






 前言大多数JAVA开发人员都在使用Maps,尤其是HashMaps。HashMap是一种简单并且有效的存取数据的方式。但是有多少人知道HashMap内部是如何工作的么?前段时间,为了深入理解这个基础的数据结构,我阅读了 java.util.HashMap大部分源码(先是Java 7中,然后是Java 8)。在这篇文章中,我将解释java.util.HashMap的实现,并介绍JAVA 8...
前言大多数JAVA开发人员都在使用Maps,尤其是HashMaps。HashMap是一种简单并且有效的存取数据的方式。但是有多少人知道HashMap内部是如何工作的么?前段时间,为了深入理解这个基础的数据结构,我阅读了 java.util.HashMap大部分源码(先是Java 7中,然后是Java 8)。在这篇文章中,我将解释java.util.HashMap的实现,并介绍JAVA 8...
前言
大多数JAVA开发人员都在使用Maps,尤其是HashMaps。HashMap是一种简单并且有效的存取数据的方式。但是有多少人知道HashMap内部是如何工作的么?前段时间,为了深入理解这个基础的数据结构,我阅读了 java.util.HashMap大部分源码(先是Java 7中,然后是Java 8)。在这篇文章中,我将解释java.util.HashMap的实现,并介绍JAVA 8实现的新功能,并讨论使用HashMaps时的性能,内存和已知的一些问题。
内部存储器
JAVA HashMap类实现接口Map 。该接口的主要方法是:
- V put(K键,V值)
- V get(对象键)
- V remove(对象键)
- 布尔containsKey(Object key)
HashMaps使用一个内部类来存储数据:Entry 。此项是一个简单的键值对,其中包含两个额外的数据:
- 对另一个Entry的引用,以便HashMap可以存储单个链接列表之类的条目
- 表示键的哈希值的哈希值。存储该哈希值是为了避免每次HashMap需要哈希时都进行哈希计算。
这是Java 7中Entry实现的一部分:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry next;int hash;
…
}HashMap将数据存储到多个单链接的条目列表(也称为buckets或bins)中。所有列表都注册在Entry数组(Entry []数组)中,并且此内部数组的默认容量为16。
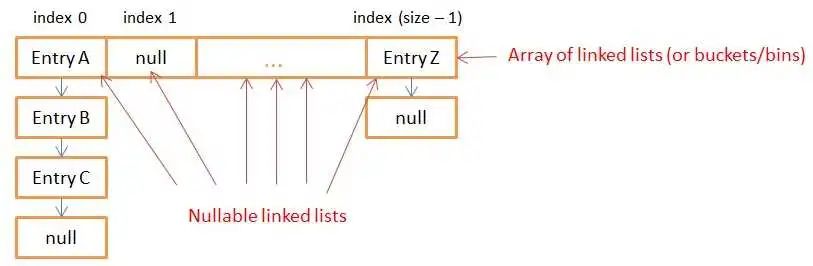
下图显示了带有可空条目数组的HashMap实例的内部存储。每个条目可以链接到另一个条目以形成链接列表。
具有相同哈希值的所有键都放在相同的链表(存储桶)中。具有不同哈希值的键可以最终出现在同一存储桶中。
当用户调用put(K键,V值)或get(Object键)时,该函数将计算Entry所在的存储区的索引。然后,该函数遍历列表以查找具有相同键的Entry(使用键的equals()函数)。
对于get(),该函数返回与该条目关联的值(如果该条目存在)。
对于put(K键,V值),如果该条目存在,则该函数将其替换为新值,否则它将在单链接列表的开头创建一个新条目(根据键和参数中的值)。
桶的索引(链接列表)由地图分3步生成:
- 它首先获取密钥的哈希码。
- 它会重新整理哈希码,以防止将所有数据放入内部数组的同一索引(存储桶)的键中的哈希功能不正确
- 它获取经过重整的哈希哈希码,并使用数组的长度(减1)对其进行位掩码。此操作可确保索引不能大于数组的大小。您可以将其视为在计算上经过优化的模函数。
这是处理索引的JAVA 7和8源代码:
// the "rehash" function in JAVA 7 that takes the hashcode of the key
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// the "rehash" function in JAVA 8 that directly takes the key
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// the function that returns the index from the rehashed hash
static int indexFor(int h, int length) {
return h & (length-1);
}
为了有效地工作,内部数组的大小需要为2的幂,让我们看看为什么。
想象一下,数组大小为17,掩码值将为16(大小为-1)。16的二进制表示形式是0…010000,因此对于任何哈希值H,使用按位公式“ H AND 16”生成的索引将为16或0。这意味着大小为17的数组将仅用于2个存储桶:索引0的一个和索引16的一个,效率不高…
但是,如果您现在采用的是2的幂(如16),则按位索引公式为“ H AND 15”。15的二进制表示形式是0…001111,因此
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8611
8611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









