





今天
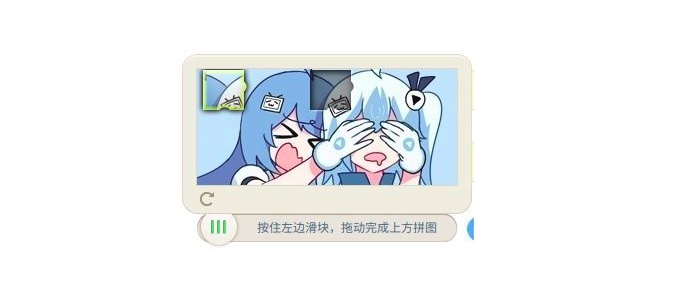
要来说说滑动验证码了
大家应该都很熟悉
点击滑块然后移动到图片缺口进行验证
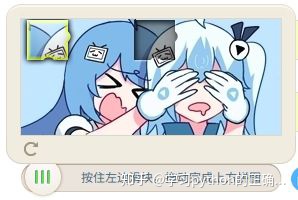
现在越来越多的网站使用这样的验证方式
为的是增加验证码识别的难度

那么
对于这种验证码
应该怎么破呢
接下来就是
学习 python 的正确姿势

打开 b 站的登录页面
https://passport.bilibili.com/login
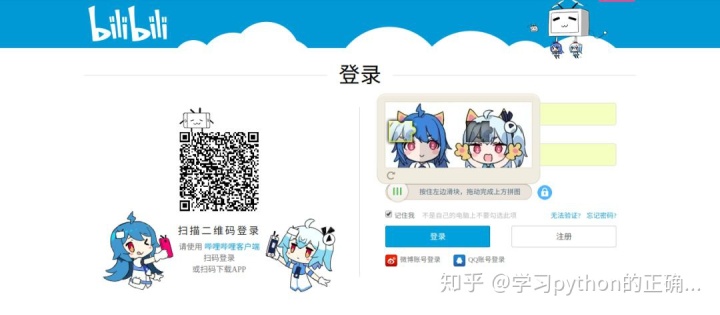
可以看到登录的时候需要进行滑块验证
按下 F12
进入 Network
看下我们将滑块移到缺口松开之后做了什么提交
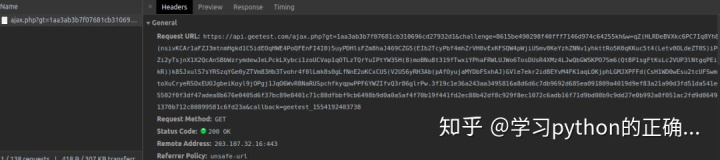
可以看到是一个 GET 请求
但是
这请求链接也太特么长了吧
就是比小帅b短了一点点

我们来看看请求的参数是怎么样的

哇靠
gt?
challenge?
w?
这些都是什么鬼参数
还加密了
完全下不了手啊

那么
本篇完
再见
peace
说
你是不是迷恋我??

好吧
你居然滑到这里来了
说明你还是有点爱小帅b的
小帅b是那种遇到一点困难就放弃的人吗
显然不是
那么接下来才是真的
学习 python 的正确姿势
既然以请求的方式不好弄
我们从它们的源代码入手
看看有什么突破口

回到 b 站的登录页
按下 F12
进入 Element
然后点击滑块出现了图片
定位一下
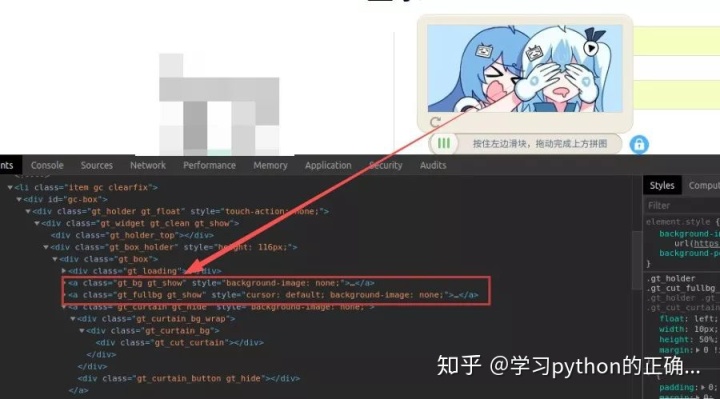
发现有两个 a 标签
一个 class 是 gt_bg gt_show
一个 class 是 gt_fullbg gt_show
和小帅b想的一样
这个验证码应该是有两张图片
一张是完全的背景图片
一张是缺口的图片
那把这两张图片下载下来对比一下不就行了
打开 a 标签一看
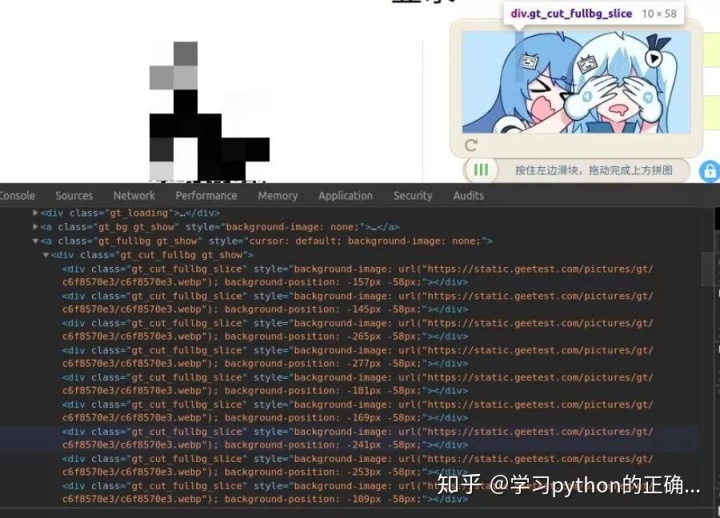
哇靠
一张图片被切割成很多小块
原来这张图片是拼出来的
我们看看原始图片是怎么样的

什么乱七八糟的
再仔细看下源代码
原来是在同一张图片通过偏移量合成了一张完整的图片
background-position: -277px -58px;厉害厉害
小帅b看了一下缺口的图片也是如此

到这里
我们的第一个思路就是
下载这两张原始图片
然后通过偏移量合成两张真正的图片
背景图

↓变身

缺口图

↓变身

那么怎么做呢?
因为我们还要模拟滑动滑块
所以呢
我们要用到 selenium
打开b站的登录页
然后等到那个滑块显示出来
# 获取滑块按钮
driver.get(url)
slider = WAIT.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, "#gc-box > div > div.gt_slider > div.gt_slider_knob.gt_show")))接下来我们就获取页面的源码
driver.page_source
然后使用 bs 获取两张原始背景图片的 url
bs = BeautifulSoup(driver.page_source,'lxml')
# 找到背景图片和缺口图片的div
bg_div = bs.find_all(class_='gt_cut_bg_slice')
fullbg_div = bs.find_all(class_='gt_cut_fullbg_slice')
# 获取缺口背景图片url
bg_url = re.findall('background-image:surl("(.*?)")',bg_div[0].get('style'))
# 获取背景图片url
fullbg_url = re.findall('background-image:surl("(.*?)")',fullbg_div[0].get('style'))拿到了图片地址之后
将图片下载下来
# 将图片格式存为 jpg 格式
bg_url = bg_url[0].replace('webp', 'jpg')
fullbg_url = fullbg_url[0].replace('webp', 'jpg')
# print(bg_url)
# print(fullbg_url)
# 下载图片
bg_image = requests.get(bg_url).content
fullbg_image = requests.get(fullbg_url).content
print('完成图片下载')ok

我们已经把两张原始图片下载下来了

那么接下来就是要合成图片了
我们要根据图片的位置来合成
也就是源码中的 background-position
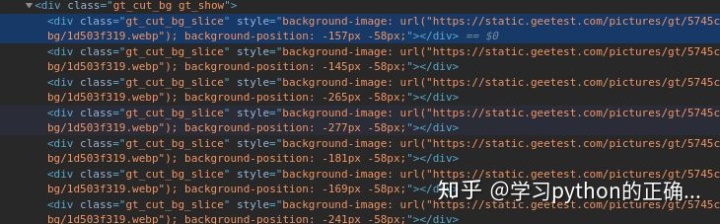
获取每一个小图片的位置
我们可以通过字典的形式来表示这些位置
然后将数据放到列表中
# 存放每个合成缺口背景图片的位置
bg_location_list = []
# 存放每个合成背景图片的位置
fullbg_location_list = []
for bg in bg_div:
location = {}
location['x'] = int(re.findall('background-position:s(.*?)pxs(.*?)px;', bg.get('style'))[0][0])
location['y'] = int(re.findall('background-position:s(.*?)pxs(.*?)px;', bg.get('style'))[0][1])
bg_location_list.append(location)
for fullbg in fullbg_div:
location = {}
location['x'] = int(re.findall('background-position:s(.*?)pxs(.*?)px;', fullbg.get('style'))[0][0])
location['y'] = int(re.findall('background-position:s(.*?)pxs(.*?)px;', fullbg.get('style'))[0][1])
fullbg_location_list.append(location)
那么
现在我们已经有了原始图片
还知道了每个位置应该显示原始图片的什么部分
接下来我们就写一个方法
用来合成图片
# 写入图片
bg_image_file = BytesIO(bg_image)
fullbg_image_file = BytesIO(fullbg_image)
# 合成图片
bg_Image = mergy_Image(bg_image_file, bg_location_list)
fullbg_Image = mergy_Image(fullbg_image_file, fullbg_location_list)那么问题又来了
怎么合成啊
我们再看看一开始分析的图片
这里图片被分割成的每一个小图片的尺寸是
10 * 58
所以我们也要将我们刚刚下载的原始图片切割成相应的尺寸大小
而且
这张图片是由上半部分的小图片和下半部分的小图片合成的
所以我们定义两个 list 来装这些小图片
# 存放上下部分的各个小块
upper_half_list = []
down_half_list = []然后将原始的图片切割好放进去
image = Image.open(image_file)
# 通过 y 的位置来判断是上半部分还是下半部分,然后切割
for location in location_list:
if location['y'] == -58:
# 间距为10,y:58-116
im = image.crop((abs(location['x']), 58, abs(location['x'])+10, 116))
upper_half_list.append(im)
if location['y'] == 0:
# 间距为10,y:0-58
im = image.crop((abs(location['x']), 0, abs(location['x']) + 10, 58))
down_half_list.append(im)
至此
我们这两个 list 就分别放好了各个切割的图片了
那么接下来就创建一张空白的图片
然后将小图片一张一张(间距为10)的粘贴到空白图片里
这样我们就可以得到一张合成好的图片了
哎
我真是个天才

# 创建一张大小一样的图片
new_image = Image.new('RGB', (260, 116))
# 粘贴好上半部分 y坐标是从上到下(0-116)
offset = 0
for im in upper_half_list:
new_image.paste(im, (offset, 0))
offset += 10
# 粘贴好下半部分
offset = 0
for im in down_half_list:
new_image.paste(im, (offset, 58))
offset += 10那么到现在
我们可以得到网页上显示的那两张图片了
一张完全的图片
一张带缺口的图片
接下来我们就要通过对比这两张图
看看我们要滑动的距离是多远
# 合成图片
bg_Image = mergy_Image(bg_image_file, bg_location_list)
fullbg_Image = mergy_Image(fullbg_image_file, fullbg_location_list)
# bg_Image.show()
# fullbg_Image.show()
# 计算缺口偏移距离
distance = get_distance(bg_Image, fullbg_Image)
print('得到距离:%s' % str(distance))可以通过图片的 RGB 来计算
我们设定一个阈值
如果 r、g、b 大于这个阈值
我们就返回距离
def get_distance(bg_Image, fullbg_Image):
#阈值
threshold = 200
print(bg_Image.size[0])
print(bg_Image.size[1])
for i in range(60, bg_Image.size[0]):
for j in range(bg_Image.size[1]):
bg_pix = bg_Image.getpixel((i, j))
fullbg_pix = fullbg_Image.getpixel((i, j))
r = abs(bg_pix[0] - fullbg_pix[0])
g = abs(bg_pix[1] - fullbg_pix[1])
b = abs(bg_pix[2] - fullbg_pix[2])
if r + g + b > threshold:
return i现在
我们知道了关键的滑动距离了
激动人心的时刻到了
我们使用 selenium
拿到滑块的元素
然后根据这个距离拖动到缺口位置不就好了么
马上打开 selenium 的文档
看到了这个函数

它可以使用左键点击元素
然后拖动到指定距离
最后释放鼠标左键
挖槽
正合我意
赶紧试一下
knob = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#gc-box > div > div.gt_slider > div.gt_slider_knob.gt_show")))
ActionChains(driver).drag_and_drop_by_offset(knob, distance, 0).perform()运行一下试试看吧
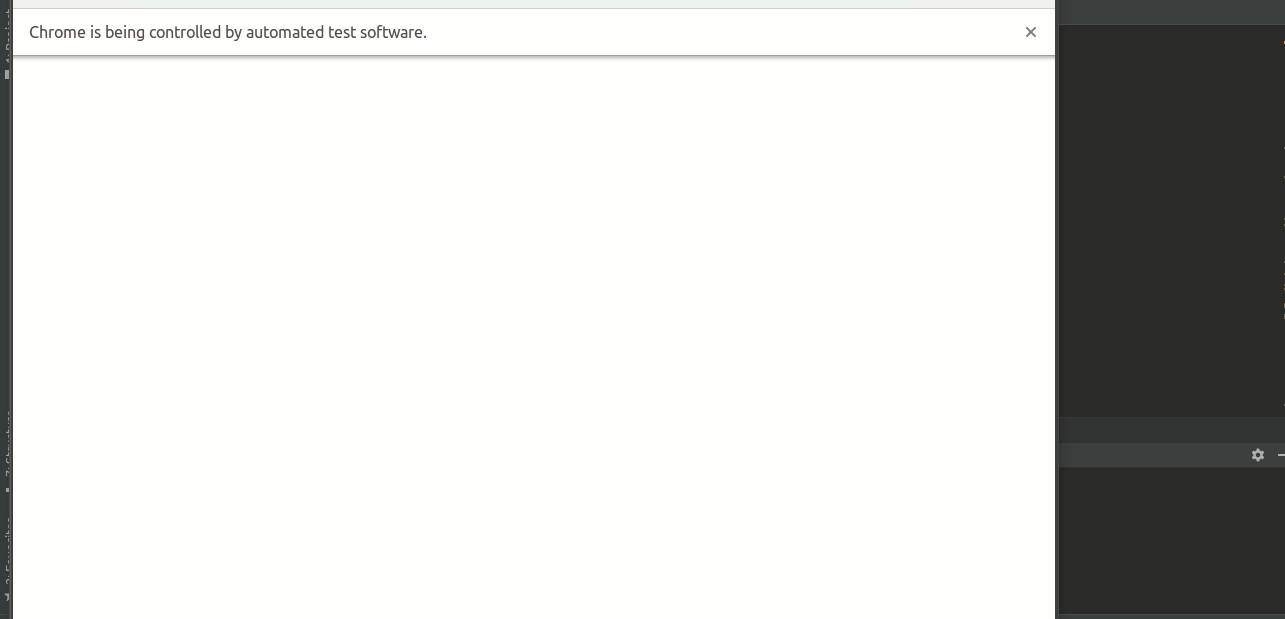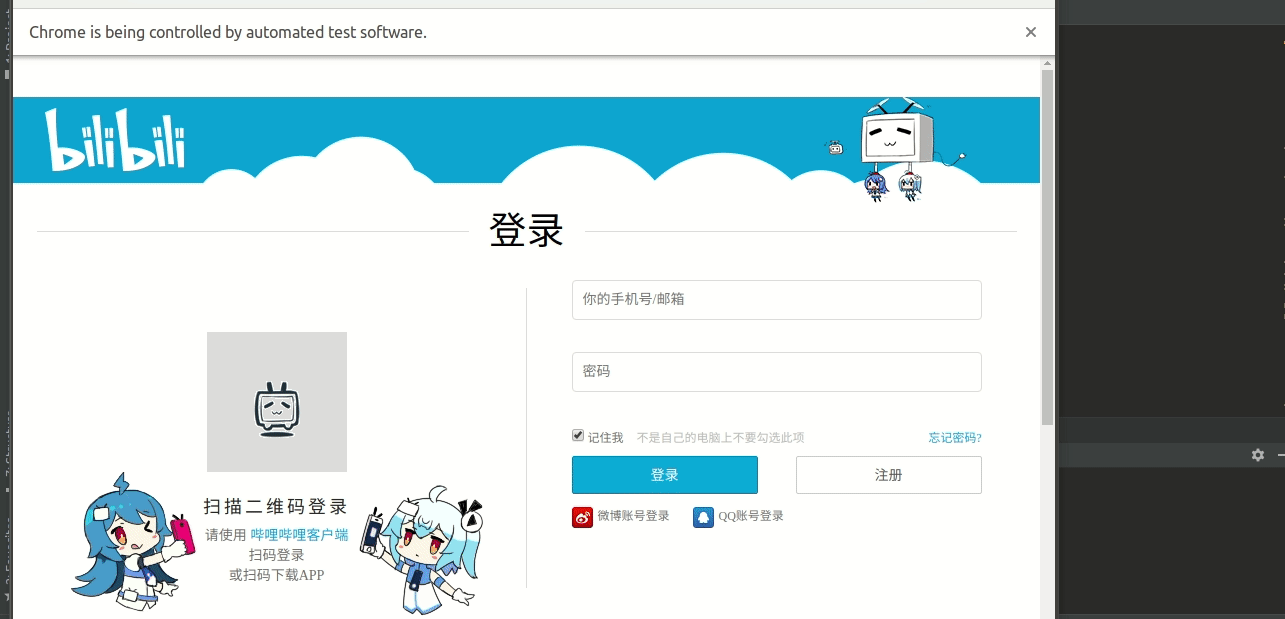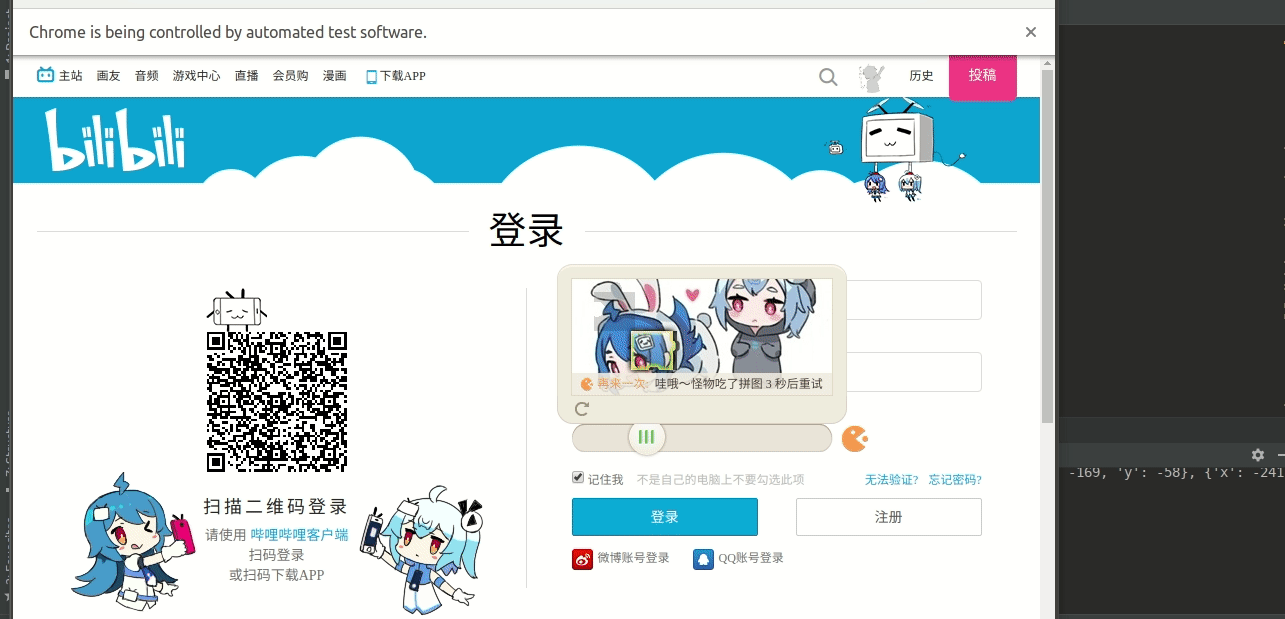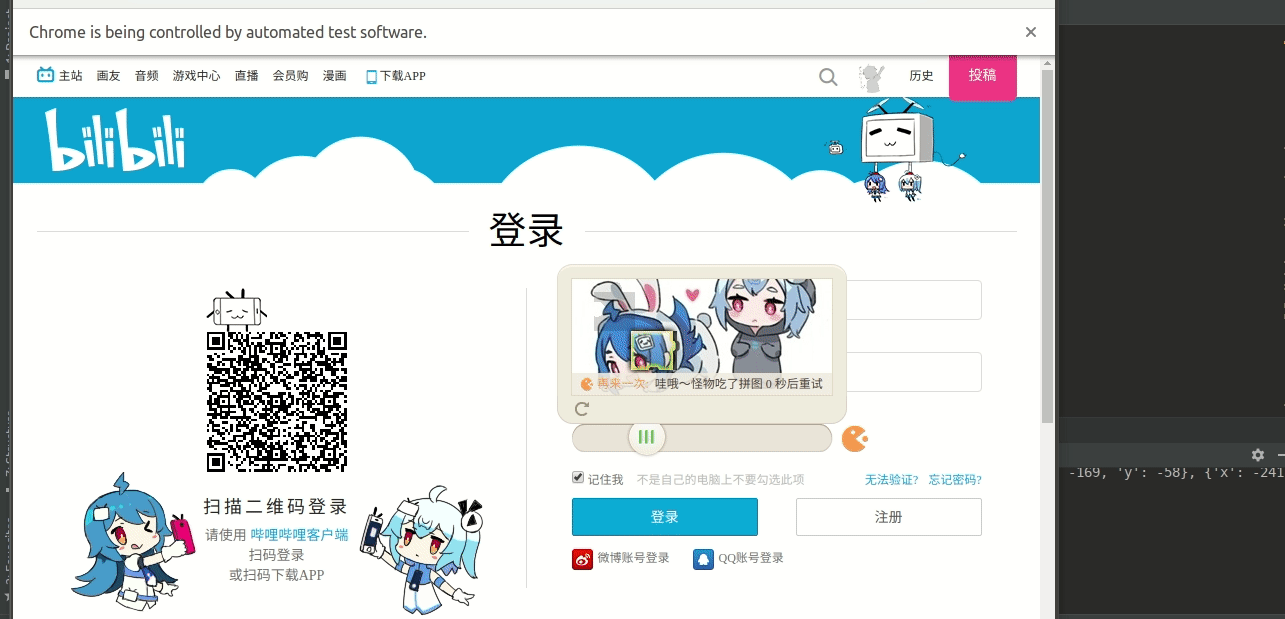
哇哦你妹哦~
妖怪吃了拼图了

看来直接拖拽是不行的
容易遇到妖怪
毕竟这太快了
就算加藤鹰也没那么快吧
小帅b试着拖完滑块让它睡一下再释放
ActionChains(driver).click_and_hold(knob).perform()
ActionChains(driver).move_by_offset(xoffset=distance, yoffset=0.1).perform()
time.sleep(0.5)
ActionChains(driver).release(knob).perform()发现拼图还是特么的被妖怪吃了

后来小帅b发现原来别人也遇到了这样的问题
然后又发现了
有个叫匀速直线运动的东西
什么 加速度
什么 v = v0 + at
什么 s = ½at²
哇
这不是高中的知识点么
瞬间想起小帅b高中的时候在最角落的课桌
此刻往右上方抬起头
45 度角
让我的眼泪划出一条美丽的弧线

什么鬼
回到正题
我们可以使用它来构造一个运动路径
该加速时加速
该减速的时候减速
这样的话就更像人类在滑动滑块了
def get_path(distance):
result = []
current = 0
mid = distance * 4 / 5
t = 0.2
v = 0
while current < (distance - 10):
if current < mid:
a = 2
else:
a = -3
v0 = v
v = v0 + a * t
s = v0 * t + 0.5 * a * t * t
current += s
result.append(round(s))
return result
这次
我们使用这个轨迹来滑动
knob = WAIT.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#gc-box > div > div.gt_slider > div.gt_slider_knob.gt_show")))
result = get_path(distance)
ActionChains(driver).click_and_hold(knob).perform()
for x in result:
ActionChains(driver).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(driver).release(knob).perform()
好了好了
我们再来运行一下吧
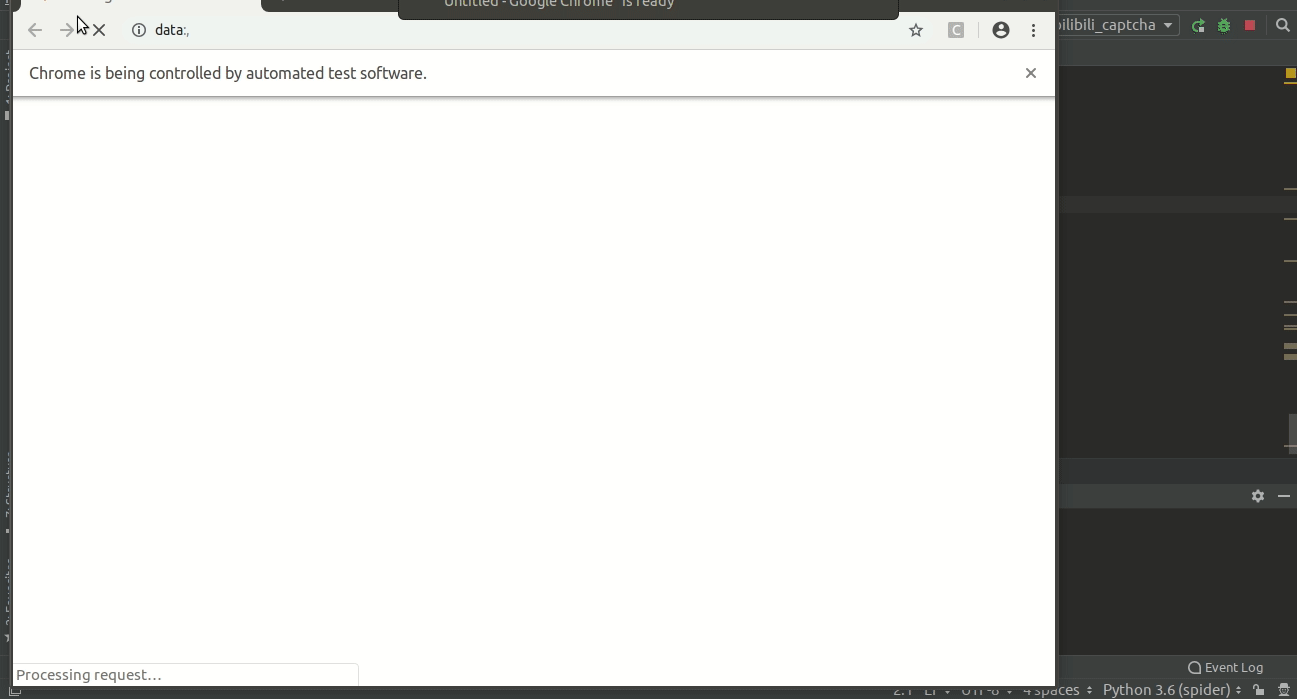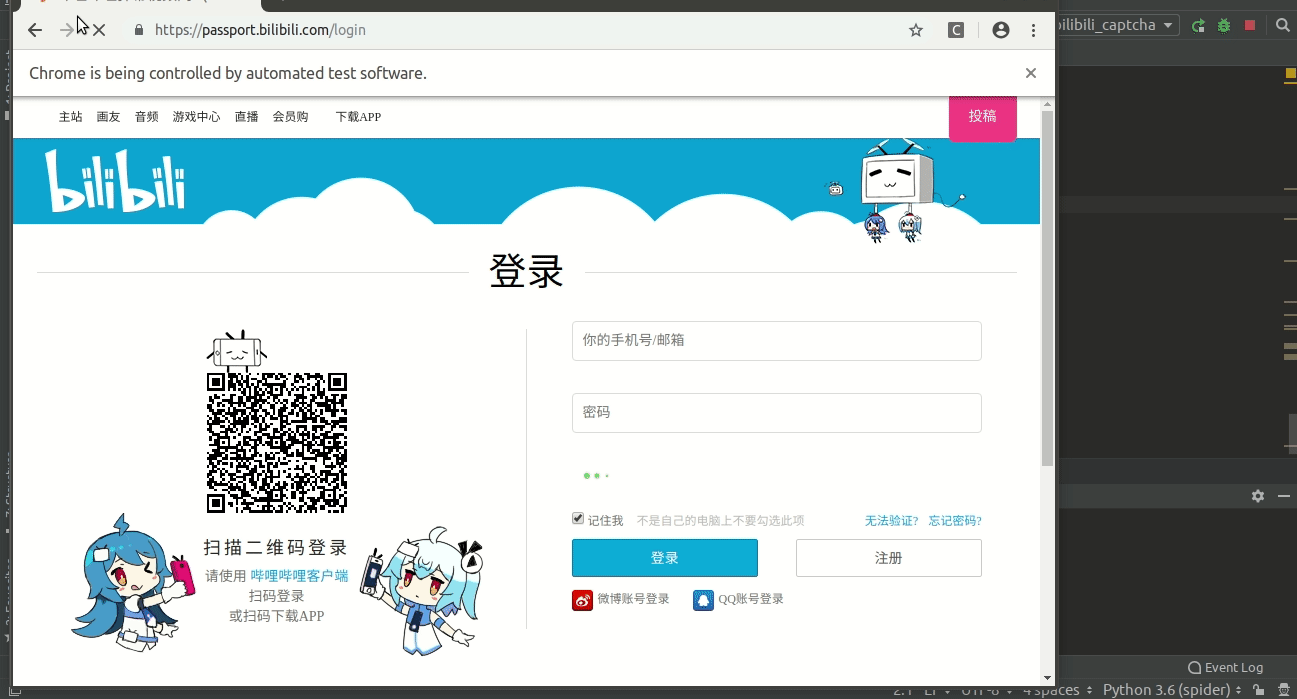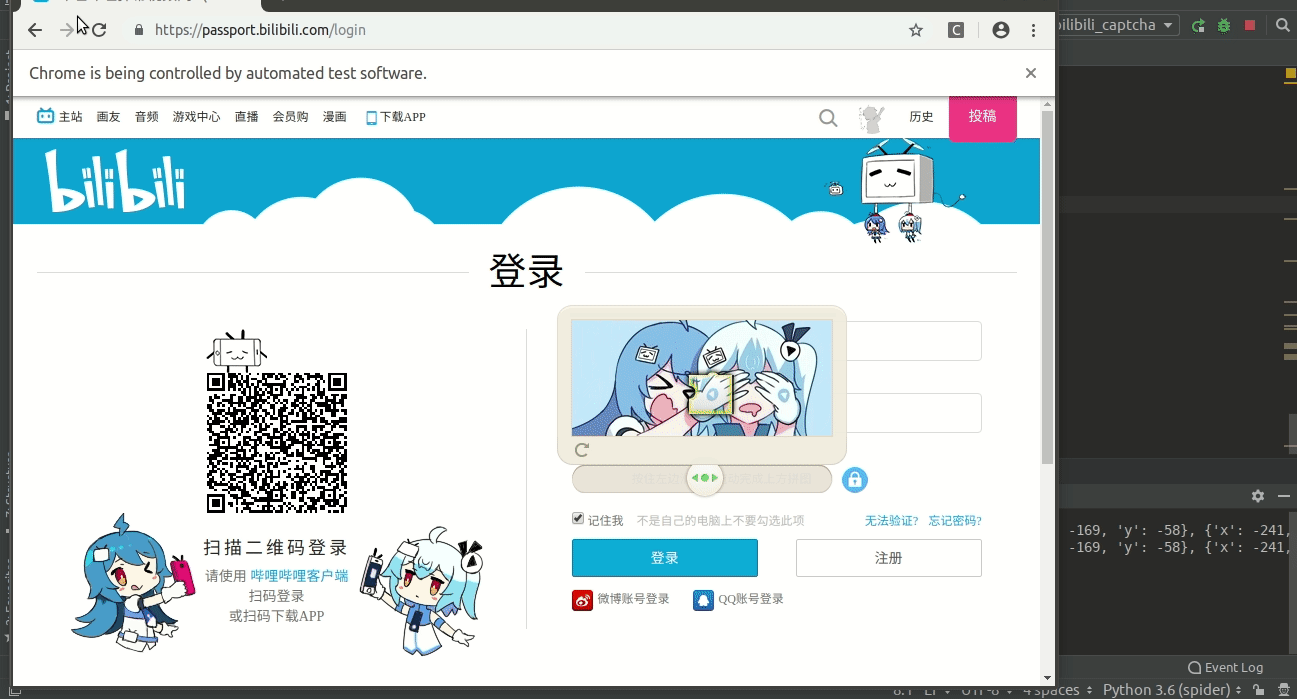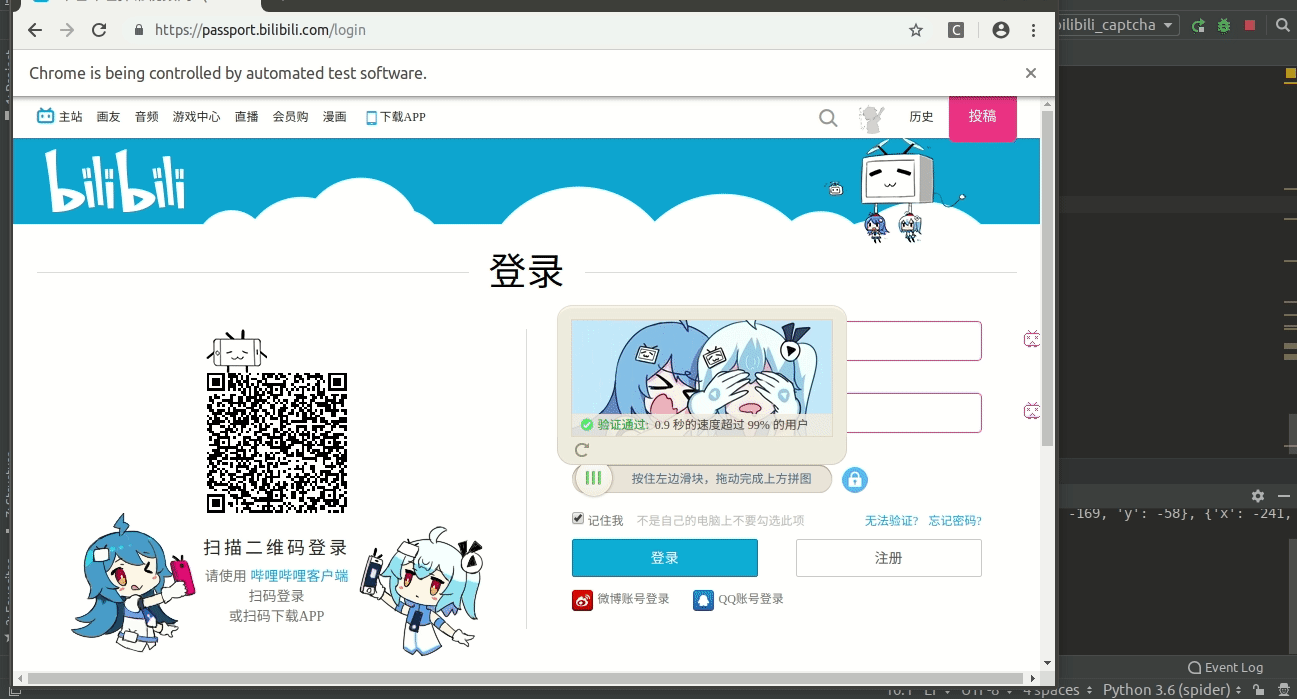
哈哈哈
cool
成功识别了哇
我不管

当然了
成功率不是 100%
可以多调戏它几次
ok
以上就是识别滑动验证码的具体过程了
对于其它大部分的滑动验证码
也是可以使用这招搞定的
由于篇幅有限
源代码我放在了这个公众号【学习python的正确姿势】后台了
你发送〔滑动〕两个字
就可以获取啦
那
这次本篇就真的完啦
听说你想约我?
peace
肯定会

相关文章
(小帅b教你三招搞定模拟登录)
(小帅b教你轻松识别图片验证码)
点个在zan啊~~(破音)
















 5258
5258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









