





桥梁监测数据的时间序列模型
桥梁监测数据的时间序列模型是本文中最重要的一个模型,这是由桥梁监测数据的时序特性决定的。时间序列分析用来对时序数据集进行分析,时序数据集是指数据及某一变量的观测值按时间顺序(时间间隔相同)排列成一个数值序列,时序分析展示研究对象在一定时期内的变动过程,从中寻找和分析事物的变化特征、发展趋势和规律。它是系统中某一变量受其他各种因素影响的总结果。他研究实质是:通过处理预测目标本身的时间序列数据,获得事物随时间过程的演变特性与规律,进而预测事物的未来发展。他不研究事物之间相互依存的因果关系。他的假设基础是:惯性原则,即在一定条件下,被预测事物的过去变化趋势会延续到未来,暗示着历史数据存在着某些信息,利用它们可以解释与预测时间序列的现在和未来。
桥梁建康监测数据是在等时间间隔测得的数据,它是一个大型的时序数据集,对这些大量的历史监测数据进行时间序列分析显得特别重要。通过对监测数据进行时间序列分析,可以挖掘桥梁监测结构参数和环境参数之间的关系,获得桥梁结构参数和环境参数的变化趋势,发现桥梁结构参数和环境参数的异常变化。
监测数据去噪声、处理空缺值后,计算出监测数据按,天,周,月,汇报的平均值,最后对数据进行Z-SCORE规范化。数据经过这些预处理步骤后就能对其进行时间序列分析。
一、时间序列的相似性
如图4.5所示,图中ID数据作为时间标量,表示记录测得的先后顺序,纵向数据是一些桥梁参数的值,这些值都经过规范化处理。从图中很容易看出各桥梁参数值的曲线比较相似,各种质的变化也基本相同。从图中所画出的曲线可以发现温度与从桥梁不同部位测得的应变数据有很强的关联,各个不同部位测得的应变值的变化基本相同。
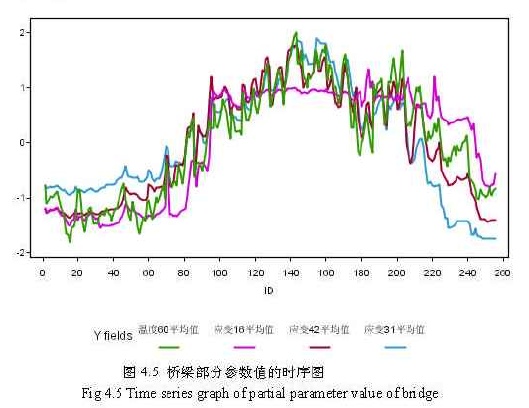
虽然各条曲线都比较相似,但可以发现图中有的曲线之间的相似程度是不同的,有的曲线之间的相似程度不好判断。桥梁监测数据是一个大型的序列数据集,光靠人工手段来辨别各种参数值曲线的相似程度是不现实的,这就要引入相异度的概念。相异度可用来表示序列之间的相似程度,相异度越小表示相似的程度越高(由于这种关系,所以没有用相似度来描述)。序列的相异度可用多种方法度量,这里采用欧几里得距离度量,它的定义方法如下:

(4.11)
这里的
和
是两个p维的数据对象,,用此方法可以很容易计算出各条曲线制定的相异度,比如表4.4展示了图4.5中的一些变量的时序曲线之间的相异度。

根据欧几里得距离的特性可以得出相异度具有以下性质:
1)相异度不小于零。
2)当两条曲线重合时,相异度为0。
3)两条曲线越相似,相异度越小。(异常值去掉后)
从图4.5中可以看出,温度60℃平均值与应变42平均值的曲线最相似,所以它们的相异度最小。
通过获得所有参数值曲线之间的相异度,可以挖掘出一些很有意义的信息和模式,主要有以下几个方面的用途:
1)量化桥梁各种参数之间的相关程度
比如温度和应变数据曲线的相异度很小,说明温度和应变之间有很强的相关程度。
2)可以建立三元组S(r,d,p),其中r表示那两个参数的时间序列进行对比,d表示一个相异度常数,p表示相异常异常程度。各种数据的时间序列曲线之间的相依度具有一个范围,曲线之间的相异度小于一个设定值。根据异常度大小,可以得出数据是否异常。
3)相似性查询
对于某个变量的时间序列数据,可以通过查询所有变量与它之间的相异度,找出相似性最强的一些变量。当桥梁某个部位发生异常变化后,该部位的结构参数和环境参数值就会发生异常变化,参数值的曲线就会和以往不同,和其他部位的参数的时间序列曲线的相异度会发生较大变化,可以通过相异度的异常变化来发现桥梁的异常变化。
4)数据归约
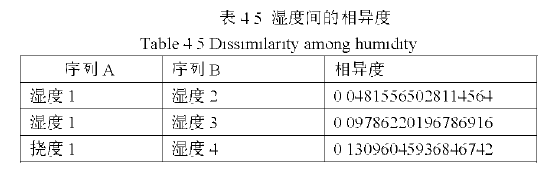
桥梁监测系统数据的属性个数太多,,不利于数据的分析,实际上许多属性的数值是基本相同(规范化后),及桥梁数据存在冗余,可以利用同类数据的相似度来减少属性数,如下表(表4.5)所示,湿度1和湿度2、湿度3、湿度4相似度极高,完全可以来代替湿度2、湿度3、湿度4。
5)同类数据对比
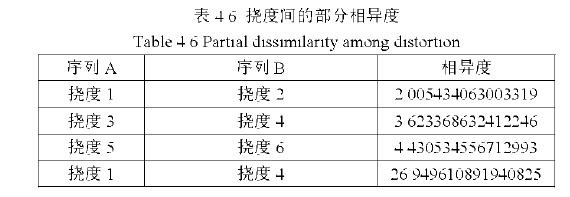
利用同类参数(指温度、应变、加速度、挠度和湿度中的一个)之间的相似度进行比较,可以发现同类数据中一些规律和异常现象。表4.6展示了部分挠度之间的相异度,挠度1和挠度2传感器位于桥梁主梁的同一位置的两侧,挠度3和挠度4,挠度5和挠度6也是这种情况,可以发现它们之间的相似度很小(只有这样才是正常的,否则就存在异常情况。)而挠度1和挠度4之间的却很大,因为它们的位置相差较远。同类参数的时序曲线间相异度在不同时间段可能有很大不同,通过查看相异度的变化趋势可以判断该参数值是否异常,可以用于桥梁损伤的识别。
二、时间序列的ARIMA模型
自我回归整合移动平均(ARIMA)模型,,为BOX及Jenkins提出,主要目的用于产生预测。ARIMA的概念简单来说就是,要预测一个变量时,先取得过去实际发生的数值,在为此时间序列找一个适当的ARIMA模型,并用模型产生未来的预测,适合长期预测。ARIMA模式可用,p、d、q三个参数描述,p为AR阶数,d为差分阶数,q为MA阶数。为了理解ARIMA模型就必须介绍一下自回归模型、移动平均模型和自回归移动平均模型。
1)自回归AR(p)模型
(1)模型形式(
越小越好,但不能为0:
为0表示只受以前Y的历史数据值的影响,不受其他因素影响)
(4.12)
式中符号:p为模型的阶次,滞后的时间周期,通过实验和参数确定;yt为当前预测值,与自身过去观测值
是同一序列不同时刻的随机变量,相互间有线性关系,也反映时间滞后关系;
同一平稳序列过去p个时期的观测值;
是自回归系数,是通过计算得出的权数,表达yt依赖于过去的程度,且这种依赖关系恒定不变;
随机干扰误差项,呈正态分布,通过估计指定的模型获得。式中假设:yt的变化主要与时间序列的历史数据值有关,与其他因素无关;
不同时刻互不相关,
与yt历史,序列不相关。
(2)模型含义
仅通过时间序列变量的自身历史观测值反映有关因素对预测目标的影响和作用,不受模型变量相互独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择,多重共线性等造成的困难。
2)移动平均MA(q)模型
(1)模型形式
(4.13)
(2)模型含义
用过去各个时期的随机干扰或预测误差的线性组合来表达当前预测值。AR(p)的假设条件不满足时可以考虑用此形式。
3)自回归移动平均ARMA(p,q)模型
(1)模型形式
(4.14)
式中符号:p和q是模型的自回归阶数和移动平均阶数;
是不为零的待定系数;
是独立的误差项;yt是平稳、正态、零均值的时间序列。
(2)模型含义,
该模型是对前两种模型的综合,前两种模型分别是该种模型的特例。一个ARMA过程可能是AR与MA过程、几个AR过程、AR与ARMA过程的迭加,也可能是测度误差较大的AR
过程。实际应用中p、q一般不超过2。
4)自回归综合移动平均ARIMA(p.d.q)模型
(1)模型含义,
ARIMA由上述三种模型组合而成,p和q是模型的自回归阶数和移动平均阶数,d是差分阶数。模型形式可以转化为ARMA(p,q) 模型,但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用ARMA(p,q) 模型,,但可以利用有限差分使非平稳时间序列平稳化,实际应用中d一般不超过2。
若时间序列存在周期性波动,则可按时间周期进行差分,不也是将随机误差有长久影响的时间序列变成暂时影响的时间序列。即差分处理后新序列符合ARMA(p,q)模型,原序列符合ARMA(p,q)模型。
ARIMA模式与ARMA模式间最大不同在于前者将差分引入模式,以处理非平稳序列。是将,当期数值与前期数值相减。差分的阶数(d)越高,计算式将愈形复杂,下面列出一阶(d=1)差分及二阶(d=2)差分的计算公式:
一阶差分:
(4.15)
二阶差分:
(4.16)
其中
即差分d阶,d=1,2,…,;
与
相隔i时间单位的历史数值。由上式可知,
并不等于当期数值(
)减去前二期数值(
),即:
(4.17)
实际上AR,MA,ARMA模型可以认为是ARIMA模型的特例,ARIMA(q,0,0)就是AR(q)。同理ARIMA(0,0,q)就是MA(P).ARIMA(q,0,p)就是ARIMA(q,p)。

三、桥梁监测数据时序预测模型
1)ARIMA模型参数的选定
对马桑溪大桥健康监测数据中的应变16进行分析,其序列曲线为图4.6所示:
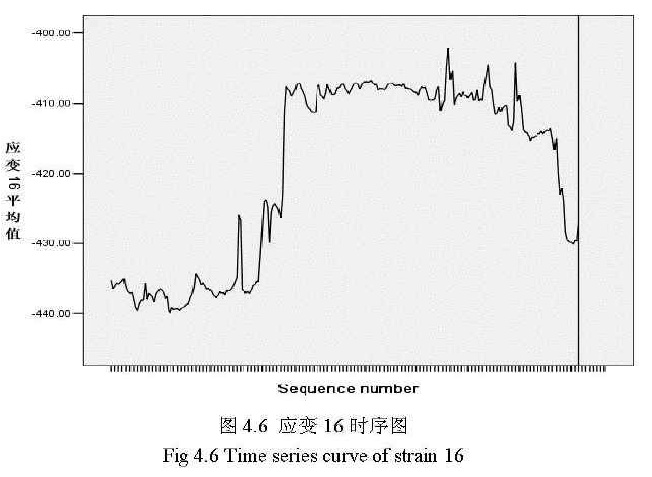
可以发现应变数据不是静态平稳的数据,并且数据没有周期性变化,即数据无季节性波动。因为应变,数据不是静态平稳的数据,需要对数据进行差分后使数据变成较平稳的数据。图4.7是对应变16数据两阶差分后的时序图:
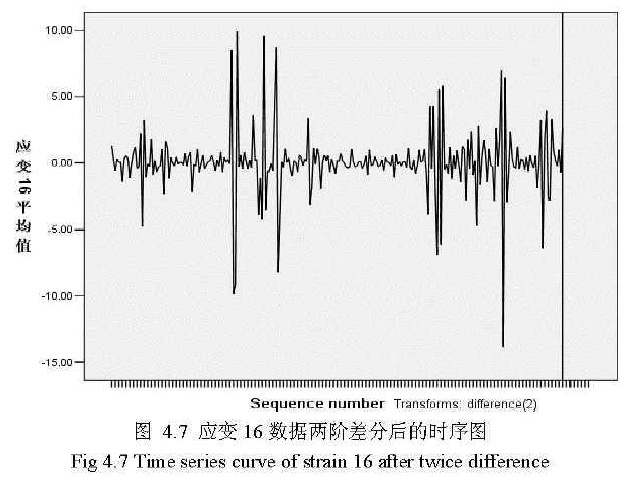
可以看出经过二阶差分后应变的时序图平稳了许多。接下来最重要的是确定ARIMA的参数p、d、q,实际使用中p、d、q的取值通常为0、1和2. 用时序图的走势来决定ARIMA的d参数:
(1)若趋势为水平,则设定d=0;
(2)若趋势为直线,则不论是直线上升或直线下降,,皆设定d=1;
(3)若趋势为二次式(即时序图呈曲线变化),则设定d=2.
可以看出应变16的时序图的走势呈二次式,所以d=2。
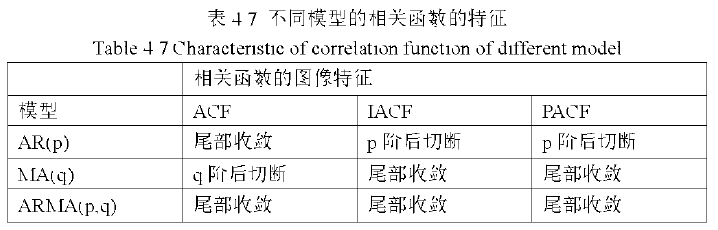
决定p、q的过程比较复杂,可以按表4.7中的标准来决定p、q,也就是通过查看时间序列的相关函数图像的特征来确定采用何种模型,比如根据时序数据的相关函数图像特征确定该采用模型MA(q)。就说明参数p取0,而参数q可以取1或者2.
一般情况下也可采用试探法来决定参数p、q,因为p、q最常见的取值为0、1和2,可以对比不同组合的P、q值所产生的结果,选取最好的P、q参数对。ARIMA模型的信息准则AIC和SBC可用于模型的选择,值越小越好,在这里可以作为决定p、q的一个评判标准。
2)进行预测
对变量的值进行预测是时间序列分析的终极目标。预测方法包括点预测及区间预测。预测之结果,可绘制成预测图,预测可分为样本内预测和样本外预测。在进行预测之前,必须先根据研究目的,设定领先期数L,以确定样本外预测值期数。ARIMA模型能产生的预测包括点预测及区间预测。其中,点预测又称为预测中点,区间预测包括预测上限,预测下限。三者数值由小到大,分别为预测下限,预测终点,预测上限。
通过比较,对于应变16的时序序列,当p、q都为1时,模型具有最好的效果,所以应变16时序数据的时序模型为ARIMA(1,2,1)。通过计算和分析,模型的参数经过估计(比如采用最小二乘法进行估计,)出的值为:
其中θ为AR部分的参数,
为MA部分的参数。
4.8为应变16的拟合值和真实值的时序图:
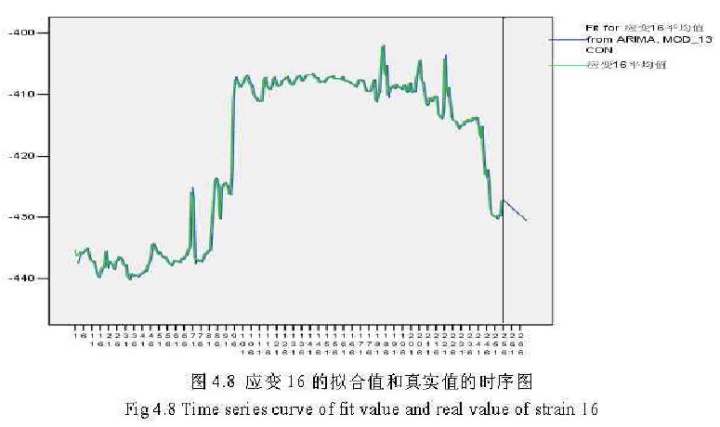
屠龙应变数据的真实值和预测值(由所建立的模型所预测的值)拟合程度很高,图中竖线以
后的数据为后十五天预测值。
表4.9就是根据以往的应变16历史数据,由ARIMA(1,2,1)所预测的后十天的应变16平均值:
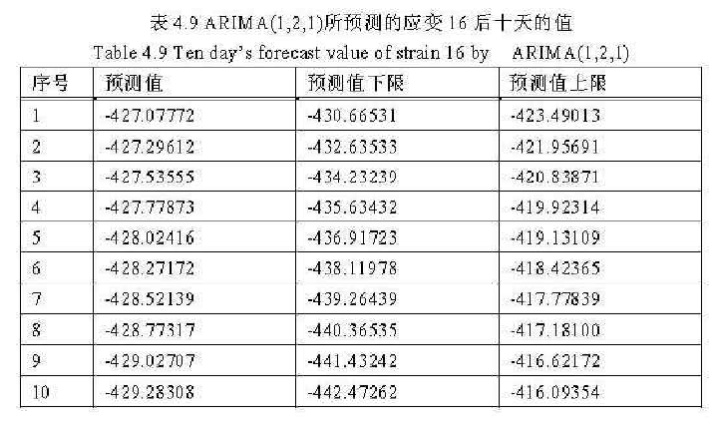
由表中可以看出:一天后,应变16的平均值的预测值为-427.07772,预测区间为[-430.6653,-423.49013](95%置信水平)。
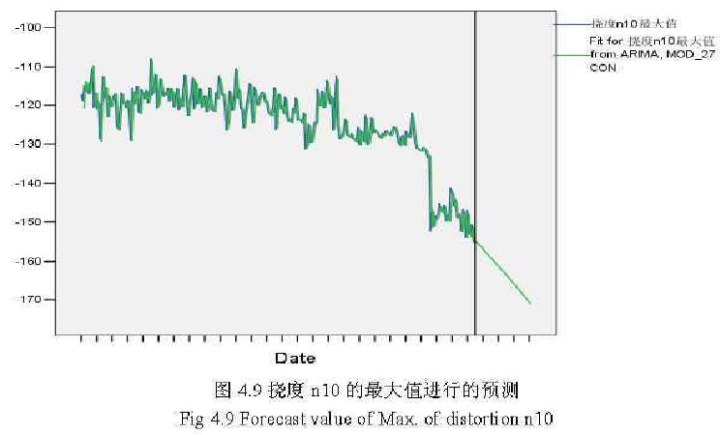
为了更好的对桥梁参数的最大最小值进行监测,可以对这些参数值进行预测,图4.9就是对挠度n10最大值进行的预测,其预测的模型是,ARIMA(1,2,1)(1,0,1),模型后面的括号中的值分别是AR季节参数,差分季节参数和MA季节参数(因为最大值的部分或全部值往往呈周期性波动),图中竖线以后的值是预测值,可以预见20多天后,挠度n10最大值可能降到-170以下,这是值得,监测人员注意的信息。
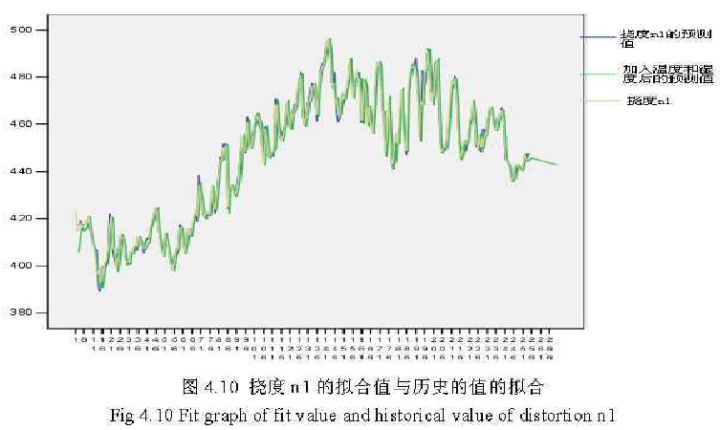
桥梁的环境或结构参数之间通常是相互的影响的,上述的预测过程只是针对单变量进行预测,为了更好的完成对桥梁参数值的预测,可以在预测某个桥梁参数时选择相关的参数作为预测辅助变量,在决定相关桥梁参数时用相关函数来找出最相关的参数。从图4.10中可以看出把湿度和温度参数作为预测辅助变量时,挠度n1的的预测值与历史值的拟合程度较高。
《非本人原创,经本人整理,以技术会友,广交天下朋友》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









