






Python支持大部分在其他语言中出现的编程结构。在本章内容中,我们将会涉及到许多Python支持的编程结构。我们将会首先介绍如何创建一个新的Python脚本以及如何修改已有脚本。之后我们将深入了解Python的语言特性,比如添加注释,创建变量,变量赋值以及Python的自动代码补齐功能等,了解这些内容将让你在使用Python编程的时候更为简便。接下来我们会介绍Python内置的数据类型,包括字符型,数值型,列表和字典等。类和对象是面向对象编程和Python语言中两个基本的概念。你在ArcGIS中编写地理处理脚本时会经常使用到上述这些复杂的数据结构。另外,我们还将介绍条件语句和循环语句以及with语句,这些语句在涉及到ArcPy数据访问模块(Data Acccess module)中新的游标(cursor)对象时会经常使用。最后你还会了解到如何访问模块,这些模块可以为Python提供更多附加功能。 该部分包含以下内容:
- 如何创建并编辑Python脚本
- Python语言特性
- 注释和变量
- Python内置数据类型(字符,数字,列表和字典)
- 复杂的数据结构
- 循环语句
- Python其他功能
IDLE
我在前言中提到过,ArcGIS桌面软件安装后,Python以及用于编写代码的IDLE工具也会一同安装。IDLE是集成开发环境的缩写(Integrated DeveLopment Environment)。由于IDLE在每一个ArcGIS桌面软件安装环境中都可以使用,我们使用IDLE开发环境来编写本书中的大部分代码,才外还会使用ArcGIS软件中内置的Python窗口。你作为程序员还可能会更钟意其他的开发工具,你也可以使用这些工具来编写代码。
Python shell窗口
点击开始 | 所有程序 | ArcGIS | Python2.7 | IDLE打开Python的IDLE开发环境。注意Python版本会因为安装的ArcGIS软件版本不同而不同。比如,ArcGIS10.0版本安装的是Python2.6,而ArcGIS 10.1版本安装的则是Python2.7。Python的shell窗口类似于下面的截图:
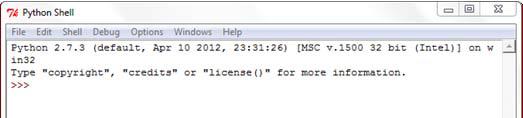
Python的shell窗口用于显示脚本生成的结果消息和错误消息。对于初学者来讲,通常会误认为地处理脚本代码是在shell窗口中编写。事实上并非如此。你需要打开另一个单独的代码窗口来保存你的脚本。尽管shell窗口不能用来编写完整脚本代码,但可以以交互方式来即时获取代码反馈信息。ArcGIS软件中包含一个内置Python shell窗口也是使用相同的方式。我们将在下个章节来介绍ArcGIS Python 窗口。
Python 脚本窗口
在IDLE中,脚本代码编写是在一个称作Python 脚本窗口(Python script window)的独立窗体中完成。点击IDLE shell窗口中的File | New Window来打开一个新的代码窗口。Python脚本窗口如下图所示:
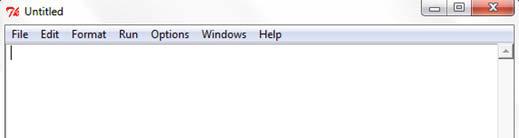
在这个新打开的脚本窗口中你就可以编写代码了。每个脚本需要保存到本地磁盘或者网络驱动器中。脚本文件默认的文件扩展名为.py。
编辑已有Python脚本
右键单击已有的Python脚本文件选择Edit with IDLE,会弹出一个新的shell窗口以及载入脚本代码内容的Python脚本编辑器。如下面的截图:
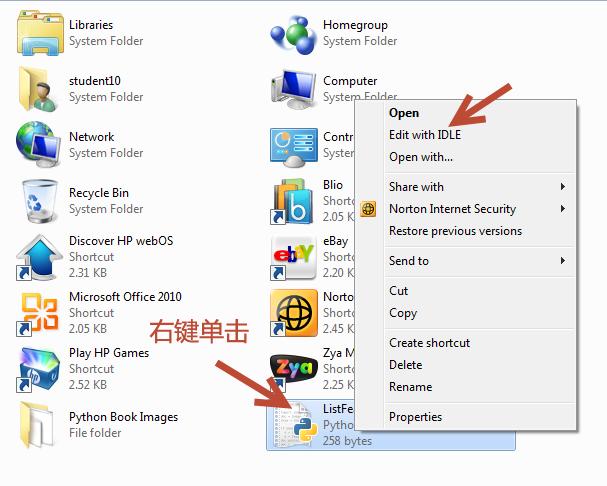
在这个示例中,我们已经在IDLE中载入了ListFeatureClasses.py 脚本文件。代码内容出现在脚本窗口中:
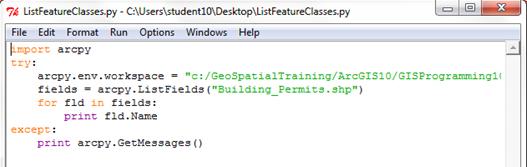
现在脚本窗口已经打开,你就可以开始编写或修改代码了。你还可以在IDLE中执行一些简单的代码调试工作。代码调试是指发现并修改代码中错误的过程。
IDLE中运行脚本
在IDLE代码窗口中编写完地理处理脚本或者打开了一个脚本文件之后,你就可以在IDLE中执行代码。运行脚本之前,你可以先在IDLE中进行代码的语法检查。在代码窗口中,点击Run | Check Module来执行语法检查。所有的语法错误都会显示在shell窗口中。如果没有发现任何语法错误的话,你将只会看到弹出的shell窗口。虽然IDLE可以用来检查语法错误,但是并没有提供逻辑错误检查工具以及像PythonWin或者Wingware的开发环境提供的高级调试功能。确认代码中没有语法错误后,你就可以运行脚本啦。点击Run | Run Module在运行脚本:
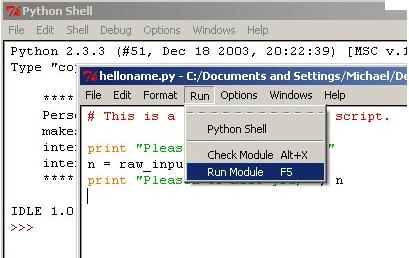
所有的错误消息以及print 语句和系统消息结果都会显示在shell窗口中。print 语句可以将字符串输出到shell窗口中。该语句通常用于更新一个正在运行脚本的状态或者代码调试。
Python语言基础
为了能够更好地编写ArcGIS地理处理脚本,你需要先了解一些基本的Python语言结构。尽管相对其他大部分编程语言,Python更容易学习,但是仍需要花费一定时间来学习并熟练使用。该部分内容将向你介绍如何创建变量,如何给变量赋不同数据类型的值,如何理解赋值给变量的不同数据类型,如何使用不同类型的语句,如何使用对象,如何读写文件以及如何导入第三方的Python模块。
注释
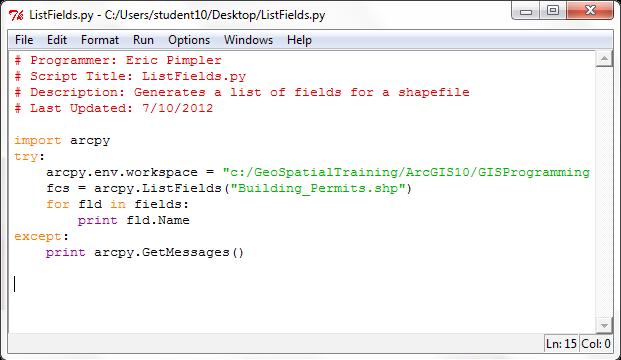
Python脚本需要遵循一个通用的结构。每个脚本的开头部分应作为说明文档,用以详细描述脚本名称,作者以及脚本功能的总体描述。说明文档部分在Python中可以通过注释功能来完成。注释指用来添加到脚本中作为脚本功能说明性文档的代码语句。这些代码以#或者##开始,后面跟着你需要说明解释的文本内容。Python解释器不会处理这类代码。它们只是解释说明代码意义。如下图所示,注释行代码用红色字体显示。你也应该尝试在脚本中添加注释来描述脚本中的重要部分。无论对你或对其他程序员这对今后修改代码都是非常有用的。
导入模块
尽管Python包含了大量的内置功能,你还是会经常需要访问一些专门的功能包, 功能包又包含在一些外部模块中。举个例子,Math模块包含了与数值处理有关的功能,R模块则提供了数据统计分析的功能。使用import 语句导入模块。编写ArcGIS地处理脚本时,通常就需要导入ArcPy模块,该模块是用于访问ArcGIS中提供的GIS工具和函数的Python包。import 语句会是脚本中的第一行代码(不包括注释部分): import arcpy,os
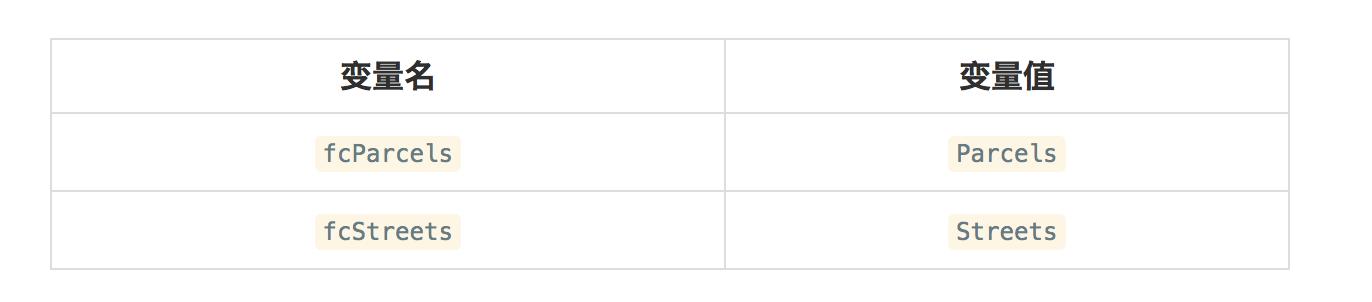
变量 从高层面来说,变量可以看做是脚本运行过程中用来存储值的计算机内存区域。在Python中,通过给定名称和值来定义变量。变量赋值之后只要简单地引用变量名称,就可以在脚本中的不同位置来获取该变量值。比如,你创建了一个包含要素类名称的变量,该变量之后被Buffer工具调用生成了一个新的要素集。只要简单地给定一个名称,然后紧跟着赋值运算符(=)和要赋的值就可以创建一个变量:
fcParcels = "Parcels"fcStreets = “Streets”下表说明了变量名和通过上面的示例代码赋值给变量名的变量值的关系:
你在创建变量时候必须遵守一些命名规则,主要包含以下内容:
- 使用字母,数字和下划线
- 首字母必须为字母
- 除了下划线不能包含其他特殊字符
- 不能使用Python关键字
大概有几十个Python关键字是必须要避免使用的,包括class,if,for,while 等等。下面是一些合法的变量名称的例子:
- featureClassParcel
- fieldPopulation
- field2
- ssn
- my_name 下面是一些非法的变量名称的例子:
- class (使用了Python关键字)
- return (使用了Python关键字)
- $featureClass (包含特殊字符,必须以字母开头)
- 2fields (必须以字母开头)
- parcels&Streets (包含特殊字符)
Python语言是区分大小写的,因此需要特别注意脚本中变量命名和大小写。对于Python新人来说,大小写问题很可能是最为常见的错误原因,因此遇到代码错误时需要考虑到这种情况。我们看一个例子。下面的三个变量的变量名称除了大小写不同之外是一样的,但Python仍然认为是三个不同的变量。
mapsize = “22x34"MapSize = “8x11"
Mapsize = “36x48”
如果打印这三个变量:
print capsizeprint MapSize
print Mapsize
运行结果如下:
22x348x11
36x48
Python中变量名称需要在整个脚本中保持一致。推荐是采用驼峰式命名,即变量名称的首个单词全部采用小写,后续的每个单词的首字母大写。下面以fieldOwnerName 的变量名举例说明。首个单词(field )全部是小写,后面跟的第二个单词(`Owner )和第三个单词(Name )都是采用首字母大写的形式。Python中变量类型是动态的。动态类型(Dynamic typing)意味着你可以只定义变量名称和并赋值给它,而不需要定义变量的数据类型。常用的数据类型包括:

我们将在后面的内容中详细介绍数据类型。C#中你需要先定义变量的名称和类型才能使用。在Python中只要给定变量名称和值之后就可以使用。Python会在后台确定变量所包含的数据类型。举个例子,在下面的代码示例中,我们创建了一个aTouchdown 的变量,该变量被定义为整型,也就意味着变量只能接受整型数据。我们给这个变量赋值为6:
int aTouchdown;aTouchdown = 6;
在Python中同一变量可以动态赋值。Python解释器会动态地处理赋给变量的数据类型:
aTouchdown = 6你编写的ArcGIS Python地理处理脚本中需要经常引用本地计算机或者共享服务器上的数据集的位置。变量中的数据集地址通常由路径组成。Python中路径名称是一类特殊情况需要特别说明。反斜线()是Python中保留的转义字符和行连接符,因此在定义路径变量时需要使用两个反斜线()或者一个斜线(/)或是在使用单个反斜线时需增加字母r前缀。下面举例说明这一问题。不正确的路径引用:
fcParcels = "c:DataParcels.shp"正确的路径引用:
fcParcels = "c:/Data/Parcels.shp"fcParcels = “c:DataParcels.shp"fcParcels = r”
c:DataParcels.shp"
有时候你知道脚本中需要一个变量,但是又没有必要事先了解要赋给变量的是什么数据。在这种情况下,你就可以先简单地定义一个变量而不赋值给它。脚本运行中赋给变量的值也可以更改。变量可以保存许多不同的数据类型,既包括像字符型和数值型这样的基本数据类型(primitive datatype),也可以包括像列表,字典甚至对象这样复杂的数据类型。接下来我们将介绍可以赋值给变量的不同的数据类型以及Python提供的数据操作方法。
内置数据类型
Python包含许多内置的数据类型。我们首先介绍的是字符型(string )。我们已经见过一些字符型变量的例子,不过这些变量还可以执行许多操作方法,让我们进一步了解这一数据类型。 字符串 字符串是用于存储和表示文本信息的有序字符集合。简单地讲就是字符串变量保存文本内容。字符串括在单引号或双引号内赋值给变量。字符串可以是名称,要素类名称,where 条件语句以及其他可以用文本表示的情况。 字符操作 Python中提供了很多字符串的操作方法。字符串连接就是最为常用的功能之一,并且容易实现。使用+运算符就可以将运算符两边的字符串合并为一个新的字符串变量:
shpStreets = "c:GISDataStreets" + ".shp”print shpStreets
运行结果如下:
c:GISDataStreets.shp你可以使用Python提供的==(两个连续的=)运算符来测试字符串是否相等。不要混淆了相等运算符和赋值运算符,后者使用单个等号符号。相等运算符是用于判断两个变量是否相等,而赋值运算符则是赋值给变量:
firstName = “Eric"lastName = “Pimpler”
firstName == lastName
False你还可以使用in运算符来判断字符串的包含关系,如果第一个算子包含在第二个算子中的话将返回True。
fcName = "Floodplain.shp"print ".shp”in fcNameprint ".shx"
in fcName
运行结果如下:
TrueFalse
我之前简单提到过字符串是有序的字符集合。这意味着什么?这将意味着我们可以获取字符串中的单个字符或者子字符串。在Python中,获取单个字符的操作称作索引(indexing),而获取连续字符的时候操作切片(slicing)。字符串中的字符可以通过括在方括号内的数字索引值来获取。比如你可以使用fc[0] 来获得获取fc 变量中字符串的第一个字符。负的位置数值用于从字符串末端开始反向向前查找。在这种情况下,字符串最后一个字符的索引号为-1。使用索引会创建一个新的变量来保存返回的字符:
fc = “Floodplain.shp”print fc[0]
print fc[10]
print fc[13]
运行结果如下:
‘F’‘.’
'p'
下图说明了字符串作为字符的有序集合的组织形式,第一个字符占据位置0,第二个字符占据位置1,后续的字符依次占据下一个索引位置:

字符串索引可以获取字符串变量中的单个字符,而字符串切片则可以让你获取一个连续序列的子字符串。切片的格式和用法同索引类似,不过需要增加第二个索引值用来告诉Python要返回多少字符。下面是一个切片的例子。Floodplain.shp 变量值已经赋值给theSring 变量。使用theSring[0:5] 语句就可以获取一个包含Flood 的变量:
theString = “Floodplain.shp"print theString[0:5]
运行结果如下:
FloodPython切片返回的字符是以第一个位置开始到第二个位置结束,但不包括第二个位置的字符。这点对于Python新手会感到困惑,而且也是常见的错误原因。我们上面的示例中返回的变量包含Flood 内容。第一个字符是F占据位置0。最后一个字符d占据位置4。需要注意索引数5位置上的字符并没有返回,这是因为Python切片仅返回到第二个位置但不包含第二个位置的字符
两个位置值都可以忽略。这种情况下相当于通配符的作用效果。theString[1:] 的情况下会告诉Python要返回从第二个字符开始的所有字符。theString[:-1] 的情况则告诉Python要返回除最后一个字符外的所有字符。Python是处理文本的优秀语言,它提供了许多处理字符的功能。其中大部分的功能已经超出了本书介绍的范围,下面列出的功能都可以实现:
- 字符串长度
- 大小写转换
- 去除首尾空格
- 查找字符
- 替换文本
- 基于分隔符拆分字符串
- 文本格式化
数值 Python同样也内置支持(built-in support)包括整型,长整型,浮点型和复数等数值数据。数值赋值给变量的方式跟字符基本一致,只是不需要将值括在引号内,而且该值必须是一个数值型数据。Python支持所有常用的数值计算,包括加,减,乘,除以及取模(求余)等。另外Python还支持绝对值,字符型转为数值型和四舍五入等功能。尽管Python也提供了一些内置的数学函数,但使用math 模块可以获取更多更高级的数学函数。使用这些函数,你首先需要按照下面的方式导入math 模块:
import mathmath 模块提供的函数包括上下取整函数,绝对值函数,三角函数,对数函数,弧度转换以及双曲线函数等。列表我们介绍的第三个Python内置数据类型是列表。列表是对象的有序集合,这些数据可以是Python支持的数据类型的任意一种或几种,比如数值,字符串,其他列表,字典或对象等。举个例子来讲就是一个列表对象可以同时存放数值和字符数据。列表是从零开始索引(zero-based),也就是说列表中的第一个元素占据位置0,后面的元素位置索引依次递增1。另外,列表是可动态伸缩的。使用方括号([ ])将一系列值括起来赋值给变量即可创建列表。变量名称后面紧跟方括号括起来的一个整数值的语句格式就能够获取列表中的一个元素值。下面的示例代码用来说明这一过程。你还可以使用切片来返回多个元素值。使用列表切片将返回一个新的列表对象。
fcList = ["Hydrants", "Water Mains", "Valves", "Wells”]fc = fcList[0]
print fc
fc = fcList[3]
print fc
运行结果如下:
HydrantsWells列表是动态可变的,可以对列表内容进行增加,删除和更改。完成这些操作也不需要创建一个新的备份列表对象。更改列表中元素值可以通过切片或索引操作来完成。索引操作更改一个元素值,而切片操作则可以更改多个列表元素值。列表支持许多对列表中的元素值进行操作的方法。你可以使用sort() 方法来对列表内容按照升序或降序排列。你可以使用append() 方法在列表末尾添加元素对象,使用insert() 方法在列表中指定位置插入元素对象。你可以使用remove() 方法来删除首次出现在列表中的元素值,使用pop() 方法则删除最后添加到列表中的元素并返回该元素值。你还可以使用reverse() 方式实现列表内容的前后顺序倒置。 元组 元组与列表类似,但是有一些重要的区别。与列表一样元组也是一个值的序列。两者的区别就是元组是不可变的,而且使用圆括号来创建而不是方括号。创建一个元组就是简单地把一些用逗号分隔符隔开的值括在圆括号内,如下面的示例代码所示:
fcTuples = ("Hydrants","Water Mains","Valves","Wells”)同列表一样,元组也是从0开始索引。获取元组中的元素值的方法同列表一样。下面的示例代码就说明了这个问题:
fcTuples = ("Hydrants","Water Mains","Valves","Wells”)print fcTuples[1]
运行结果如下:
Water Mains当需要要求数据保持静态的时候,通常使用元组来代替列表。这是因为使用列表就不能保证这一点,而使用元组就可以。 字典 字典是我们介绍的第二类Python集合对象。字典跟列表类似,不过字典是对象的无序集合。不同于使用位置索引值来从集合中获取对象,字典是使用键值(key)来获取字典内的元素值。字典中的每一个键值都有一个与之对应的数据值。与列表类似,字典可以使用dictionary 类中的方法实现字典内容的增减操作。在下面的示例代码中,你将会了解到如何创建字典并向字典中填充数据以及如何通过键值来获取值。字典是使用花括号({ })来创建的。在括号内每一个键值是用引号括起来后面紧跟一个冒号以及对应的数据值。字典内的键值对用逗号隔开:
##创建字典dictLayers = {'Roads': 0, 'Airports': 1, 'Rail': 2}使用键值获取值
print dictLayers['Airports’]
print dictLayers['Rail’]
运行结果如下:
12
基本的字典操作包括获取字典内的元素个数,使用键值获取数据值,判断某个键值是否存在,将键值转为列表对象以及获取数据值列表。字典内容可以更改,增加以及删除。这也就意味着Python无需创建一个新的dictionary 对象来保存字典的更改版本数据。给字典的键值赋值的操作可以通过将要赋值的键值扩到方括号内,然后让其等于某个值就可。
跟列表不同,由于字典内容是无序的所以不能使用切片操作。使用keys() 方法返回字典中所有键值的一个集合来遍历字典中的所有值或者也可以用来单独获取或者设置数据值
类和对象 类和对象是面向对象的编程中最为基本的概念。尽管Python更倾向于是一种过程语言,但是它同样支持面向对象编程。在面向对象编程中,类是用于创建对象实例的。你可以认为类是用于创建一个或多个对象的图纸。对象实例有相同的属性和方法,然而每个对象所包含的数据可以而且通常是不同的。对象在Python中是由属性和方法组成的复杂的数据类型,跟其他数据类型一样可以赋值给变量。属性包含了与对象有关的数据,而方法则是对象可以执行的动作。下面的示例中很好地阐释说明了上述概念。在ArcPy 中,Extent 类是由左下角坐标和右上角坐标指定的一个矩形范围。Extent 类包含了许多属性和方法。其中属性包括XMin,XMax,YMin,YMax,spatialReference 等等。横纵坐标的最大和最小坐标值(XMin,XMax,YMin,YMax )指定了矩形范围大小。spatialReference 属性保存了Extent 类中的SpaitalReference 对象的参考坐标系数据。Extent 类的对象实例可以使用点标注符(dot notation)来设置并获取以上这些属性值。示例代码如下所示:
import archly路径替换为本地计算机上的文件路径
fc = "c:/ArcpyBook/data/TravisCounty/TravisCounty.shp”
使用游标对象获取每一个要素的范围和空间参考(游标的概念在后面会详细介绍)
for row in arcpy.da.SearchCursor(fc, ["SHAPE@"]):
获取TravisCounty数据的范围
ext = row[0].extent
打印四至坐标和参考坐标系
print "XMin: " + str(ext.XMin) print "XMax: " + str(ext.XMax)
print "YMin: " + str(ext.YMin)
print "YMax: " + str(ext.YMax)
print "Spatial Reference: " + ext.spatialReference.name
运行结果如下:
XMin: 2977896.74002XMax: 3230651.20622
YMin: 9981999.27708
YMax: 10200100.7854
Spatial Reference: NAD_1983_StatePlane_Texas_Central_FIPS_4203_Feet
Extent 类有许多方法,其中大部分是验证Extent 对象与其他几何对象的几何关系的方法。比如有contains(),crosses(),disjoint(),equals(),overlaps(),touches() 以及within() 。你需要了解的另一个面向对象编程的概念是点标注符。点标注符(dot notation)提供了一种获取对象属性和方法的方式。点标注符用来指明某个属性或方法隶属于某个特定的类。使用点标注符的语句是对象实例后面紧跟一个点符号(.)以及属性或是方法名称。获取对象属性和方法的语句都是一样。如果点符号后面的语句末尾是圆括号括起来的零个或多个参数的话,那就说明正在访问对象的一个方法。下面的两个例子能够很好地说明这个问题:
属性(Property) => extent.XMin 方法(Method) => extent.touches()
语句 你使用Python编写的每一行代码都称作语句。Python中有许多类型的语句,包括变量命名和赋值语句,基于验证结果执行代码的条件语句,用来执行多次相同语句块的循环语句等等。你在编写脚本语句时需要遵循许多规则。你已经遇到过一种类型的语句:变量命名和赋值语句。 条件语句 if/elif/else 语句是Python中重要的条件语句,该语句用于判断true/false 状态。使用条件语句能够控制程序的流程。这里举几个例子说明:如果变量是一个点要素类,那么就获取其X,Y坐标值;如果要素类的名称为Roads ,那么就获取其Name 字段。if/elif/else 这样的条件语句用来判断true/false 状态。在Python中,"true"值是指任何非零数字或非空对象。"false"值是指零值或空对象,即非true值。比较测试返回1或者0(true或者false),布尔与或(and/or)操作符返回true或者false。
if fcName == 'Roads':gp.Buffer_analysis(fc, "c:empoads.shp", 100)
elif fcName == 'Rail':
gp.Buffer_analysis(fc, "c:empail.shp", 50)
else:
print "Can't buffer this layer”
Python代码必须遵循一定的语法规则。代码遇到分支语句之前,逐句依次执行。分支语句通常在if/elif/else 中实现。另外,使用for 或者while 循环语句也能更改语句的执行顺序。Python能够自动识别语句和代码块的范围,因此不需要在语句块前后增加括号或者分隔符。实际上,Python使用缩进来组合语句块。许多程序语言使用分号作为语句的结尾,而Python使用行结束符来标识语句结尾。复合语句(compound statement)会包含“:”符号。复合语句遵循以下模式:头语句(header)以冒号结束,头语句内的编写的语句块使用缩进。缩进对Python解释语句的方式非常重要,这里需要特别说明一下。前面内容提过,Python使用缩进来检测一个连续的语句部分。默认情况下,所有的Python语句中遇到循环语句,条件语句,try/except 语句和with 语句前都应该左对齐。这里包括for 和while 循环语句,if/else 语句,try/except 语句和with 语句。同一语句块内的所有语句在语句块结束之前使用相同的缩进。
循环语句
循环语句可以让程序根据需要来重复执行某段代码内容。while 循环语句中,只要循环体开始部分的条件判断为真就会重复执行语句块。当条件判断为假,Python则开始执行while 循环体后面的代码。在下面的示例代码中,将10赋值给变量x。while 循环语句判断x是否小于100,如果x小于100则将当前x的值输出到屏幕同时将x的值增加10。语句执行后再进行while 语句的条件判断,第二次判断时当前x的值为20,因此条件判断结果仍为真。该过程直到x大于100时结束。在那个时候,条件判断结果为假,循环语句执行结束。这一点对于中止跳出while 循环语句是非常重要的。否则的话,你将会先入死循环中。死循环就是计算机程序中的无限循环一段指令,死循环的出现要么是由于循环语句中无中止条件,或是有中止条件但从未满足该条件,亦或是中止条件满足后导致循环重新开始:
x = 10while x < 100:
print x x = x + 10
for 循环语句会按照预先设定的循环次数来执行一段语句块。for 循环有两种情况,一种是计数循环(counted loop),根据设定的循环次数来循环运行一段语句块,另一种是列表循环(list loop),允许你迭代列表中的所有对象。下面的示例代码中,列表循环中会对字典中的每一个值执行一次代码,然后循环结束:
dictLayers = {"Roads":"Line","Rail":"Line","Parks":"Polygon”}lstLayers = dictLayers.keys()
for x in lstLayers:
print dictLayers[x]
有些时候中止循环是很有必要的。break 和continue 语句可用来中止循环。break 语句跳出离它最近的循环体,而continue 语句则是跳回到离它最近的循环体的最高层继续下一个循环。两个语句可以出现在语句块中任何地方。try语句try 语句是用来处理异常的完整的复合语句。异常是一种主要用来捕获错误或触发错误的高级控制机制。Python中的异常可以捕获或者触发。当代码中的发生错误时,Python会自动触发异常,这些异常可以在代码中处理或者忽略掉。你作为程序员来决定是否捕获自动触发的异常。异常还可以手动触发。在这一案例中,你将会了解到捕获人工触发异常的常规处理流程。Python中的try 语句有两种基本类型:try/except/else 和try/finally 。一个基本的try 语句从try 语句头开始,后面紧跟着语句块,之后为一个或多个可选的except 语句,这些except 语句用来命名捕获的异常,最后是一个可选的else 语句:
import archlyimport sys
inFeatureClass = arcpy.GetParameterAsText(0)
outFeatureClass = arcpy.GetParameterAsText(1)
try:
如果输入的要素类名称已经存在,触发一个错误
if arcpy.Exists(inFeatureClass): raise overwirttenError(outFeatureClass)
else:
其他处理步骤
except overwrittenError as e:
返回消息代码12,同时还提供输出要素类名称增加到消息中
arcpy.AddIDMessage("Error",12,str(e))
try/except/else 语句工作流程如下所述。try 语句开始后,Python会标注说明现在已经位于try 语句块中,同时也就知道当出现任何异常情况时Python会将异常提交给except 语句来处理。如果找到了匹配异常的except 语句,Python就会执行该except 语句中代码。异常处理完成后就会开始执行整个try 语句块后面的代码。在这种情况下else 语句则不会执行,而try 语句块内的语句都会执行。如果没有异常发生,指针将会先跳到else 语句执行完else 中的代码之后再调到整个try 语句块后面的首行代码。另一种类型的try 语句是try/finally 语句,该类型语句会执行终止操作(比如关闭文件,释放等)。try 语句中使用finally 语句,无论异常情况是否发生都将会执行finally 语句块中的代码。try/finally 语句工作流程如下所述。异常发生时,Python会先执行try 语句块,之后再执行finally 语句块,随后继续执行整个try 语句块后面的代码。如果没有异常发生,Python则执行完try 语句块后接着执行finally 语句块。你希望无论异常是否发生都要保证某项操作执行的时候,使用try/finally 语句就非常有帮助。比如像关闭文件或者是断开数据库链接这样的释放清理(cleanup)操作通常都会放到finally 语句块中,以保证无论异常是否出现释放清理操作都会执行:
import archlyfrom arcpy
import env
class LicenseError(Exception):
pass
env.workspace="E:/dem.gdb"
try: if arcpy.CheckExtension("3D") == "Available":
arcpy.CheckOutExtension("3D")
else: raise LicenseError
arcpy.HillShade_3d("N53E126","dem_hill",300)
arcpy.Aspect_3d("N53E126","dem_aspect”)
except LicenseError: print "3D Analyst license is unavailable”
except: print arcpy.GetMessages(2)
finally: arcpy.CheckInExtension("3D")
with语句
当需要执行成对出现的两个关联操作以及两个操作中间的一段代码的时候,使用with 语句就很方便。使用with 语句常见的情况是文件的打开,读取和关闭。文件打开和关闭是关联操作,而读取文件以及处理文件内容则是两个关联操作中间的一段代码。使用10.1版本新引入的cursor 对象来编写ArcGIS地理处理脚本情况就很适合使用with 语句。我们将会在后面的章节中讨论cursor 对象的更多细节,这里我就先简单介绍一下。游标对象是内存中要素类或表的属性表数据的备份。ArcGIS中提供了许多类型的游标。插入游标用来插入新的记录,搜索游标是只读的记录备份,更新游标可以用来编辑或删除记录。使用with 语句来打开游标,执行某些操作后会自动释放游标。使用with 语句来自动关闭文件或者游标对象,带来更为简洁高效的编码体验。with 语句跟try/finally 语句很像,但是代码更少。在下面的示例代码中,使用with 语句来创建一个搜索游标,读取游标对象中的信息之后隐式地关闭游标:
import arcpyfc = "c:/data/city.gdb/streets”打印每行数据的ID值并获取几何属性
with arcpy.da.SearchCursor(fc,("OID@","SHAPE@AREA")) as cursor:
for row in cursor:
print ("Feature {0} has an area of {1}".format(row[0],row[1]))
文件读写(File I/O)
你会经常需要读写计算机中的文件。Python包含了一个内置的对象类型提供了获取文件的方式。尽管我们只介绍Python文件操作功能的一小部分,但这些功能都是最为常用的功能,包括文件的打开和关闭,文件的读取和写入等。Python的open() 函数会创建一个文件对象,该对象相当于你的电脑中文件的一个链接。你在对文件进行读写数据之前必须先对该文件调用open 函数。open() 函数中的第一个参数是你要打开文件的路径,第二个参数对应某个模式,通常是读(r),写(w)或者添加(a)。r 值表示你打开文件只是进行读取操作,而w 值表示你打开文件需要进行写入操作。打开一个已有文件进行写操作时,Python会覆盖掉文件中已有数据,因此选择写入模式的时候需要注意。添加模式(a)将会打开文件进行写入操作,但不会覆盖掉任何已有数据,只是将新写入的数据添加到文件的末尾。下面的示例代码会说明使用open函数在只读模式下打开文件的用法:
f = open('Wildfires.txt','r')在完成文件的读写操作后,你需要使用close 方法来关闭文件。文件打开之后,你可以通过不同方式和方法来读取数据。最典型的就是通过readline() 方法来一次读取一行数据。readline() 方法可以用来一次读取文件的一行数据并赋值给一个字符型变量。你就需要在Python代码中使用循环模式来逐行读取整个文件。如果你想一次读取整个文件并放到一个变量中的话,你就可以使用read() 方法,该方法会读取整个文件直至文件结束标志(EOF)。你还可以使用readlines() 方法来读取整个文件,并在遇到文件结束符前按行分成各个单独的字符串。下面的示例代码中,我们以只读模式打开一个Wildfires.txt的文件,并调用readlines() 方法将文件的整个内容读取到lstFires 变量中去lstFires 变量是一个Python列表,文件的每行内容都是该列表中的一个字符串元素值。在本案例中,Wildfires.txt是一个逗号分隔符的文本文件,该文件中包含了每次火情的经纬度位置以及可信度数据。我们将迭代读取lstFires 中的每行文本,调用split() 函数按照逗号分隔符来分别提取纬度,经度和可信度数据。经纬度值用于创建一个新Point 对象,该对象将会使用插入游标插入到要素类中:
import arcpy,ostry:打开要读取的文件
f = open('Wildfires.txt','r')
lstFires = f.readlines() cur = arcpy.InsertCursor("e:/dem.gdb/FireIncidents") for fire in lstFires: if 'Latitude' in fire: continue vals = fire.split(",") latitude = float(vals[0]) longtitude = float(vals[1]) confid = int(vals[2]) print(longtitude,latitude) pnt = arcpy.Point(longtitude,latitude) feat = cur.newRow() feat.shape = pnt feat.setValue("CONFIDENCEVALUE",confid) cur.insertRow(feat) del feat del curexcept: print arcpy.GetMessages()finally: f.close()
正如读取文件的情况一样,你可以使用一些方法来把数据写入文件中。write() 方法大概是最方便的,该方法引用一个字符串参数然后把该参数值写入到文件中。wirtelines() 方法可用于将列表结构的内容写入到文件中。在下面的示例代码中,我们创建了一个fcList 的列表,该列表中包含了一些要素类名称。我们可以调用writelines() 方法将列表内容写入到文件中:
outfile = open('c:empdata.txt','w')fcList = ["Strams","Roads","Counties”]
outfile.writelines(fcList)
outfile.close()

阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬

阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬
以下是python学习路线和视频。共分为7大阶段.
现在免费分享给大家哦!获取在文末!!!

阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬
阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬
第一阶段、python开发基础和核心特性
阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬
1.变量及运算符
2.分支及循环
3.循环及字符串
4.列表及嵌套列表
5.字典及项目练习
6.函数的使用
7.递归及文件处理
8.文件
9.面向对象
10.设计模式及异常处理
11.异常及模块的使用
12.坦克大战
13.核心编程
14.高级特性
15.内存管理
第二阶段、数据库和linux基础
阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬
1.并发编程
2.网络通信
3.MySQL
4.Linux
5.正则表达式
第三阶段、web前端开发基础
阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬
1.html基本标签
2.css样式
3.css浮动和定位
4.js基础
5.js对象和函数
6.js定时器和DOM
7.js事件响应
8.使用jquery
9.jquery动画特效
10.Ajax异步网络请求
第四阶段、Python Web框架阶段
阿里巴巴大佬打造400集Python视频教程视频拿去,学完万物皆可爬
1.Django-Git版本控制
2.Django-博客项目
3.Django-商城项目
4.Django模型层
5.Django入门
6.Django模板层
7.Django视图层
8.Tornado框架
第五阶段、Python 爬虫实战开发
转发评论+私信“学习”即可领取Python视频教程
转发评论+私信“学习”即可领取Python视频教程














 8599
8599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









