





前两篇介绍了BeautifulSoup给大家认识,如果还是觉得不合心意,那么可以考虑考虑XPath。XPath与BeautifulSoup的思想很相似,都是选择节点再从节点中提取需要的数据,但却是另外一套语法规则。
一、XPath的常用规则
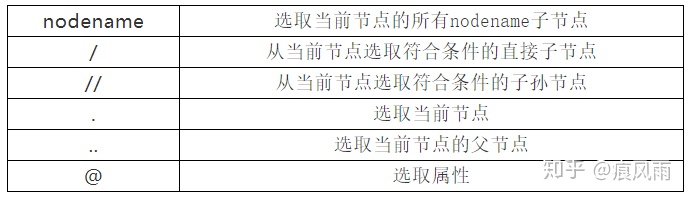
下面我们通过例子来具体说明这些规则的使用。
二、XPath的使用
1、etree对象的初始化
使用XPath需要导入lxml库中的etree模块,继而需要通过其中的HTML()类初始化创建etree对象,代码如下:
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a href="qe/intro.html">Lec 0</a></li>
<li><a href="qe/about_py.ipynb">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="qe/matplotlib.ipynb">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
print(type(html))
result = etree.tostring(html)
print(result)
print(result.decode('utf-8'))上面的代码中,我们首先导入了lxml中的etree模块,然后定义了一段HTML文档,再调用etree模块中的HTML()类,将text作为参数传入,至此我们就创建了一个Xpath解析对象html,我们将其类型打印了出来

后面我们简称为Element对象。这里类比BeautifulSoup,etree模块也可以自动修正补全HTML文档,如定义的text中的<ul>标签是没有闭合的,etree在进行初始化的时候就会将其闭合,我们可以调用etree模块中的tostring()方法将解析后的HTML文档输出。我们先看第一个输出结果

可以看到输出类型为bytes,我们可以利用decode()方法将其转化为str类型输出

可以看到,输出结果不仅补全了<ul>标签,还添加了<html>、<body>节点。
2、选取所有符合要求的节点
我们一般会用//开头来选择符合要求的所有节点,比如对于上面定义的text,我们要选取所有<li>节点
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a href="qe/intro.html">Lec 0</a></li>
<li><a href="qe/about_py.ipynb">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="qe/matplotlib.ipynb">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
result = html.xpath('//li')
print(result)输出结果

可以看到选出了所有的<li>节点并以列表形式返回,其中的每一个元素都是Element对象,类比BeautifulSoup,这意味着可以继续进一步选择<li>标签中的节点。
3、选取子节点和子孙节点
我们通过/可以选取当前节点的直接子节点,通过//可以选取当前节点的子孙节点。先看代码
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a href="qe/intro.html">Lec 0</a></li>
<li><a href="qe/about_py.ipynb">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="qe/matplotlib.ipynb">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
li_a = html.xpath('//li/a')
ul_a = html.xpath('//ul//a')
ul_li = html.xpath('//ul/a')
print(li_a)
print(ul_a)
print(ul_li)输出结果

这里我们首先看li_a的表达式://li选取了HTML文档中的所有<li>节点,/表示选取当前节点的直接子节点,当前节点为//li选中的<li>节点,所以最终组合效果就是选择了所有<a>节点。再看ul_a的表达式://表示选取当前节点的所以子孙节点,当前节点为//ul选中的<ul>节点,追加//a则表示继续选择<ul>的子孙节点中的<a>节点。ul-li的表达式也是想选择<a>节点,但是最终返回结果为一个空列表,为什么呢?因为/只能选择当前节点的直接子节点,而<a>节点不是<ul>的直接子节点,所以无法匹配任何结果。
4、选取父节点
在XPath中,选取当前节点的父节点通过(..)实现。
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a href="qe/intro.html">Lec 0</a></li>
<li><a href="qe/about_py.ipynb">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="qe/matplotlib.ipynb">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
li_a = html.xpath('//li/a')
a = li_a[0]
li = a.xpath('..')
print(li)输出结果
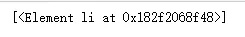
代码中我们先选择了所有的<a>节点,然后取出列表中的第一个<a>节点赋给a,由于a是一个Element对象,所以可以继续调用Element对象的所有方法和属性。语句
li = a.xpath('..')的含义是当前节点为<a>节点,要选取<a>节点的父节点,所以我们选出了<li>节点。
5、属性匹配
- 基本用法
在选择节点时,我们可以使用@来选择具有一定属性的节点,进而使节点选择更加精准。
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a>Lec 0</a></li>
<li><a href="YQ">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="YQ">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
li_a = html.xpath('//li/a[@href="YQ"]')
print(li_a)输出结果

在语句
li_a = html.xpath('//li/a[@href="YQ"]')中,我们用@使选择更加精准,它的含义是选择html中的所有<li>节点下的所有属性href的值为YQ的<a>节点。当有其他属性是,也可以用其他属性作为筛选条件。
- 属性多值匹配
使用XPath解析网页常常遇到一个属性具有多个属性值的情况,这是用上面的基本方式将无法正确的获取节点,这种情况我们可以使用contains()函数处理。
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a>Lec 0</a></li>
<li><a href="YQ YQ-first">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="YQ YQ-second">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
li_a = html.xpath('//li/a[@href="YQ"]')
li_a_1 = html.xpath('//li/a[contains(@href,"YQ")]')
print(li_a)
print(li_a_1)输出结果
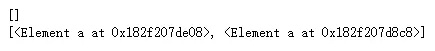
可以看到基本的属性匹配无法获取到href属性的值为"YQ"的<a>节点了,而使用了contains()函数意味着只要href属性的值包含"YQ"则被选中。
- 多属性匹配
除了单属性多值的情况外,还有一种常见情况就是一个标签中包含多个属性,如果使用多属性来匹配的话无疑会使XPath定位更精准。
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a>Lec 0</a></li>
<li><a href="YQ YQ-first">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="YQ YQ-second" class="Python">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
li_a_1 = html.xpath('//li/a[@class="Python" and contains(@href,"YQ")]')
print(li_a_1)输出结果
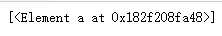
可以看到只有最后一个<li>标签的<a>被选中,所以当进行多属性匹配时,只需要将各个属性用and连接起来即可。
6、属性获取
使用@不仅可以加强筛选条件使节点选取更精准,还可以用于提取属性中包含的信息。
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a>Lec 0</a></li>
<li><a href="YQ">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="YQ">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
hrefs = html.xpath('//li/a/@href')
print(hrefs)输出结果

要获取当前节点的某一个属性的值,只需要使用(@属性名)就可以了。
7、文本获取
在XPath中,我们使用text()方法获取节点中的文本信息,我们以获取<a>节点中的文本信息为例
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a>Lec 0</a></li>
<li><a href="YQ">Lec 1.1</a></li>
<li><a href="qe/getting_started.ipynb">Lec 1.2</a></li>
<li><a href="qe/python_by_example.ipynb">Lec 1.3</a> | <a href="qe/Sol_python_by_example.ipynb">Sol 1.3</a></li>
<li><a href="qe/python_essentials.ipynb">Lec 1.4</a> | <a href="qe/Sol_python_essentials.ipynb">Sol 1.4</a></li>
<li><a href="qe/oop_intro.ipynb">Lec 1.5</a></li>
<li><a href="qe/numpy.ipynb">Lec 2.1</a> | <a href="qe/Sol_numpy.ipynb">Sol 2.1</a></li>
<li><a href="YQ">Lec 2.2</a> | <a href="qe/Sol_matplotlib.ipynb">Sol 2.1</a></li>
</div>'''
html = etree.HTML(text)
li = html.xpath('//li/text()')
li_a_1 = html.xpath('//li/a/text()')
li_a_2 = html.xpath('//li//text()')
print(li)
print(li_a_1)
print(li_a_2)输出结果

我们可以看到第一个输出结果为四个'|',是属于<li>标签的直接文本,但是属于<a>标签的文本并没被选中,所以这里注意使用/text()只能获取属于当前节点的文本。第二个输出结果则给出了属于<a>标签直接包含的文本,第三个输出使用了//text(),能够获取当前节点和当前节点的子孙节点包含的所有文本信息。
8、按序选择
到现在为止,我们介绍的选择节点的方式是只有节点满足给定的XPath条件就全部都选出来,但有时我们只需要某一个节点,这时怎么办呢?
from lxml import etree
text = '''<div>
<h5>Slides & Solutions</h5>
<ul>
<li><a>第一个</a></li>
<li><a href="YQ YQ-first">第二个</a></li>
<li><a href="qe/getting_started.ipynb">第三个</a></li>
<li><a href="qe/python_by_example.ipynb">第四个</a></li>
<li><a href="qe/python_essentials.ipynb">第五个</a></li>
<li><a href="qe/oop_intro.ipynb">第六个</a></li>
<li><a href="qe/numpy.ipynb">第七个</a></li>
<li><a href="YQ YQ-second" class="Python">第八个</a></li>
</div>'''
html = etree.HTML(text)
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
result = html.xpath('//li[position()<4]/a/text()')
print(result)
result = html.xpath('//li[last()-2]/a/text()')
print(result)输出结果

当我们只需要某一个<li>标签时,可以在选择的节点后使用[]并传入需要的<li>的序号,注意这里的序号从1开始计数。第一个我们传入了序号1,代表选择第一个<li>,第二个我们传入last()代表选择最后一个<li>,第三个我们传入position()<4代表选择位置序号小于4,即第1、2、3各<li>标签,第四个代表选择倒数第三个<li>标签,因为last()是最后一个,减2自然为倒数第三个。
三、总结
本篇讲解了XPath进行HTML文档解析的一些常用规则及其在lxml库中的具体用法。实际上XPath还有一部分选择节点的方法,即按节点轴进行选取,我认为这部分在爬虫中不太好用,所以就没有在这里介绍,感兴趣的读者可以自己补充一下。
下一篇再通过一个实际网站的爬取来介绍XPath的应用,敬请期待!















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









