





一般的单机、单节点、单实例有哪些问题呢?
1、单点故障(会挂)。
2、容量有限。
3、压力(socket io的压力,和计算的压力)。一台redis的话,怎么解决呢? 使用AKF
1、沿着X轴做redis或者数据库的副本,客户端只访问独立的redis,如果挂掉了话。客户端可以接着访问刚才做的副本redis。这个可以解决一台容易挂掉的问题。然后主redis可以进行增删改,备用的那些副本可以进行读取,这个主备模式解决不了容量有限的问题,而压力太大的问题也是似乎只能解决一点点,毕竟读写分开了,但是还是鸡肋。
2、Y轴,可以对公司存放的数据按照业务功能划分不同的redis进程实例进行存储,如果是mysql的话就是分库。当然X,Y轴也可以结合起来,Y轴上也可以横向扩展刚才的X轴
3、Z轴,数据越来越多的话,可以考虑Z轴分库,redis有16个库,可以把业务中用户id,0-1000,1000-2000类似这种分类,然后存到不同的redis库的里。所以Z轴就是按照优先级,逻辑再拆分。
现在来看X轴,主备模式,客户端对主进行了写,但是备用的redis数据怎么办?备用的redis里也得有刚才写的那个k和v。
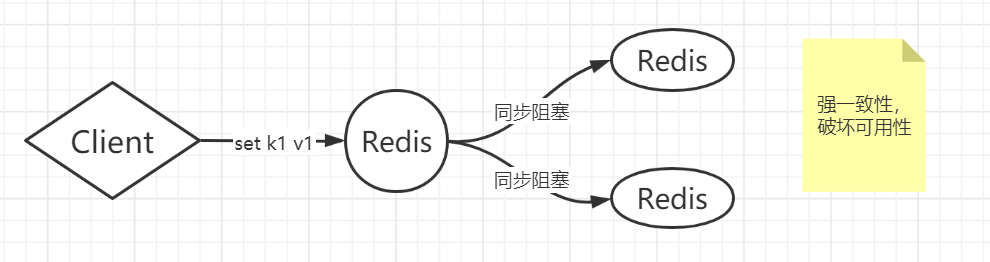
强一致性,所有节点阻塞直到数据一致
当客户端对主进行写,主写成功后暂时不返回,阻塞等待,然后通知后面的备用的也去写,等待备用的写成功后,返回给主,主然后在返回给客户端。
强一致性会带来很多问题,例如其中一个备用的redis由于网络延迟或者通信,进程退出了,写慢了,执行有问题,卡了,丢包等,写失败等。假如10分钟后才会写成功,就意味着客户端要等10分钟,但是一般通信中有超时的概念,如果长时间没返回的,就认为都失败。也就是服务不可用,redis不可用了,所以强一致性容易破坏可用性。
当初进行X轴拆分的时候就是由于单点故障,所以拆分了,为了可用性,但是带来的强一致性,又极易破坏可用性,这是很有问题的。
弱一致性

主备和主从
主备:客户端只会访问主,而不会访问备,主挂掉之后,备可以接替主,供客户端访问;备一般不参与业务。
主从:客户端可以访问主,也可以访问从,而企业里一般采取主从复制,复制的意思是主有的数据,从也有要有,也就是上面主备的概念。
在主上是读写都包含,备一般不发生操作,从上有读的操作;那这样的话,主自己又成了一个单点。。。那么前面说了一堆就是为了不成为单点,而到现在主又成了单点,那么这样的话,主挂了的话,主备这种模式就没了。因为客户端不去访问备,备不提供写,有可能提供读。
那么带来的解决方案是,对主做HA(高可用),高可用的目的是把备机或者从机变成主机,供客户端使用。主挂了,其他的备或从顶上去。
那这套方案怎么做才能实现这种自动的故障转移,是怎么监控集群挂了,然后用备或从顶上去的呢?
三个监控程序去监控一个主Redis,如果Redis挂了,那他们3个监控都是通过网络去监控这个Redis,那么就会有一个,两个,或者三个监控直到Redis挂了,为什么呢?因为有可能某个监控和Redis延迟了,或者网线不通,都有可能判断Redis挂了,所以有时候会有1个监控判断可能Redis挂了,也有可能2个监控判断Redis挂了,也有可能3个监控都判断Redis挂了。当然如果Redis真的挂了,那么3个监控当然判断Redis挂了。
一个Redis是好是坏,由这三个监控判断,如果一个Redis挂了,需要3台一块决策,都必须给出Redis挂掉的判断,显然是最精确的判断,但这种情况由所有监控都给出判断说redis不可用了,才给出redis不可用的判断也是强一致性。有可能其中一个监控网络延迟了不会给出判断,所以能够使用强一致性吗?显然不能,因为强一致性会破坏可用性,(参考redis主从主备的模式下,强一致性等于客户端不可用了,因为需要等从或者备返回给主ok,然后主才给客户端返回ok,而此时客户端需要等待主返回ok假如花了10分钟后才会写成功,就意味着客户端要等10分钟,但是一般通信中有超时的概念,如果长时间没返回的,就认为都失败。也就是服务不可用,redis不可用了,所以强一致性容易破坏可用性。破坏可用性带来的问题就是redis服务不可用)所以如果3台监控都给出决策这种情况下,属于强一致性,等于监控不可用。所以强一致性是在分布式环境下是很难实现的一件事情。所以这时候可以来弱一致性,也就是3个监控中由一部分监控给出判断,也就是少数服从多数,当2个监控都判断Redis挂了的话,那么这个Redis就挂了,就直接把从替换成主。
那么一部分决策中的一部分到底是多少个呢,是1个,2个还是3个呢?
肯定不是1个,如果有一个监控说Redis挂了,那么有可能是这个监控自身网络连接的问题,或者延迟的问题。一个人说话不算数的。
到这里,可以引出CAP原理了。
C : Consistent 一致性
A : Availability 可用性
P : Partition tolerance 分区容忍性
分布式系统的节点往往是分布在不同的机器上进行网络隔离开的,这意味着必然会有网络断开的风险,这个网络断开的场景的专业词汇叫做 网络分区 。
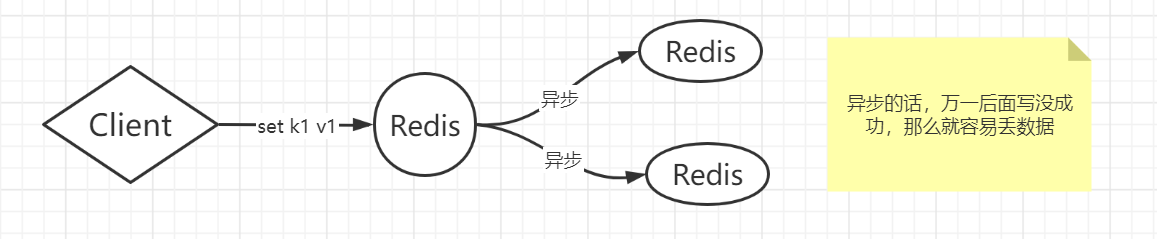
在网络分区发生时(也就是网络断开时),两个分布式节点之间无法进行通信,对一个节点进行的修改操作将无法同步到另外一个节点上, 所以数据一致性将无法满足,因为两个分布式节点的数据不再保持一致。除非牺牲 可用性,也就是暂停分布式节点服务,在网络分区发生时,不再提供修改数据的功能,直到网络状况完全恢复正常再继续对外提供服务。 用一句话概括CAP原理就是:当网络分区发生时,一致性和可用性两难全。 Redis的主从数据是异步同步的,所以分布式的Redis系统并不满足一致性要求,因为异步可能会导致不一致性要求。当客户端在Redis的主节点修改了数据,立即返回,即使主从网络断开的情况下,主节点依旧可以正常对外提供服务,但是从节点不一定正常对外提供服务,但是只要主节点能提供服务,那么Redis就是可用的,所以Redis满足可用性。异步的情况就是可用性可以满足,但是一致性难以满足。 Redis保证最终一致性,从节点会努力追赶主节点,最终从节点的状态会和主节点的状态保持一致。如果网络断开了,主从节点的数据将会出现大量不一致,但是一旦网络,从节点会采用多种策略努力追赶,继续尽力保持和主节点一致。
肯定不是1个,如果有一个监控说Redis挂了,那么有可能是这个监控自身网络连接的问题,或者延迟的问题。一个人说话不算数的。那么假如有一个监控和主redis网络连接有问题的,说主Redis挂了,用从顶上了主,而其他两个监控都说redis没挂,那么这时出现的问题是:被从替代的那个主redis还和其他两个监控保持连接,如果换成数据的话,那么这时候就有两个主redis了:一个是从redis变成了主(假redis),而另一个主redis就是原来的那个主redis(真redis),假redis写了一个数据,set k1 v1 ,不会同步到真redis里。而真redis里本来就有一个 k1 v2,那么造成的问题就是,当客户端去读取k1的时候,会读到两个不同的值:v1和v2,那么这样两个分布式redis节点之间无法进行通信,对一个节点进行的修改操作将无法同步到另外一个节点上,所以数据一致性将无法满足,因为两个分布式节点的数据不再保持一致。而这种情况是在网络分区时发生的(也就是网络断开时)。所以1个监控说redis挂了的话,就用从顶替的话,容易造成网络分区。但是也不是不好,因为有分区容忍性。





所以可行的方案是,监控集群中过半数的监控说Redis挂了,那么才能说Redis真的挂了。下来搞一个伪分布式玩玩:一台物理机当中启动3个Redis实例。一个主Redis。
开启3个shell
在1号shell 创建一个test文件夹
在2号shell中操作
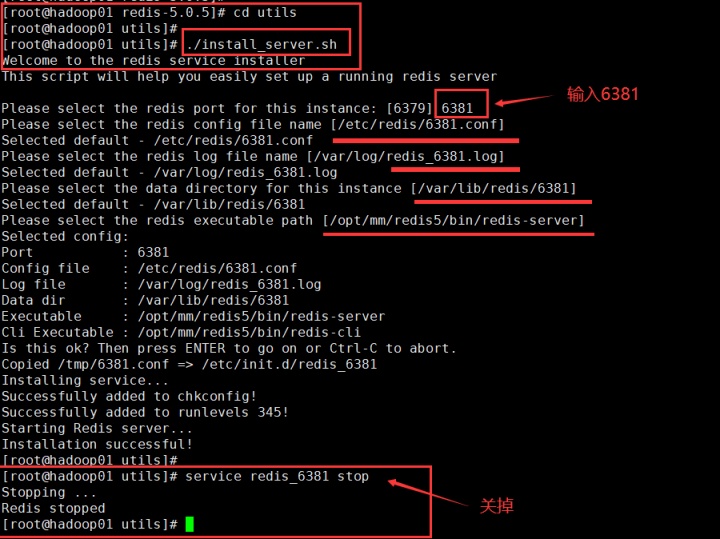
回到1号shell中,把配置文件全部拷贝过来
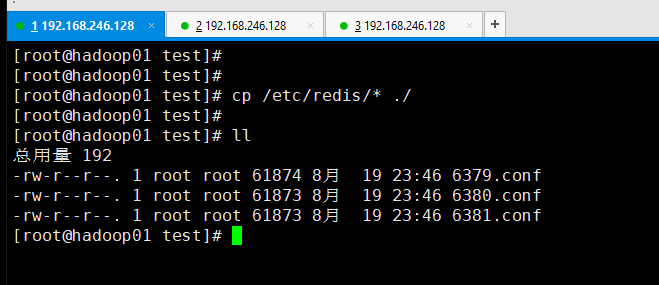
配置6379.conf
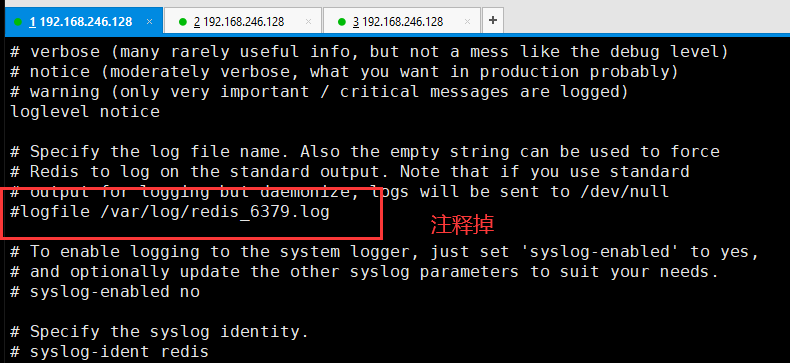
然后把aof持久化关闭,保存退出
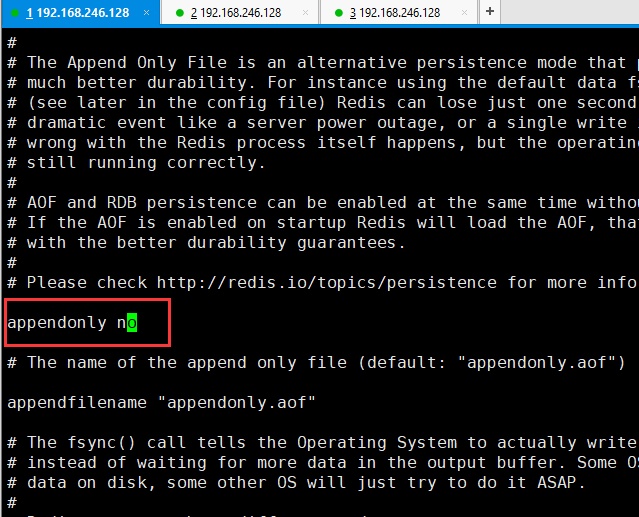
然后设置6380.conf
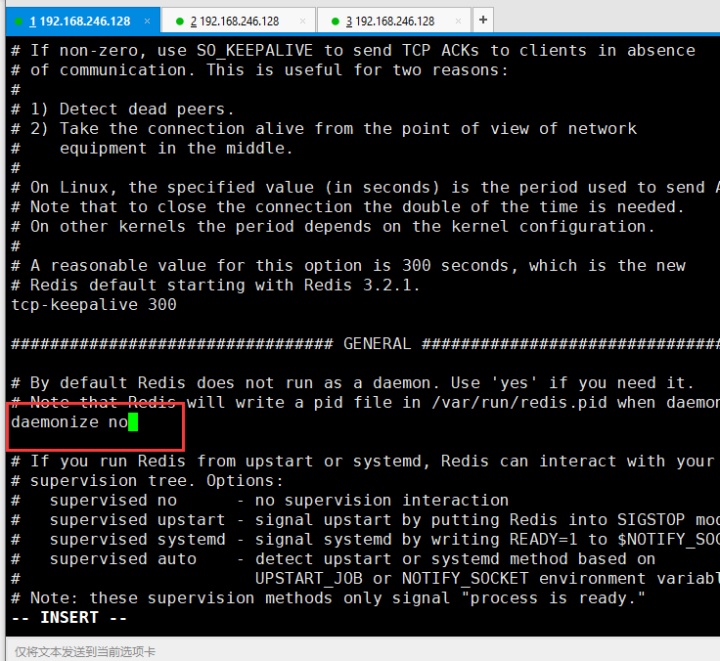
和6379一样 ,把aof关闭,日志注释,daemonize 设置 no,因为6379之前设置过daemonize no,上面配置6379的时候就没再截图
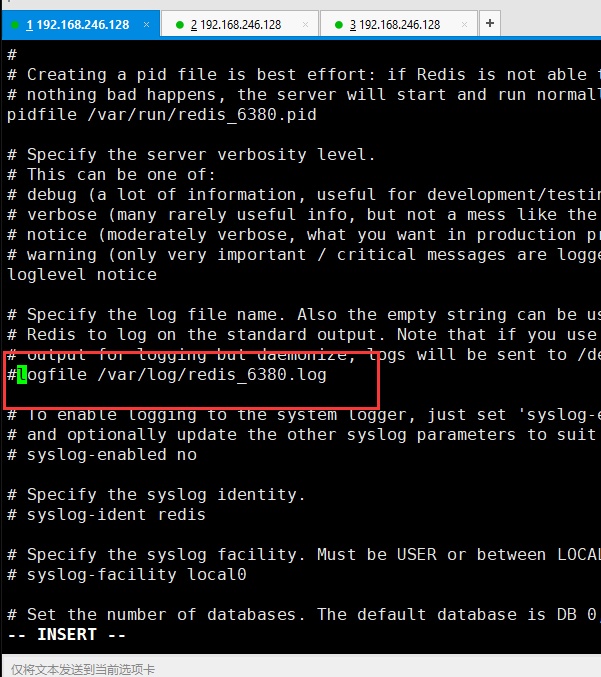
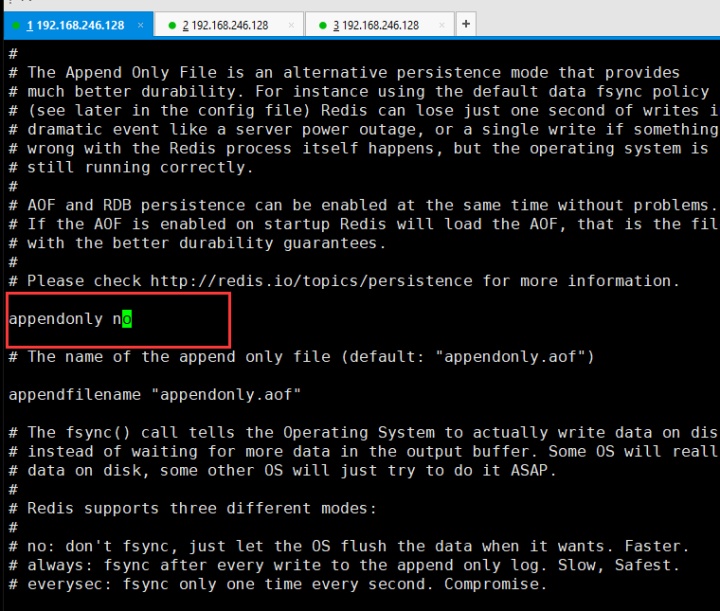
配置6381.conf。和6379,6380一样操作就不截图了。
在2号shell中,把6379,6380,6381之前持久化的数据删掉:
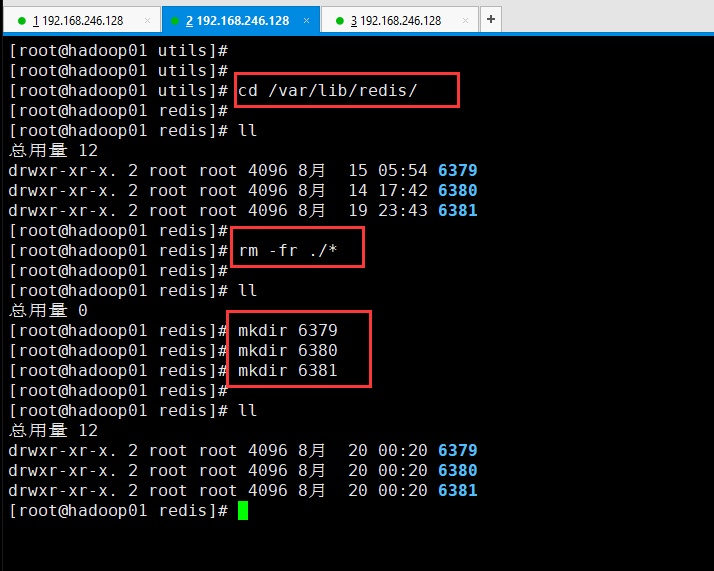
对上图的解释:继续创建6379,6380,6381的原因是:因为把6379,6380,6381里面的数据删的话,还要进6379文件夹然后删除,然后退出,然后进6380删除,退出,再进6381删除退出。还不如把6379,6380,6381文件夹删了,重新创建一个空的6379,6380,6381。
在1号shell中启动6379: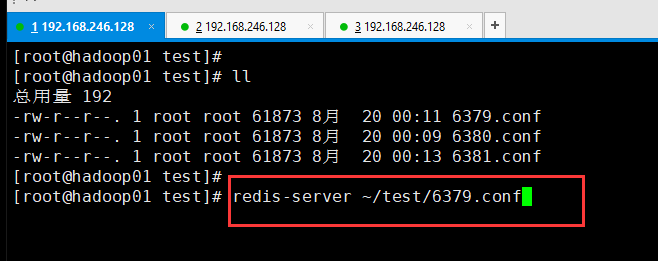
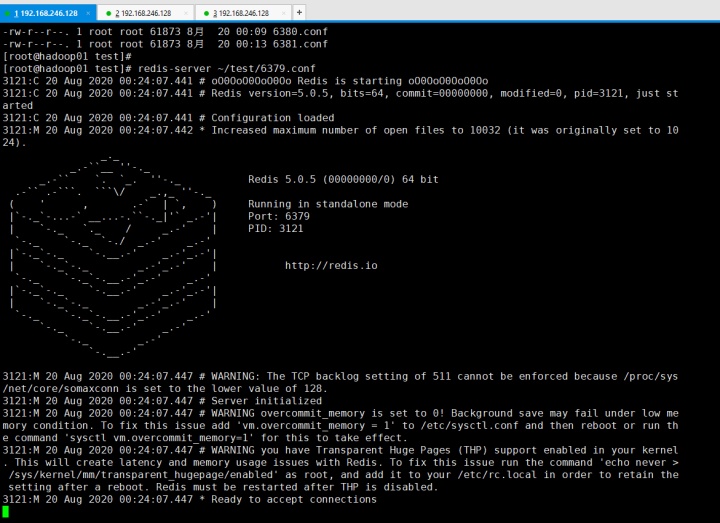
然后在3号shell中启动redis 6379客户端,并查看所有key。为空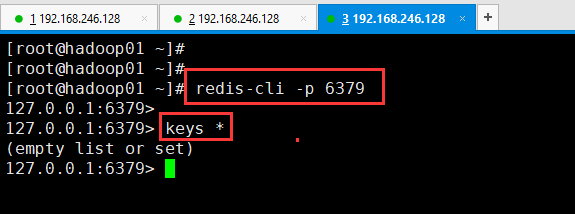
而这只是启动了一个6379,现在开始启动6380。那么就需要再开一个shell,4号shell。估计到这里有些乱了。那这样,按顺序我捋一下。
重新弄:重新弄之前先把cd /var/lib/redis/ 里 全部清空 然后重新 mkdir 6379 mkdir 6380
mkdir 6381
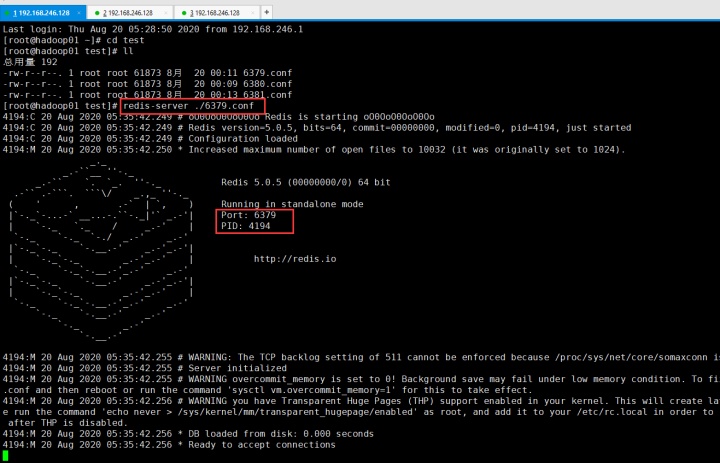
然后再启动redis:
6379
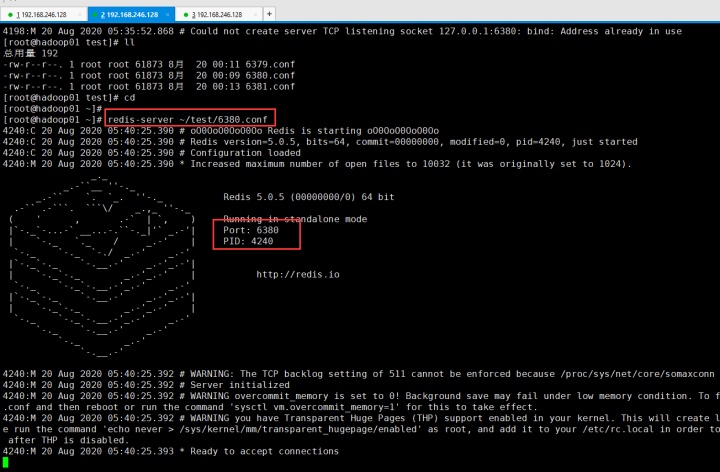
6380
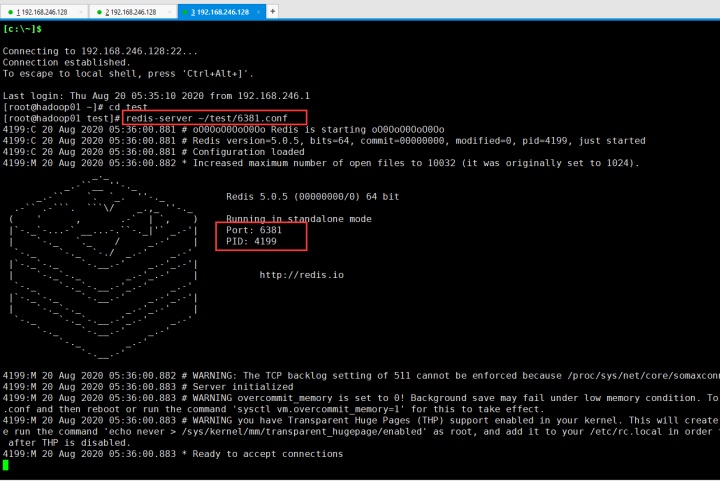
6381
下来开始启动3个redis-cli
6379
6380
6381
然后查看一下 6379 6380 6381 里面有什么东西没有:查看都是空的
现在把6379 作为主,6380和6381作为从。
所以在6380的客户端下:
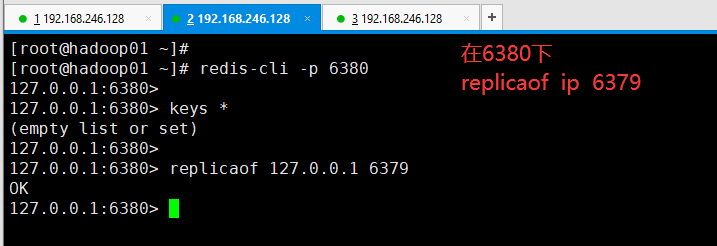
然后切回到6379的服务下可以看到:
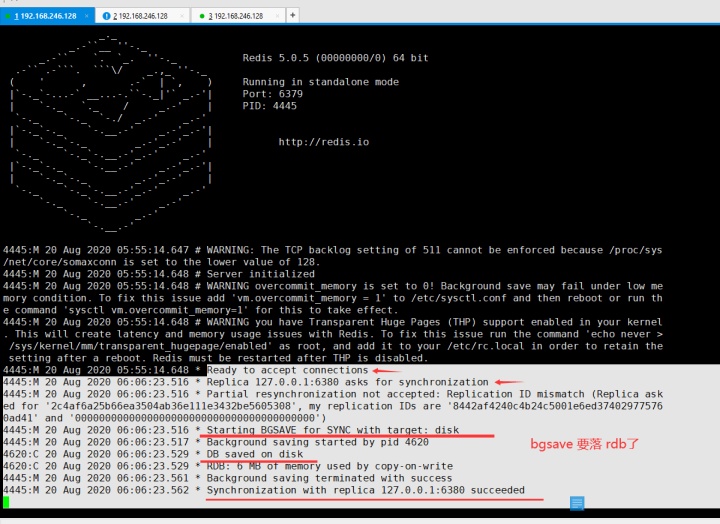
然后在6380的服务下可以看到:6380需要把自己的老的数据全部清空,然后加载6379的数据,只有这样才能和主保持数据同步。
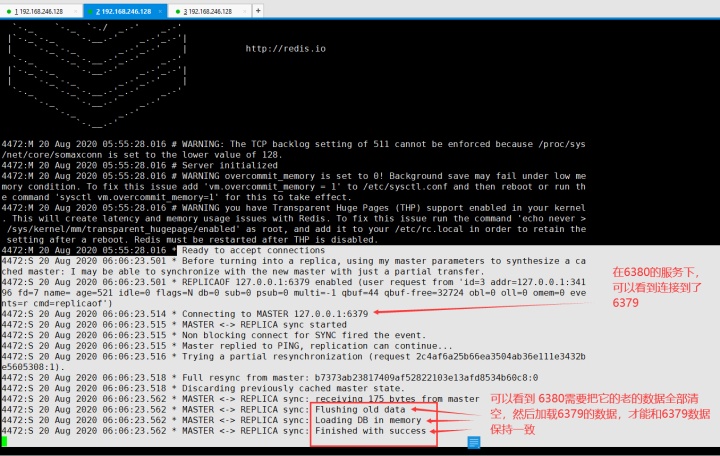
所以现在在6379 的客户端下,set一个键值对,
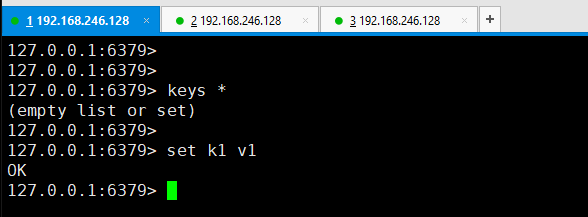
然后在6380客户端下就可以得到刚才在6379中set的值,并且既然6380是从,那么默认是禁止写入的。
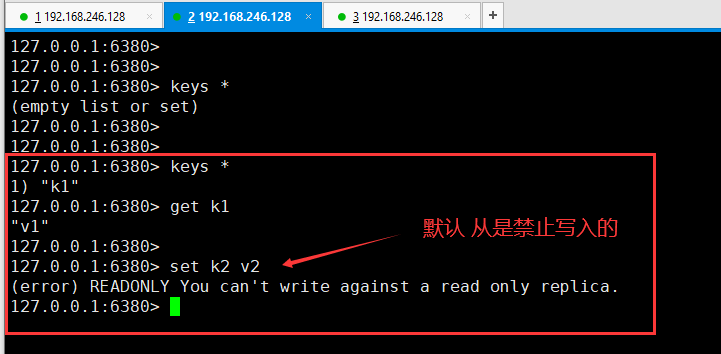
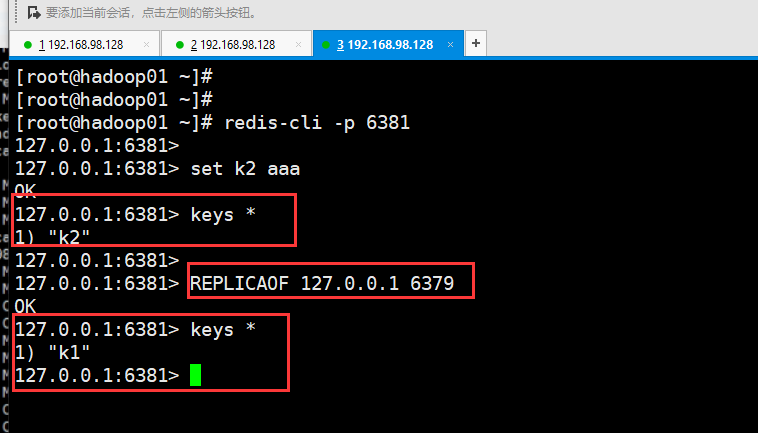
下来把6381和6379做一下主从追随。在做之前,先给6381客户端里set k2 aaa,这样的话6379是拿不到 k2的,因为还没有做主从。
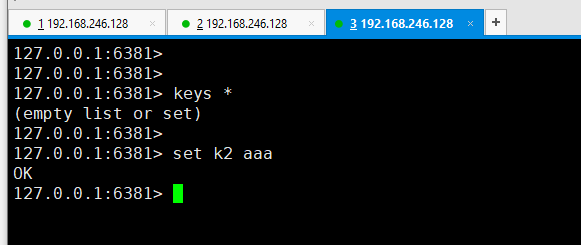
6379里拿不到k2
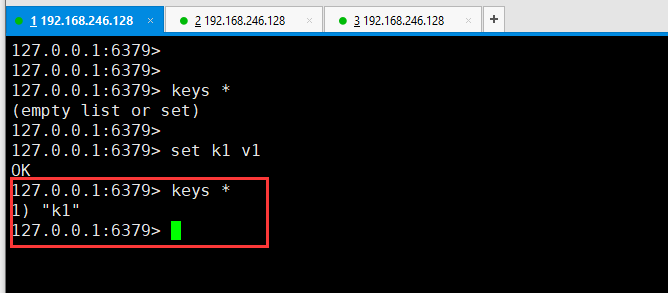
然后把6381作为6379的从,在6381客户端输入 replicaof 127.0.0.1 6379
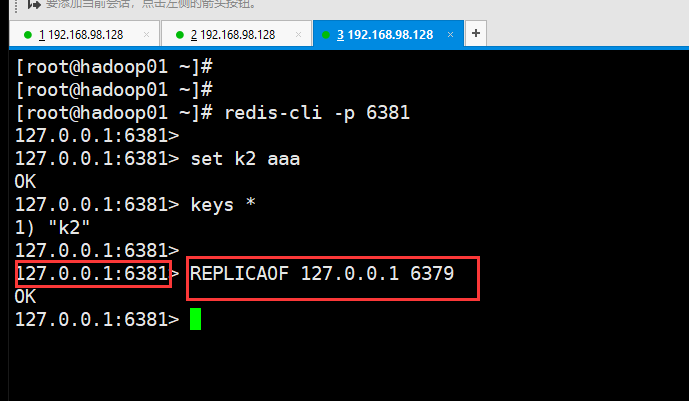
回到6379的服务端
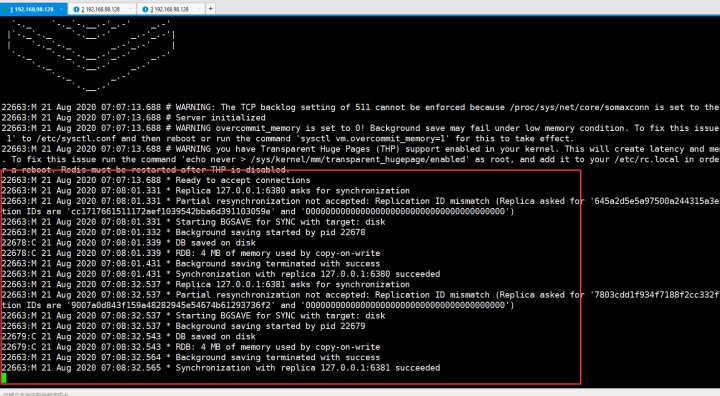
因为6381跟随的是6379,所以做主从之后,从里的数据是先flush old data的。所以现在6379是主,6380和6381是从,只有一个key就是k1,原来6381里的k2被flush了。
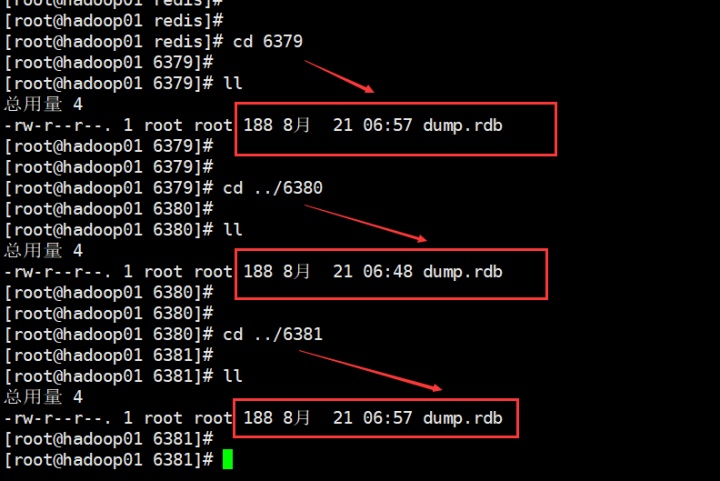
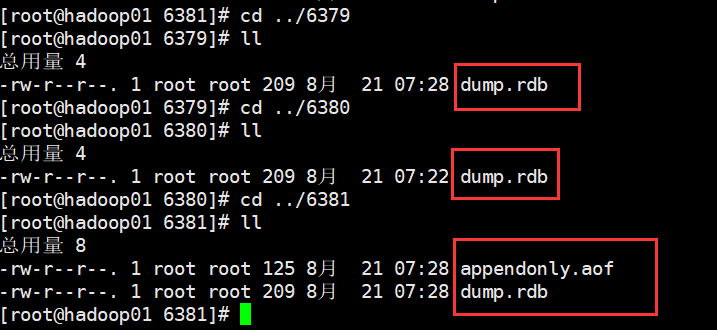
然后,可以去6379,6380,6381里看都会落一个dump.rdb文件。
从2.几还是3.几的版本之后,redis主和从都可能会挂。
先看从挂的情况,6381如果挂的话,6379主服务端会显示6381挂了lost
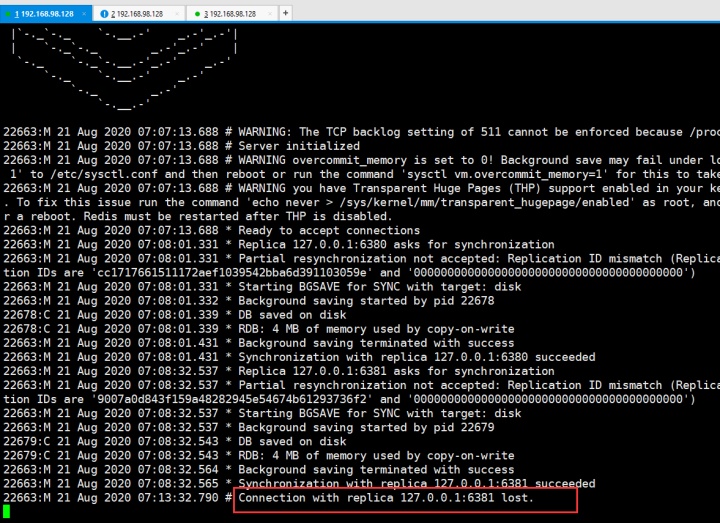
而6381过了一会运维人员修复好了,又启动的话,启动的时候数据怎么同步呢?
挂了之后在6379里多添加几条数据:
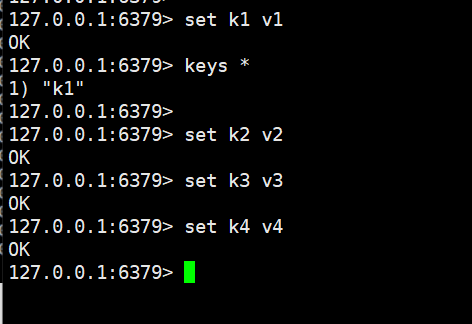
那么6381启动的时候数据是把这些数据全部拉过来呢,还是做增量同步呢?
用下图命令启动
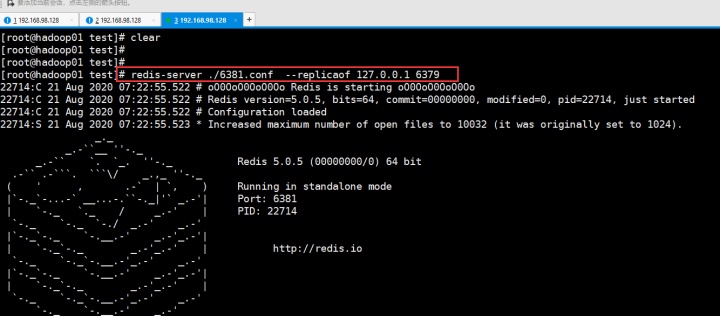
会可以看到没有rdb这个东西
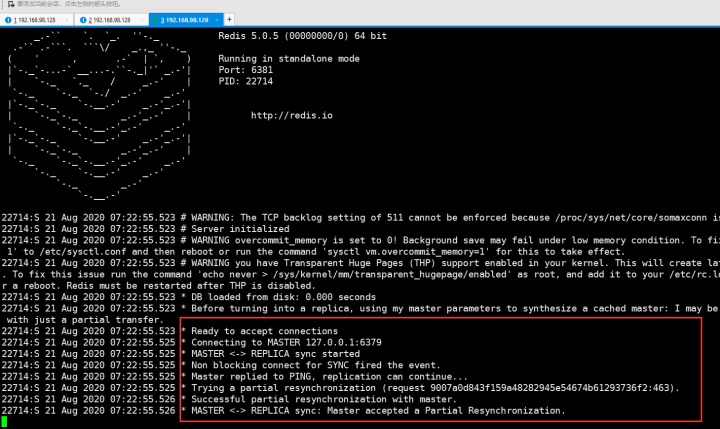
然后在6381中 看一下 key
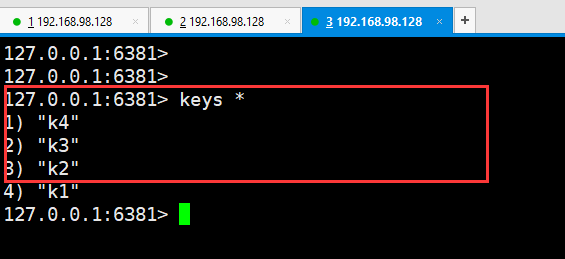
那么继续把6381停掉,然后以这种方式启动

会看到落rdb了:
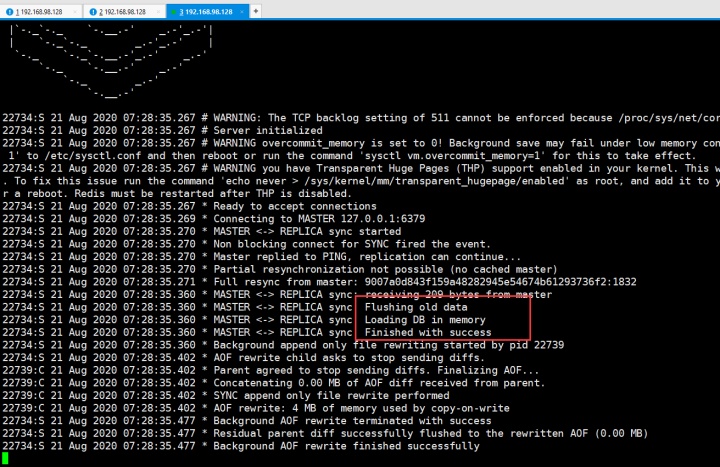
继续停掉6381,继续以上图相同方式启动,还是会再次落rdb。6381还落aof
那么当主挂了呢?从就可以切换为主,假如6379挂了,那么从6380和6381的服务端会这样显示
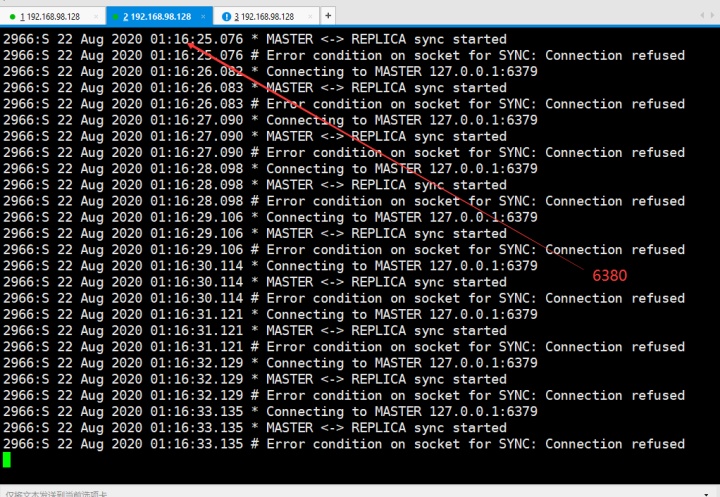
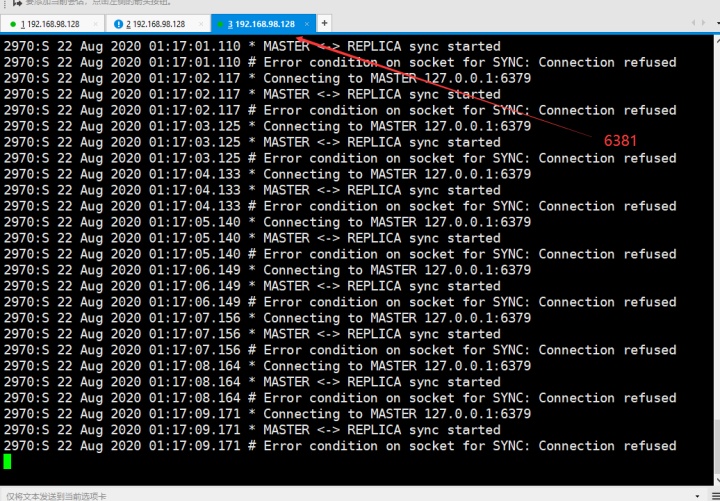
而现在要把从里的6380切成主,使用命令:一定要记住no one就是切成主,后面哨兵sentinel也有这个no one 的日志
replicaof no one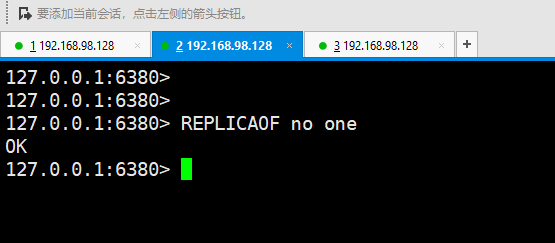
然后看6380的服务端:
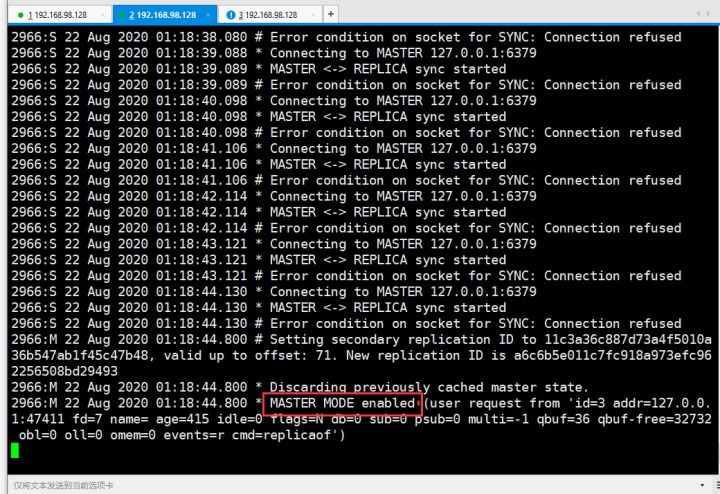
然后让6381追随6380:
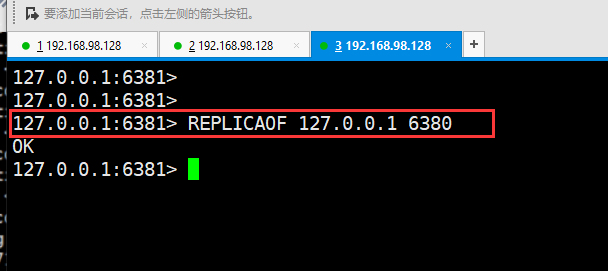
Redis支持主从同步和从从同步,从从同步是Redis后续版本增加的功能,以减轻主节点的同步负担。来说主从同步
增量同步:
Redis同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地的内存buffer中,然后异步将buffer中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一样的状态,一边向主节点反馈自己同步到了哪里了(offset)
因为内存的buffer是有限的,所以Redis主节点不能将所有的指令都记录在内存buffer中。Redis的复制内存buffer是一个定长的环形数组,如果数组内容满了。就会从头开始覆盖前面的内容。如果因为网络状态不好,从节点在短时间内无法和主节点进行同步,那么当网络状态恢复时,Redis的主节点中那些没有同步的指令在buffer中有可能已经被后续的指令覆盖掉了,从节点将无法直接通过指令流来进行同步,这个时候就需要用到更复杂的同步机制--快照同步。
快照同步:
快照同步是一个非常耗费资源的一个操作,首先需要在主节点上进行一次bgsave,将当前内存数据全部快照到磁盘文件中,然后再将快照文件的内容全部传送到从节点。从节点将快照文件接收完毕后,立即执行一次全量加载load,加载之前先要将当前内存的数据清空,也就是flush old data,加载完毕之后通知主节点继续进行增量同步。
在整个快照同步过程中,主节点的复制buffer还在不停地向前移动,如果快照同步的时间过长或者复制buffer太小,都会导致同步期间的增量指令在复制buffer中被覆盖,这样就会导致快照同步完成后无法进行增量复制,然后会再次发起快照同步,这样的话就极有可能陷入快照同步的死循环。所以务必配置一个合适的复制buffer大小参数,避免快照复制的死循环。
当从节点刚刚加入集群时,必须先进行一次快照同步,同步完成后再继续进行增量同步。
主节点在进行快照同步时,会进行很耗时的io操作,在非固态硬盘上存储时,快照同步会对系统的负载产生较大的影响。特别是当系统正在进行AOF的fsync操作时,如果发生快照同步,fsync将会被推迟执行,这就会严重影响主节点的服务效率。
所以从Redis 2.8.18版本开始,Redis支持无盘复制。所谓无盘复制是指主服务器直接通过套接字将快照内容发送到从节点,生成快照是一个遍历的过程,主节点会一边遍历内容,一边将序列化的内容发送到从节点,从节点还是跟之前一样,先将接收到的内容存储到磁盘文件中,再进行一次性加载。
主从复制是Redis分布式的基础,Redis的高可用离开了主从复制将无从进行。
上文是手动主从复制,上文中所说的监控就是下来要说的 Redis Sentinel(哨兵)
哨兵嘛,放哨用的,就是监控。
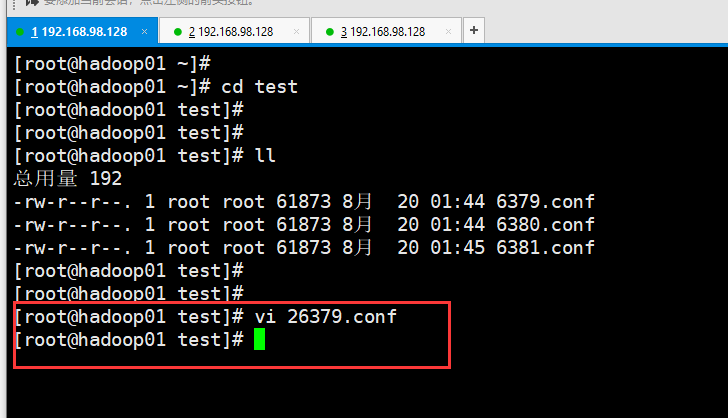
先来把所有redis服务全部关闭然后客户端也全部关闭,然后写一个配置文件:
在test目录下:
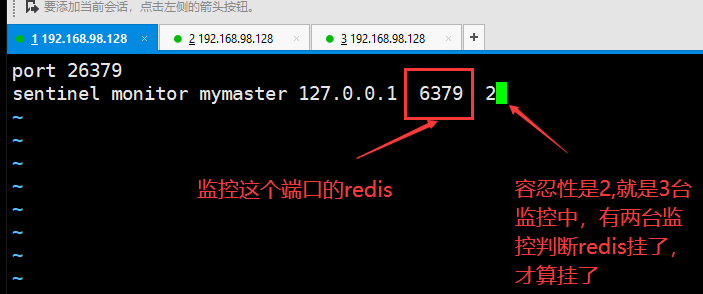
一套哨兵可以监控多套主从复制集群。
然后再写两个哨兵配置文件:
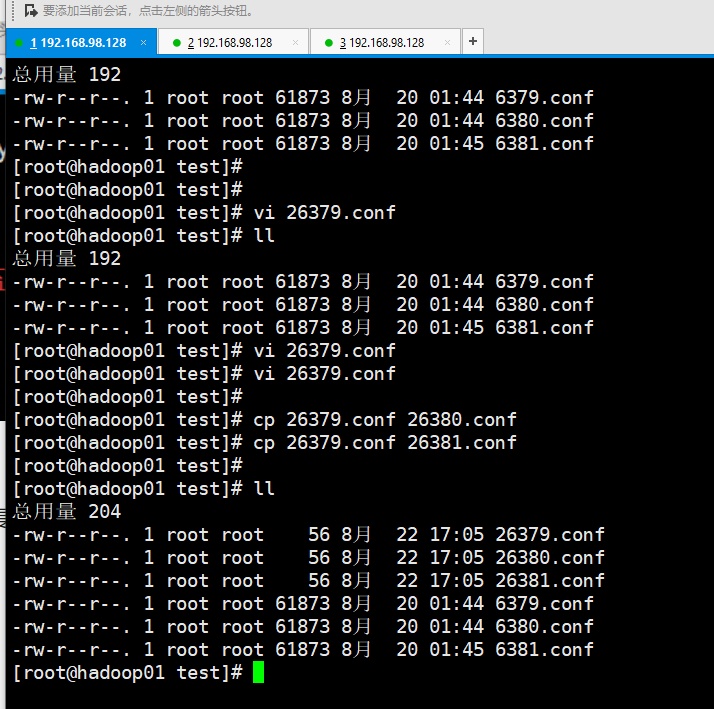
然后修改端口号,因为是拷贝过来的;
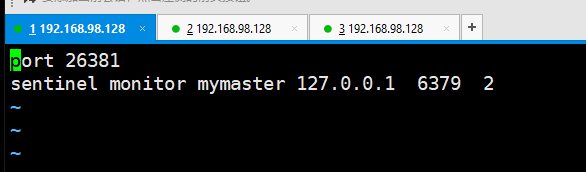
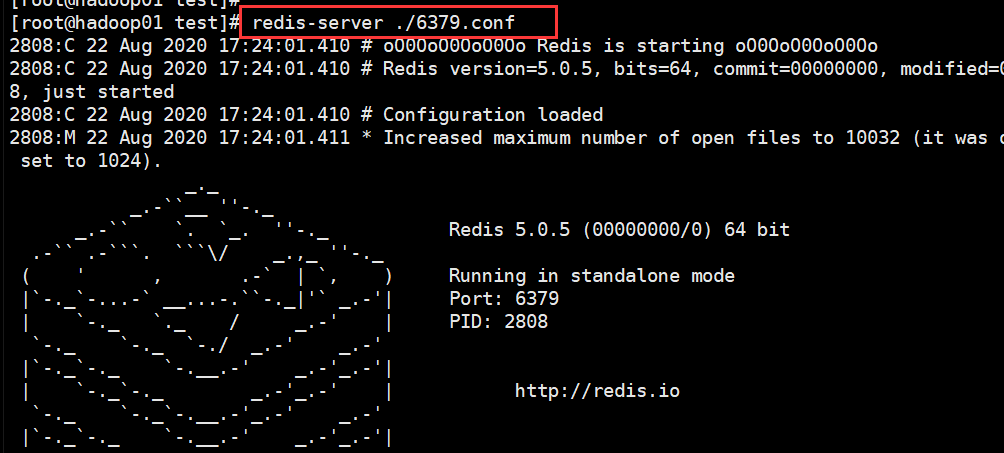
接下来启动redis服务:
然后启动6380和6381去追随6379
redis-server ./6380.conf --replicaof 127.0.0.1 6379
redis-server ./6381.conf --replicaof 127.0.0.1 6379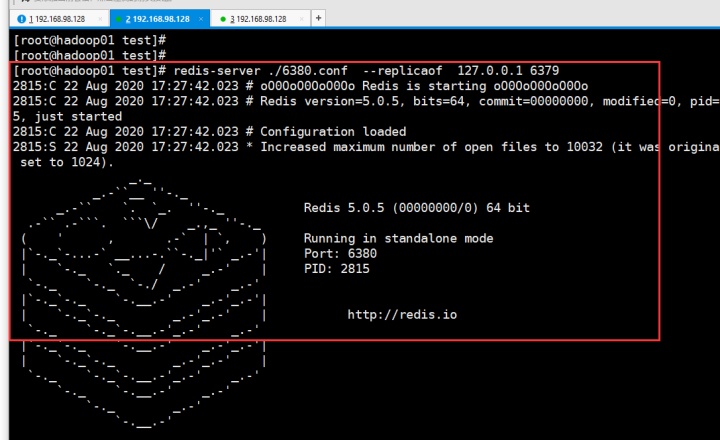
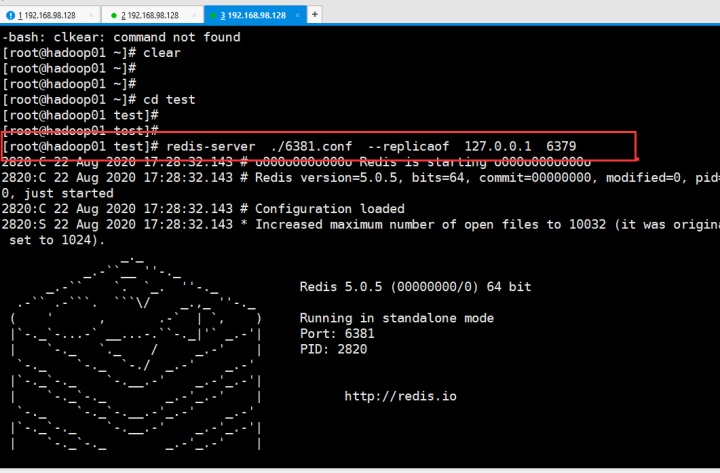
下来启动 Redis Sentinel,监控肯定是监控主节点:
在 test目录下,输入 redis-server ./26379.conf --sentinel
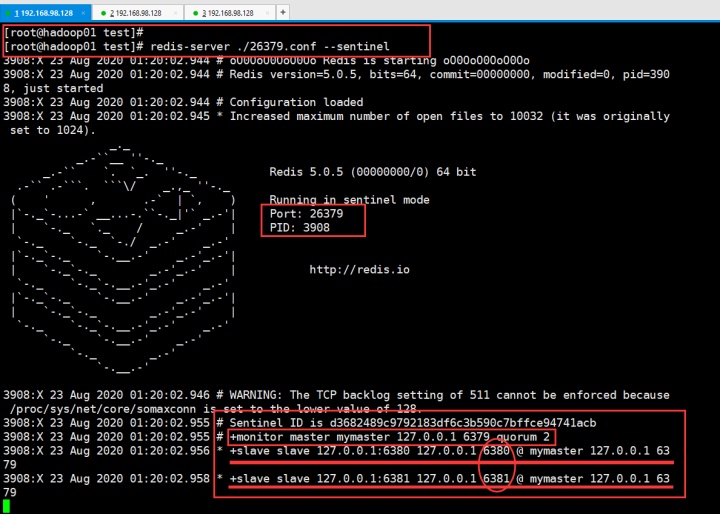
继续再另一个shell的test目录下输入:redis-server ./26380.conf --sentinel
继续再另一个shell的test目录下输入:redis-server ./26381.conf --sentinel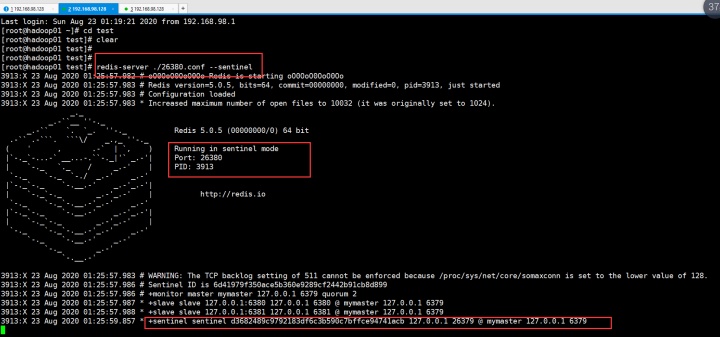
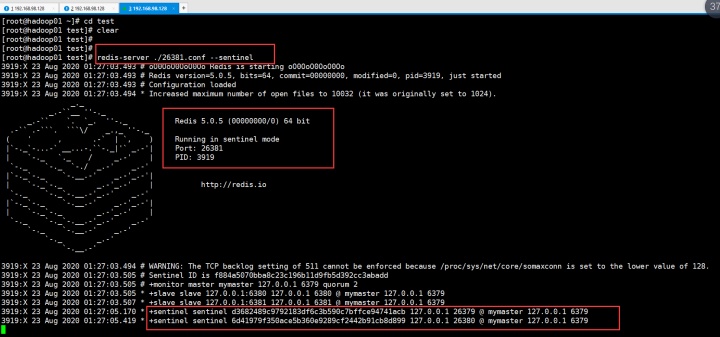
然后返回来看26379的sentinel:
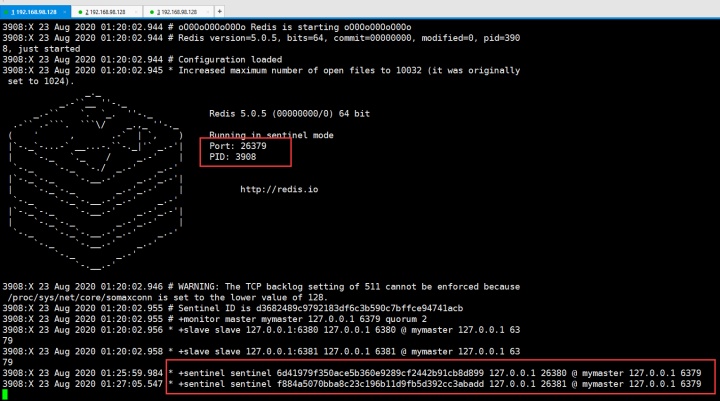
26380也是一样就不截图了,也感受到了26379和26381。他们三个互相都能感受到彼此。















 1467
1467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









