






 这篇博客讲述了作者通过分析一个运行超时的复杂SQL查询,发现其性能瓶颈在于`WITH CUBE`操作,并且由于外部工具限制无法直接修改。通过调整SQL Server的`max degree of parallelism`参数,将查询时间从300秒降低到10秒,实现了显著的性能提升。
这篇博客讲述了作者通过分析一个运行超时的复杂SQL查询,发现其性能瓶颈在于`WITH CUBE`操作,并且由于外部工具限制无法直接修改。通过调整SQL Server的`max degree of parallelism`参数,将查询时间从300秒降低到10秒,实现了显著的性能提升。
今天客户反馈有一个报表运行超时。
于是登录到系统上,查到运行缓慢报表的对应sql,代码如下:
SELECT f_temp_biz_date AS f_temp_biz_date ,
o_id2 AS o_id2 ,
o_id3 AS o_id3 ,
o_id4 AS o_id4 ,
storeChannel_id2 AS storeChannel_id2 ,
storeChannel_id3 AS storeChannel_id3 ,
g_A_item_id AS g_A_item_id ,
A_item_id AS A_item_id ,
MAX(CASE WHEN f_unit = '当月销量(L)'
AND p_brand_id = '11083' THEN M001
END) ,
MAX(CASE WHEN f_unit = '当月销量(L)'
AND p_brand_id = '11207' THEN M001
END) ,
...此处省略100行
MAX(CASE WHEN f_unit = '当月销量(Box)'
AND p_brand_id = '11055' THEN M001
END) ,
MAX(CASE WHEN f_unit = '当月销量(Box)'
AND p_brand_id = '11056' THEN M001
END)
FROM ( SELECT f.temp_biz_date AS f_temp_biz_date ,
o.id2 AS o_id2 ,
o.id3 AS o_id3 ,
o.id4 AS o_id4 ,
storeChannel.id2 AS storeChannel_id2 ,
storeChannel.id3 AS storeChannel_id3 ,
GROUPING(A.item_id) AS g_A_item_id ,
A.item_id AS A_item_id ,
GROUPING(f.unit) AS g_f_unit ,
f.unit AS f_unit ,
GROUPING(p.brand_id) AS g_p_brand_id ,
p.brand_id AS p_brand_id ,
COUNT(CASE WHEN flag = 'store' THEN f.store_id
END) AS M000 ,
SUM(CASE WHEN flag = 'HL_BOX' THEN HL_BOX
ELSE 0
END) AS M001
FROM ( SELECT r.org_id ,
r.store_id ,
R.LEVEL_ID ,
r.channel_id ,
r.biz_date + '-01' AS biz_date ,
r.biz_date AS temp_biz_date ,
ISNULL(r.prod_id, t.prod_id) AS PROD_ID ,
HL_BOX ,
UNIT ,
flag
FROM TB_S_001 r
CROSS APPLY ( SELECT TOP 1
prod_id
FROM TB_PRODUCT WITH ( NOLOCK )
WHERE state = 1
) t
WHERE r.biz_date IN ( '2016-08' )
) f
INNER JOIN STD_TIME t ON f.biz_date = t.the_date
INNER JOIN STD_ORG o ON f.org_id = o.org_id
INNER JOIN STD_STORE s ON f.store_id = s.store_id
LEFT JOIN STD_PRODUCT p ON f.prod_id = p.prod_id
INNER JOIN STD_ITEM storeChannel ON f.channel_id = storeChannel.item_id
INNER JOIN STD_ITEM A ON f.level_id = A.item_id
WHERE ( o.id2 = '516' )
AND ( o.id2 = '516' )
AND ( f.biz_date BETWEEN '2016-08-01' AND '2016-08-31' )
AND ( s.id2 = '516' )
GROUP BY f.temp_biz_date ,
o.id2 ,
o.id3 ,
o.id4 ,
storeChannel.id2 ,
storeChannel.id3 ,
A.item_id ,
f.unit ,
p.brand_id
WITH CUBE
HAVING NOT ( GROUPING(f.temp_biz_date) = 1
OR GROUPING(f.temp_biz_date) = 0
AND GROUPING(o.id2) = 1
OR GROUPING(o.id2) = 0
AND GROUPING(o.id3) = 1
OR GROUPING(o.id3) = 0
AND GROUPING(o.id4) = 1
OR GROUPING(o.id4) = 0
AND GROUPING(storeChannel.id2) = 1
OR GROUPING(storeChannel.id2) = 0
AND GROUPING(storeChannel.id3) = 1
OR GROUPING(A.item_id) = 0
AND GROUPING(storeChannel.id3) = 1
OR GROUPING(storeChannel.id3) = 0
AND GROUPING(storeChannel.id2) = 1
OR GROUPING(storeChannel.id2) = 0
AND GROUPING(o.id4) = 1
OR GROUPING(o.id4) = 0
AND GROUPING(o.id3) = 1
OR GROUPING(o.id3) = 0
AND GROUPING(o.id2) = 1
OR GROUPING(o.id2) = 0
AND GROUPING(f.temp_biz_date) = 1
)
) cr
GROUP BY f_temp_biz_date ,
o_id2 ,
o_id3 ,
o_id4 ,
storeChannel_id2 ,
storeChannel_id3 ,
g_A_item_id ,
A_item_id
ORDER BY f_temp_biz_date ,
o_id2 ,
o_id3 ,
o_id4 ,
storeChannel_id2 ,
storeChannel_id3 ,
g_A_item_id
由于这个语句的外层是由工具生成的,修改不了,所以只能修改这个语句中最内层的的这个sql,能做的优化非常有限,sql语句上没有什么可以调整的。
SELECT r.org_id ,
r.store_id ,
R.LEVEL_ID ,
r.channel_id ,
r.biz_date + '-01' AS biz_date ,
r.biz_date AS temp_biz_date ,
ISNULL(r.prod_id, t.prod_id) AS PROD_ID ,
HL_BOX ,
UNIT ,
flag
FROM TB_RPT_001 r
CROSS APPLY ( SELECT TOP 1
prod_id
FROM TB_PRODUCT WITH ( NOLOCK )
WHERE state = 1
) t
WHERE r.biz_date IN ( '2016-08' )
运行时间:最开始的速度是170s。
表信息:表中有大概800w条数据,这个查询的8月份,大概有80w的数据。
结果集:返回数据量在4w行左右。
优化方法:创建了索引,但是速度反而更慢了,运行了300s没有出结果。
因为这个表会经常删除,在插入,所以把整个表重建了,但是结果还是300s没有出结果。
经过分析发现这个语句之所以这么慢,主要的原因在于语句中的 with cube 造成的,执行计划非常复杂,一眼望不到头。
实际上在sql server 2008之后可以采用新的cube语句,只对需要的列进行cube计算,但关键是这个外层代码改不了,是工具生成的,太坑了。。。

下面的图就是这个sql的执行计划,由于这个执行计划太复杂,太大了,所以这个截图只是原始执行计划的5分之1
 :
:
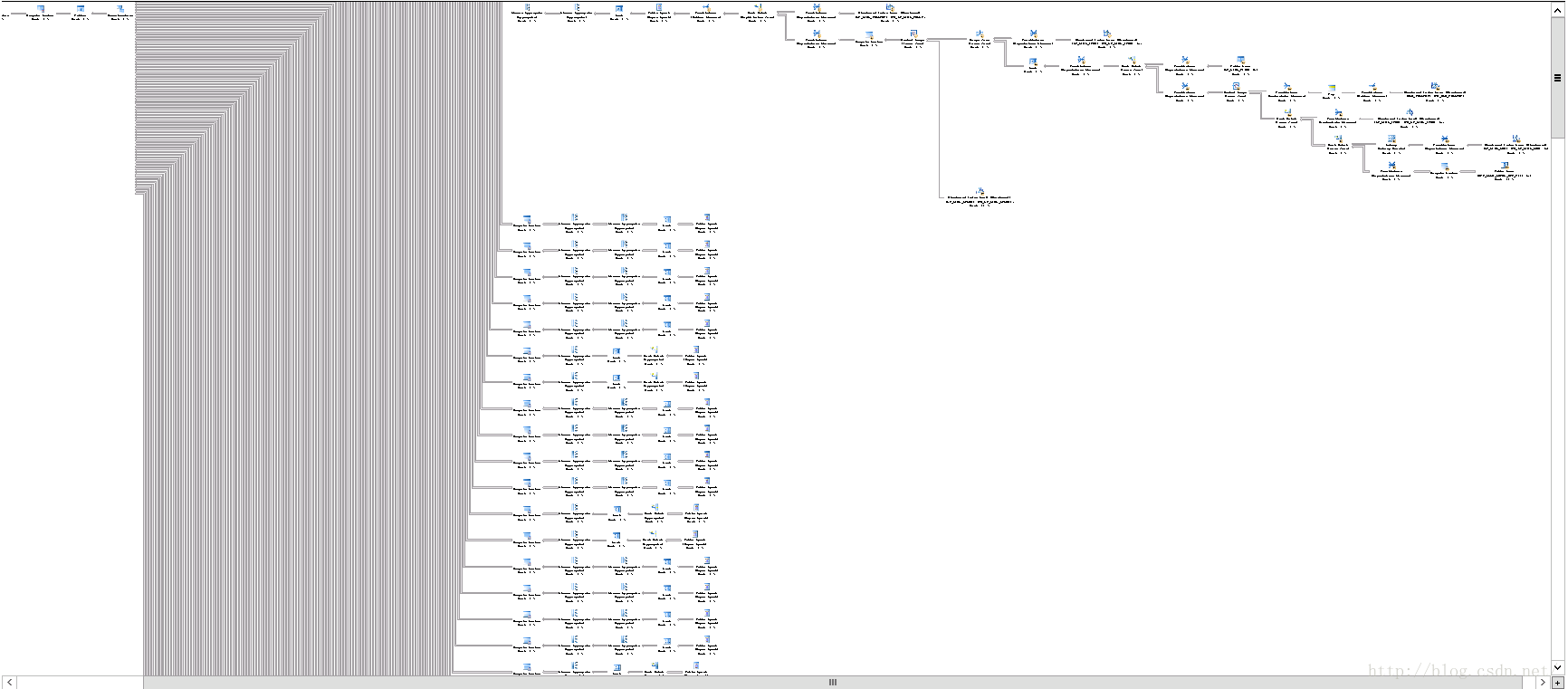
想想还可以试一下,就是修改sql server的服务器参数max degree of parallelism ,就是语句执行的并行度,服务器CPU配置是64个线程,所以把参数值调整为20,也就是可以有20个线程同时运行这个sql。
调整之后,sql运行速度降为10秒
 ,太棒了。
,太棒了。















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









