





在观看本文之前,你需要了解以下技术
爬虫的五个步骤
a) 需求分析 程序员,人工智能
b) 找到内容相关的网址 程序员
c) 根据网址获取到网址的返回信息 程序(urllib, requests)
d) 定位需要的信息位置 程序(re正则表达式, XPATH, css selector)
e) 存储内容 程序(文件系统open, pymysql, pymongo)
今天需要做的事情有哪些
a) HTTP/HTTPS
b) 如何能够观察HTTP的包
c) 使用requests的包, get, post
包头中重要的信息描述
a) Cookie : 能够存储一些服务器端的信息,与session共同完成身份标志的工作
b) User-Agent : 你的标签有哪些
c) Referer : 从哪个页面跳转过来的
如果浏览器能够访问, 但是你不能, 添加headers, 先添加User-Agent, 再添加
Referer, 最后添加Cookie, 最最后全添加.
爬取一个网站的时候,你需要确定信息是不是在这个网站上的
注意,在抓包的过程中, 最好将 preserve_log 勾选上
右键->检查->network->Preserve log
谷歌开发者工具里面这个preserve log :保留请求日志,跳转页面的时候勾选上,可以看到跳转前的请求,也可适用于chrome开发者工具抓包的问题
如果需要登录后才能访问的内容, 我们可以先做登录, 然后再访问
这里就需要用到一个类, session
将所有的requests改成session的实例就可以了
需求
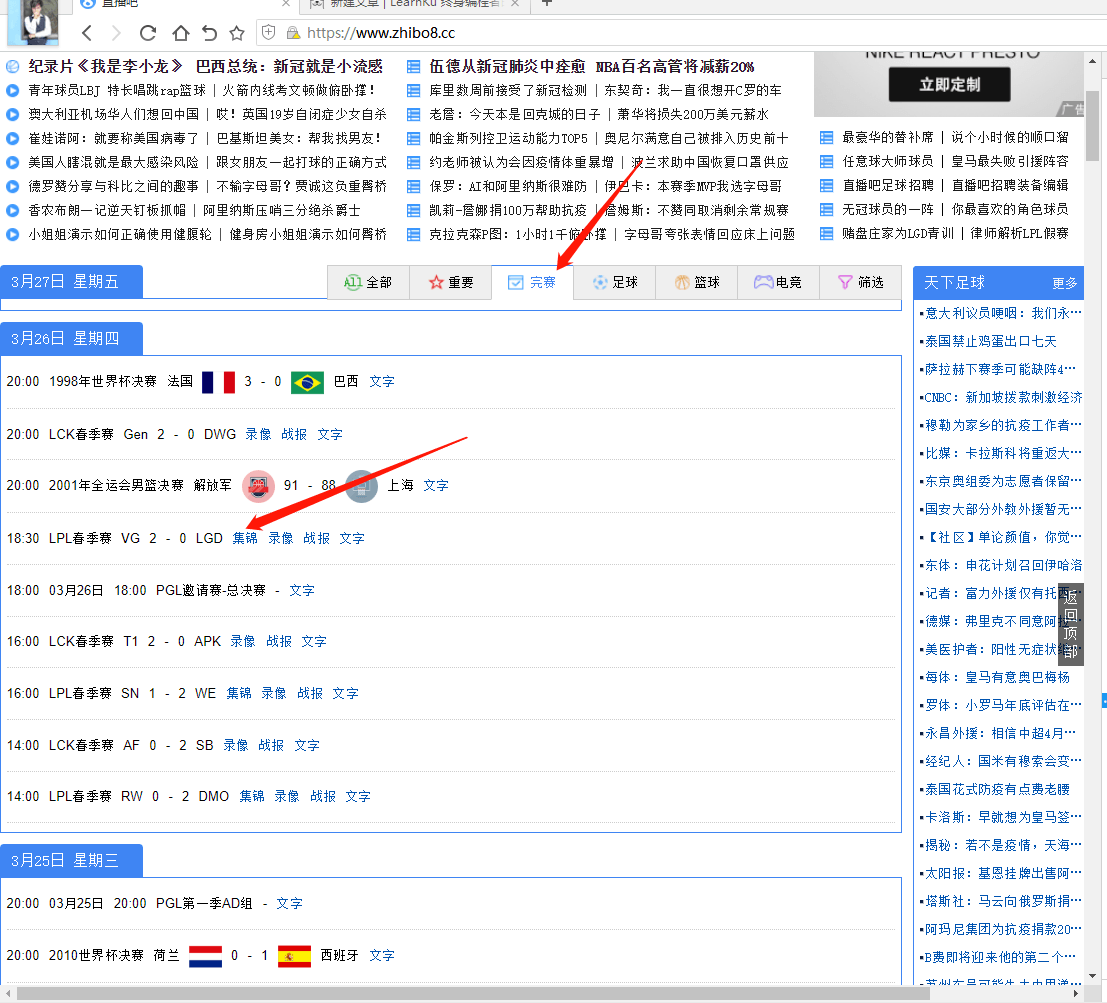
根据条件,匹配 指定li,点击进入集锦。
把集锦列表拿走。
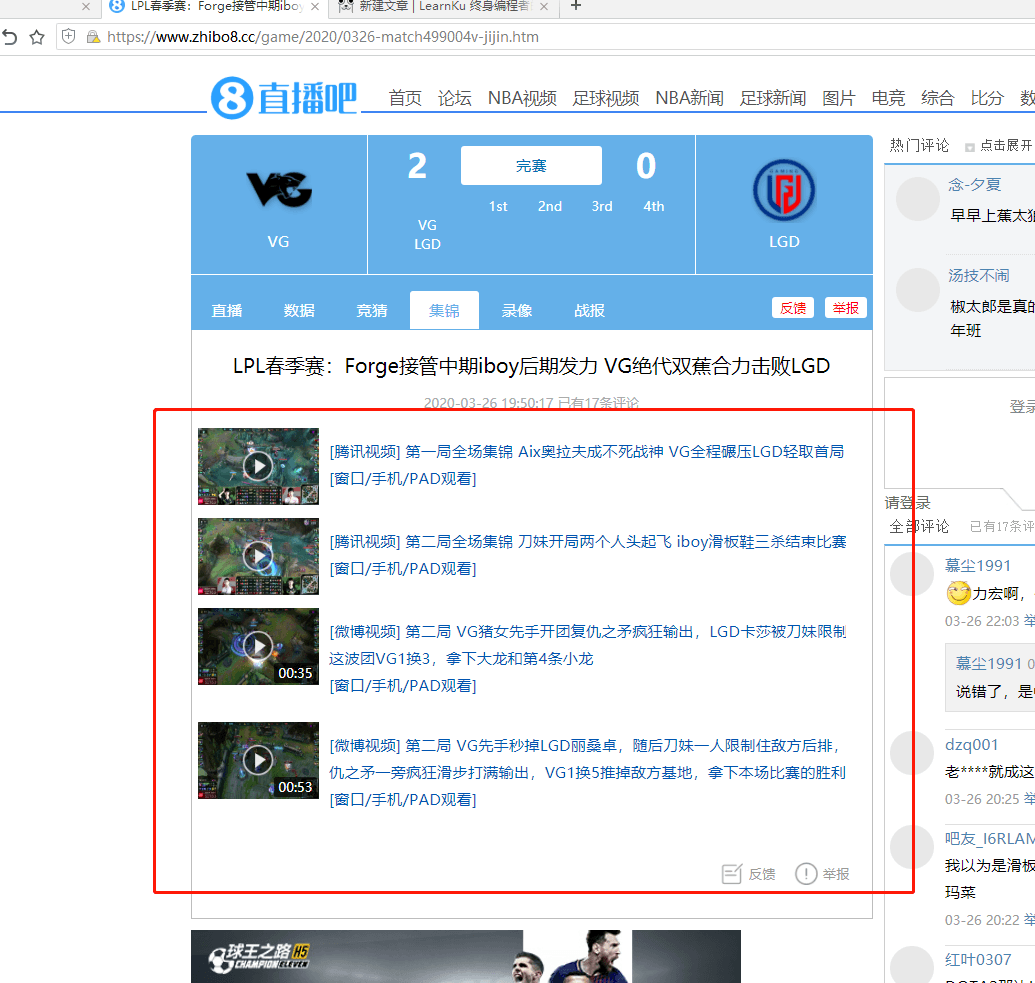
1. 目标网站
赛事: 下面的一个完赛板块。
根据 日期 主队 客队 匹配比赛,进入比赛拿走集锦。
2. 分析网页
先来看看这个主页的 完赛板块,是如何实现的,是ajax,还是jq隐藏展示
最要查看是否有请求:
没有请求,肯定是jq 隐藏展示控制的。也就是主页一打开,这些html 元素和数据 都是加载好的。
那明确目标: 我们爬取的第一次访问数据,一定是首页。
第二:找到 我们要的 完赛 的html元素,特征点。
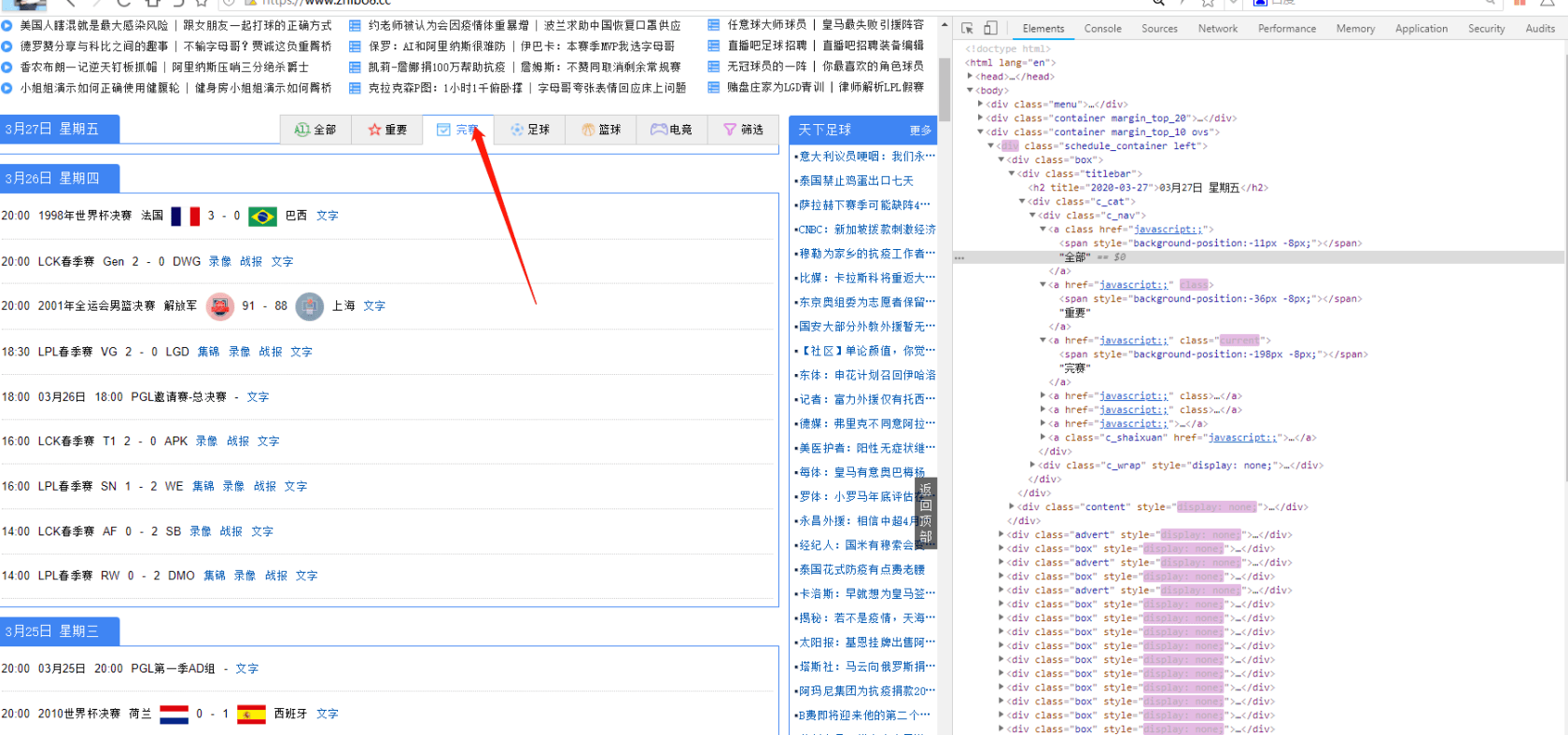
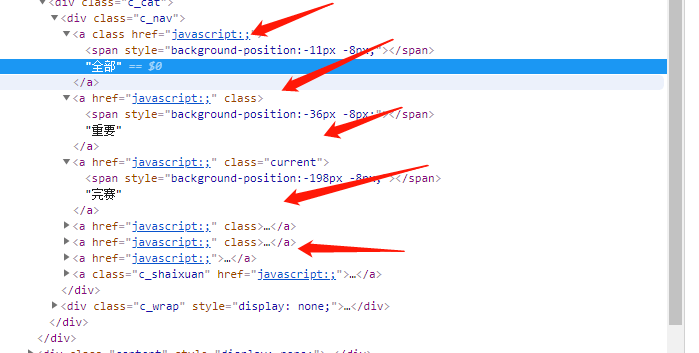
这里发现,点击tab 是没有特征的。
找到完赛的 div
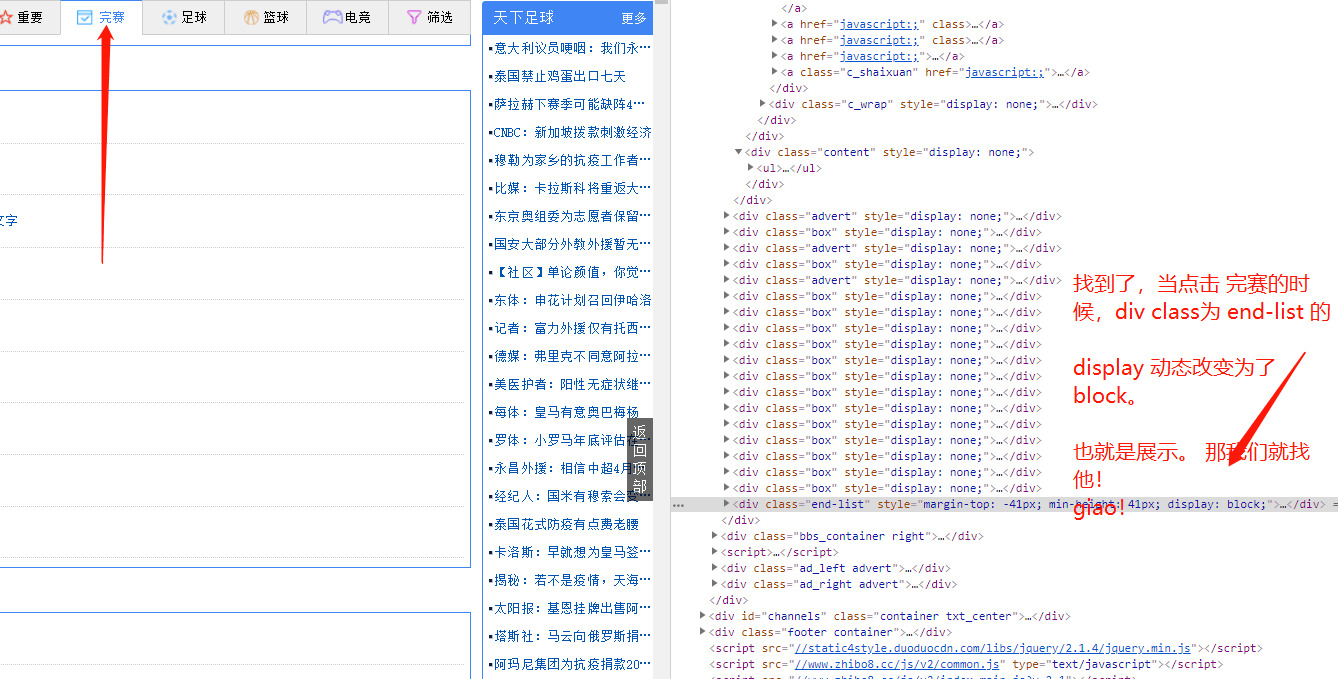
第三 找规则
找准我们要匹配的数据。
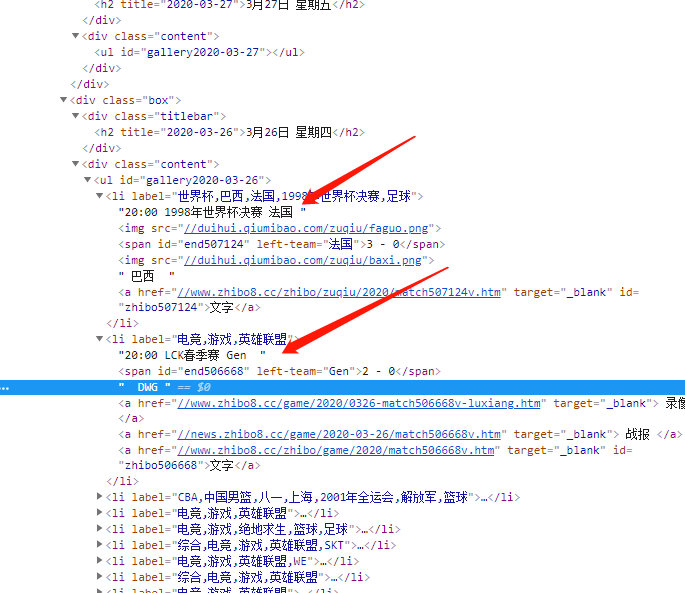
日期;主队,客队。
发现 他存在,如图所示,箭头出。
日期,是 div class content -> div class titlebar!
主队客队名字 在 div class content-> li 文字有。和 有一个属性,left-team。
客队名字: div class content-> li ->img 文字下。
那么找到了规则。我们就开始写脚本吧。
3. 编写爬虫脚本
现在 开始编写,第一部分的 脚本。
预计分为两个步骤。
1. 首页 找到指定比赛li 获得下一个脚本 的详情url
详情页 爬取 集锦
存入数据库
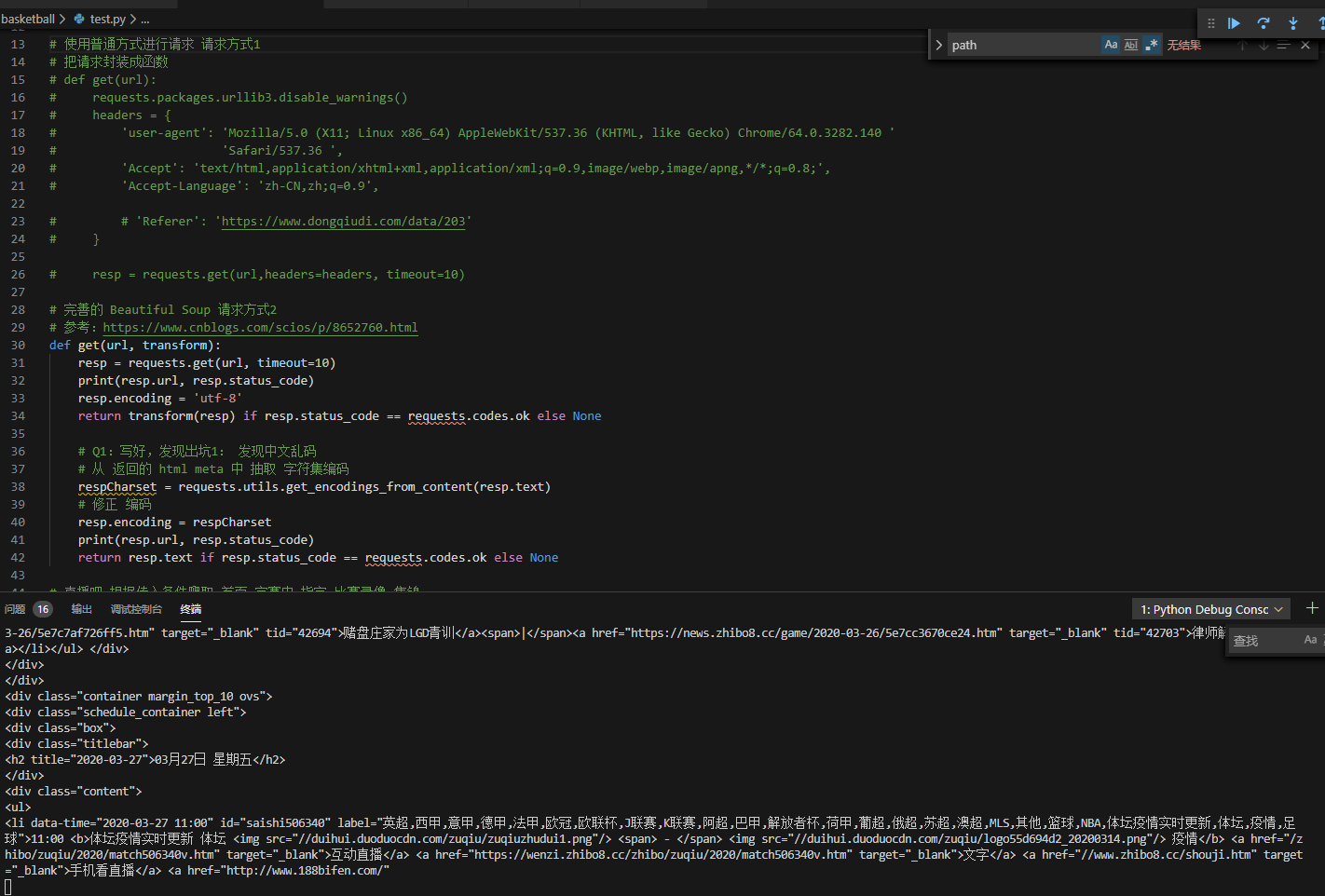
直播结果截图
写了两种get 方式,目前已经拿到数据,正在写规则匹配
本作品采用《CC 协议》,转载必须注明作者和本文链接
感谢关注
上海PHP自学中心-免费编程视频教学|















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









