





大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子。与上一篇不同的是,这次我们需要用到文件的相关操作。
本篇目标对百度贴吧的任意帖子进行抓取
指定是否只抓取楼主发帖内容
将抓取到的内容分析并保存到文件
1. URL格式的确定
首先,我们先观察一下百度贴吧的任意一个帖子。
比如:http://tieba.baidu.com/p/3138733512?see_lz=1&pn=1,这是一个关于NBA50大的盘点,分析一下这个地址。
http:// 代表资源传输使用http协议
tieba.baidu.com 是百度的二级域名,指向百度贴吧的服务器。
/p/3138733512 是服务器某个资源,即这个帖子的地址定位符
see_lz 和 pn 是该 URL 的两个参数,分别代表了只看楼主和帖子页码,等于1表示该条件为真
所以我们可以把URL分为两部分,一部分为基础部分,一部分为参数部分。
例如,上面的URL我们划分基础部分是 http://tieba.baidu.com/p/3138733512,参数部分是 ?see_lz=1&pn=1
2. 页面的抓取
熟悉了URL的格式,那就让我们用urllib2库来试着抓取页面内容吧。上一篇糗事百科我们最后改成了面向对象的编码方式,这次我们直接尝试一下,定义一个类名叫BDTB(百度贴吧),一个初始化方法,一个获取页面的方法。
其中,有些帖子我们想指定给程序是否要只看楼主,所以我们把只看楼主的参数初始化放在类的初始化上,即init方法。另外,获取页面的方法我们需要知道一个参数就是帖子页码,所以这个参数的指定我们放在该方法中。
综上,我们初步构建出基础代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#-*-coding:utf8-*-
#created by 10412
import urllib
import urllib2
import re
#百度贴吧爬虫类
class BDTB:
#初始化,传入基地址,是否只看楼主的参数
def __init__(self, baseUrl, seeLZ):
self.baseURL = baseUrl
self.seeLZ = '?see_lz=' + str(seeLZ)
#传入页码,获取该页帖子的代码
def getPage(self, pageNum):
try:
url = self.baseURL + self.seeLZ + '&pn=' + str(pageNum)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
return response
except urllib2.URLError, e:
if hasattr(e, "reason"):
print u"连接百度贴吧失败,错误原因",e.reason
return None
baseURL = 'http://tieba.baidu.com/p/3138733512'
bdtb = BDTB(baseURL, 1)
bdtb.getPage(1)
运行代码,我们可以看到屏幕上打印出了这个帖子第一页楼主发言的所有内容,形式为HTML代码。
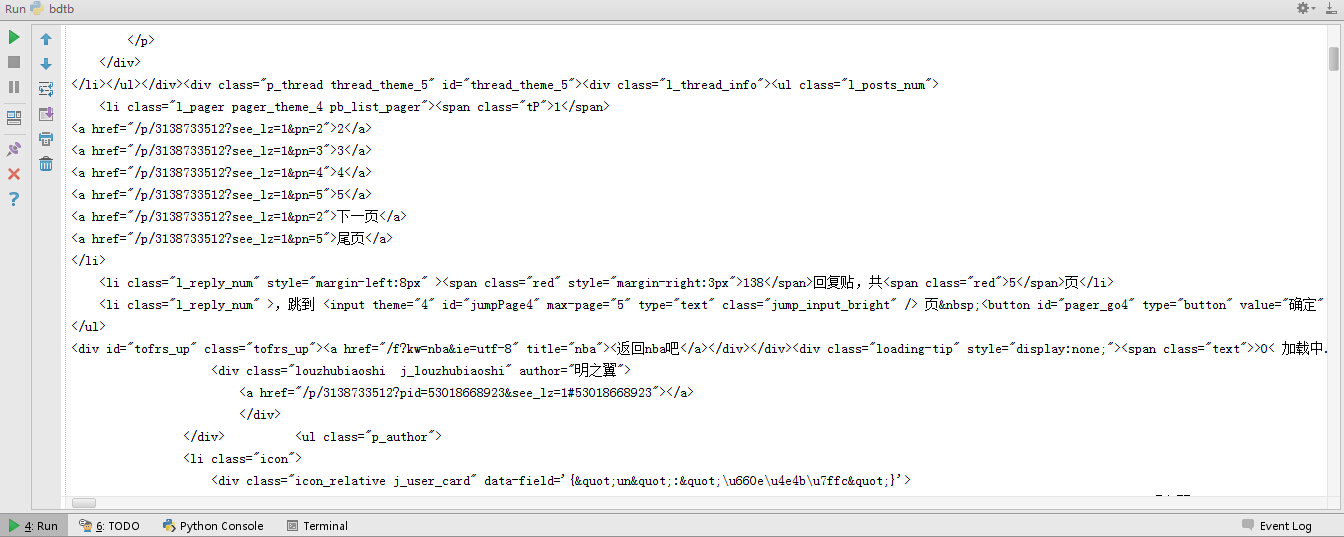
3. 提取相关信息
1)提取帖子标题
在浏览器中审查元素,或者按F12,查看页面源代码,我们找到标题所在的代码段如下:
1
纯原创我心中的NBA2014-2015赛季现役50大
所以我们要提取
中的内容,因为一开始可以查看整个界面的原代码,查看里面含有
标签的不止一个。所以需要写正则表达式来匹配,如下:
1
(.*?)
', re.S)result = re.search(pattern, page)
if result:
# print result.group(1) #测试输出
return result.group(1).strip()
else:
return None
2)提取帖子页数
同样地,帖子总页数我们也可以通过分析页面中的共?页来获取。
1
4784回复贴,共 36页所以我们的获取总页数的方法如下
1
2
3
4
5
6
7
8
9
10def (self):
page = self.getPage(1)
pattern = re.compile('
(.*?)所以提取正文内容的方法:
1
2
3
4
5
6#获取每一层楼的内容,传入页面内容
def getContent(self,page):
pattern = re.compile('

可以看到有很多的换行符和图片符,既然出现这样的情况,那肯定不是我们想要的结果。那我们就必须要将文本进行处理,将各种复杂的标签给剔除,还原帖子的原来面貌。可以使用一个方法或者类将这个处理文本的实现,不过为了更好的代码重用和架构,还是建议使用一个类。
我们将这个类命名为Too(工具类),里面定义一个replace方法,替换各种标签。然后在类中定义几个正则表达式,利用re.sub方法对文本进行匹配后然后替换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import re
#处理页面标签类
class Tool:
#去除img标签,7位长空格
removeImg = re.compile('| {7}|')
#删除超链接标签
removeAddr = re.compile('|')
#把换行的标签换为n
replaceLine = re.compile('
|#将表格制表
替换为treplaceTD= re.compile('
')#把段落开头换为n加空两格
replacePara = re.compile('
')#将换行符或双换行符替换为n
replaceBR = re.compile('
|
')
#将其余标签剔除
removeExtraTag = re.compile('<.*?>')
def replace(self,x):
x = re.sub(self.removeImg,"",x)
x = re.sub(self.removeAddr,"",x)
x = re.sub(self.replaceLine,"n",x)
x = re.sub(self.replaceTD,"t",x)
x = re.sub(self.replacePara,"n ",x)
x = re.sub(self.replaceBR,"n",x)
x = re.sub(self.removeExtraTag,"",x)
#strip()将前后多余内容删除
return x.strip()
在使用时,我们只需要初始化一下这个类,然后调用replace方法即可。
现在整体代码是如下这样子的,现在我的代码是写到这样子的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79#-*-coding:utf8-*-
#created by 10412
import urllib
import urllib2
import re
# 处理页面标签类
class Tool:
# 去除img标签,7位长空格
removeImg = re.compile('| {7}|')
# 删除超链接标签
removeAddr = re.compile('|')
# 把换行的标签换为n
replaceLine = re.compile('
|# 将表格制表
替换为treplaceTD = re.compile('
')# 把段落开头换为n加空两格
replacePara = re.compile('
')# 将换行符或双换行符替换为n
replaceBR = re.compile('
|
')
# 将其余标签剔除
removeExtraTag = re.compile('<.*?>')
def replace(self, x):
x = re.sub(self.removeImg, "", x)
x = re.sub(self.removeAddr, "", x)
x = re.sub(self.replaceLine, "n", x)
x = re.sub(self.replaceTD, "t", x)
x = re.sub(self.replacePara, "n ", x)
x = re.sub(self.replaceBR, "n", x)
x = re.sub(self.removeExtraTag, "", x)
# strip()将前后多余内容删除
return x.strip()
# 百度贴吧爬虫类
class BDTB:
# 初始化,传入基地址,是否只看楼主的参数
def __init__(self, baseUrl, seeLZ):
self.baseURL = baseUrl
self.seeLZ = '?see_lz=' + str(seeLZ)
self.tool = Tool()
# 传入页码,获取该页帖子的代码
def getPage(self, pageNum):
try:
url = self.baseURL + self.seeLZ + '&pn=' + str(pageNum)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
return response.read().decode('utf-8')
except urllib2.URLError, e:
if hasattr(e, "reason"):
print u"连接百度贴吧失败,错误原因", e.reason
return None
# 获取帖子标题
def getTitle(self):
page = self.getPage(1)
pattern = re.compile('
.*?(.*?)', re.S)
result = re.search(pattern, page)
if result:
# print result.group(1) #测试输出
return result.group(1).strip()
else:
return None
# 获取每一层楼的内容,传入页面内容
def getContent(self, page):
pattern = re.compile('

4)替换楼层
至于这个问题,我感觉直接提取楼层没什么必要呀,因为只看楼主的话,有些楼层的编号是间隔的,所以我们得到的楼层序号是不连续的,这样我们保存下来也没什么用。
所以可以尝试下面的方法:
1.每打印输出一段楼层,写入一行横线来间隔,或者换行符也好。
2.试着重新编一个楼层,按照顺序,设置一个变量,每打印出一个结果变量加一,打印出这个变量当做楼层。
将getContent方法修改如下:
1
2
3
4
5
6
7
8
9#获取每一层楼的内容,传入页面内容
def getContent(self,page):
pattern = re.compile('
print self.tool.replace(item)
floor += 1
运行结果截图如下:

4. 写入文件
代码:
1
2file = open(“tb.txt”,”w”)
file.writelines(obj)
5. 完善代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134#-*-coding:utf8-*-
#created by 10412
import urllib
import urllib2
import re
#处理页面标签类
class Tool:
#去除img标签,7位长空格
removeImg = re.compile('| {7}|')
#删除超链接标签
removeAddr = re.compile('|')
#把换行的标签换为n
replaceLine = re.compile('
|#将表格制表
替换为treplaceTD= re.compile('
')#把段落开头换为n加空两格
replacePara = re.compile('
')#将换行符或双换行符替换为n
replaceBR = re.compile('
|
')
#将其余标签剔除
removeExtraTag = re.compile('<.*?>')
def replace(self,x):
x = re.sub(self.removeImg,"",x)
x = re.sub(self.removeAddr,"",x)
x = re.sub(self.replaceLine,"n",x)
x = re.sub(self.replaceTD,"t",x)
x = re.sub(self.replacePara,"n ",x)
x = re.sub(self.replaceBR,"n",x)
x = re.sub(self.removeExtraTag,"",x)
#strip()将前后多余内容删除
return x.strip()
#百度贴吧爬虫类
class BDTB:
#初始化,传入基地址,是否只看楼主的参数
def __init__(self,baseUrl,seeLZ,floorTag):
#base链接地址
self.baseURL = baseUrl
#是否只看楼主
self.seeLZ = '?see_lz='+str(seeLZ)
#HTML标签剔除工具类对象
self.tool = Tool()
#全局file变量,文件写入操作对象
self.file = None
#楼层标号,初始为1
self.floor = 1
#默认的标题,如果没有成功获取到标题的话则会用这个标题
self.defaultTitle = u"百度贴吧"
#是否写入楼分隔符的标记
self.floorTag = floorTag
#传入页码,获取该页帖子的代码
def getPage(self,pageNum):
try:
#构建URL
url = self.baseURL+ self.seeLZ + '&pn=' + str(pageNum)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
#返回UTF-8格式编码内容
return response.read().decode('utf-8')
#无法连接,报错
except urllib2.URLError, e:
if hasattr(e,"reason"):
print u"连接百度贴吧失败,错误原因",e.reason
return None
#获取帖子标题
def getTitle(self,page):
#得到标题的正则表达式
pattern = re.compile('
.*?(.*?)',re.S)
result = re.search(pattern,page)
if result:
return result.group(1).strip()
else:
return None
#获取每一层楼的内容,传入页面内容
def getContent(self,page):
#匹配所有楼层的内容
pattern = re.compile('
contents.append(content.encode('utf-8'))
return contents
def setFileTitle(self,title):
#如果标题不是为None,即成功获取到标题
if title is not None:
self.file = open(title + ".txt","w+")
else:
self.file = open(self.defaultTitle + ".txt","w+")
def writeData(self,contents):
#向文件写入每一楼的信息
for item in contents:
if self.floorTag == '1':
#楼之间的分隔符
floorLine = "n" + str(self.floor) + u"-----------------------------------------------------------------------------------------n"
self.file.write(floorLine)
self.file.write(item)
self.floor += 1
def start(self):
indexPage = self.getPage(1)
pageNum = self.getPageNum(indexPage)
title = self.getTitle(indexPage)
self.setFileTitle(title)
if pageNum == None:
print "URL已失效,请重试"
return
try:
print "该帖子共有" + str(pageNum) + "页"
for i in range(1,int(pageNum)+1):
print "正在写入第" + str(i) + "页数据"
page = self.getPage(i)
contents = self.getContent(page)
self.writeData(contents)
#出现写入异常
except IOError,e:
print "写入异常,原因" + e.message
finally:
print "写入任务完成"
print u"请输入帖子代号"
baseURL = 'http://tieba.baidu.com/p/' + str(raw_input(u'http://tieba.baidu.com/p/'))
seeLZ = raw_input("是否只获取楼主发言,是输入1,否输入0n")
floorTag = raw_input("是否写入楼层信息,是输入1,否输入0n")
bdtb = BDTB(baseURL,seeLZ,floorTag)
bdtb.start()
运行后截图如下:

备注:运行后注意输入帖子的代号先在网址后空格,再输入帖子代号,输入完再把刚才的空格
删除,只有这样才不会报错。
Traceback (most recent call last):
File “E:/python/code/PycharmProject/Python-Projects/baidutieba/BDTB3.py”, line 149,
in < module >
bdtb.start()
File “E:/python/code/PycharmProject/Python-Projects/baidutieba/BDTB3.py”, line 123, in start
pageNum = self.getPageNum(indexPage)
File “E:/python/code/PycharmProject/Python-Projects/baidutieba/BDTB3.py”, line 86, in getPageNum
result = re.search(pattern,page)
File “C:Python27libre.py”, line 146, in search
return _compile(pattern, flags).search(string)
TypeError: expected string or buffer















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









