能理解递归实现的原理。我们先从递归实现开始,然后根据递归实现的原理,推导出下一个实现方式的思路。
class Solution:
@staticmethod
def recursiveVisit(root, result):
if not root:
return
Solution.recursiveVisit(root.left, result) # 行7
result.append(root.val) # 行8
Solution.recursiveVisit(root.right, result) # 行9
def inorderTraversal(self, root):
result = []
Solution.recursiveVisit(root, result)
return result2
基于栈的遍历
注意观察递归实现的和7、8、9行代码。
- 第7行代码递归遍历tree的左子树,其效果是不停的将子孙后代的左子树压栈,直到某个后代结点没有左子树;然后开始出栈。
- 第8行代码是将栈顶元素的值入到结果列表中;由于我们已经遍历了栈顶元素的所有子结,由于是中序遍历,所以此时可以将栈顶元素的值放到结果中去。
- 第7行是对栈顶的右子树重复第7和第8行的操作。
模仿上面的思路,我们可以维护自己的栈,从而避免了使用递归函数。
class Solution:
def inorderTraversal(self, root):
result = []
stack = []
cur = root
while cur or stack:
while cur:
stack.append(cur)
cur = cur.left
cur = stack.pop()
result.append(cur.val)
cur = cur.right
return result3
基于栈的根结点标记法
通过如下的步骤,也可以达到遍历二叉树的效果:
0、将根结点放入栈中
1、如果栈不为空,跳到第3步;否则二叉树遍历结束。
2、被弹出的栈顶结点代码一个子树的根结点,根据栈先进后出的特性,由于右子树最后遍历,我们先将右子树放入栈中,然后将“根结点”放入栈中,最后将最先遍历的左子树放入栈中。跳到第1步。
3、将栈顶弹出,如果它是空结点,回到第1步;如果它一个“根结点”,则将值放到结果中去;否则它代表一棵树(某棵子树)。跳到第2步。
在第2步中,我们注意到,左右结点是代表左右子树的形式入栈,而“根结点”是代表值的形式入栈,所以当“根结点”出栈时,就说明左子树已经遍历完毕,我们就需要将“根结点”的值放到结果中去。但由“根结点”,左右子树,都是以TreeNode的形式存在。也就是说一个TreeNode可以表示一个结点,也可以表示一个子树。所以在入栈时,我们需要知道某个结点,是代表一个值入栈,还是代表一棵子树入栈。在入栈时,我们加入一个标识位就可以了。
class Solution:
def inorderTraversal(self, root):
result = []
if not root:
return result
stack = [(False, root)]
while stack:
is_root, node = stack.pop()
if not node: continue
if is_root:
result.append(node.val)
else:
stack.append((False, node.right)) # 行14
stack.append((True, node)) # 行15
stack.append((False, node.left)) # 行16
return result这个解法的好处就是,对先序、中序和后序遍历,总是可以写出类似的代码,例如只要交换15行和16行的代码,就变成了先序遍历了。
坏处就是,每个结点分别会代码子树和值被入栈两次;在第2个解法中,每个结点只会入栈一次。
4
Morris遍历(莫里斯遍历)
在理解这个解法之前,你可以需要事先掌握如下的知识点:
线索二叉树
线索二叉树_百度百科baike.baidu.com
莫里斯遍历
二叉树的莫里斯遍历www.jianshu.com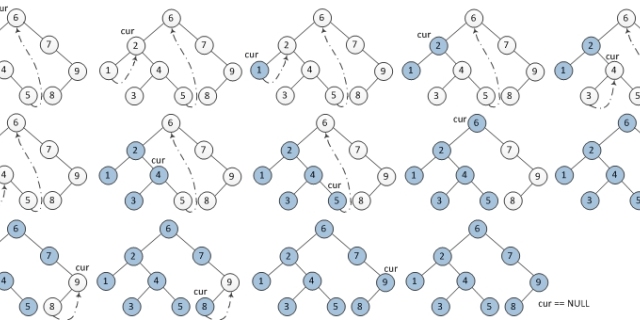
总结一下莫里斯遍历的特点,就是:
1、如果一个结点有左子树,则将这个结点放在它的左子树的最右后代结点上;
2、否则,如果结点没有左子树,则将这个结点输出,并对其右子树进行第1步的操作。
class Solution:
def inorderTraversal(self, root):
result = []
if not root:
return result
curr = root
while curr:
if curr.left:
right_most = curr.left
while right_most.right:
right_most = right_most.right
right_most.right = curr
tmp = curr
curr = curr.left
tmp.left = None
else:
result.append(curr.val)
curr = curr.right
return result















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









