





点击上方『早起Python』关注并星标
第一时间接收最新Python干货!

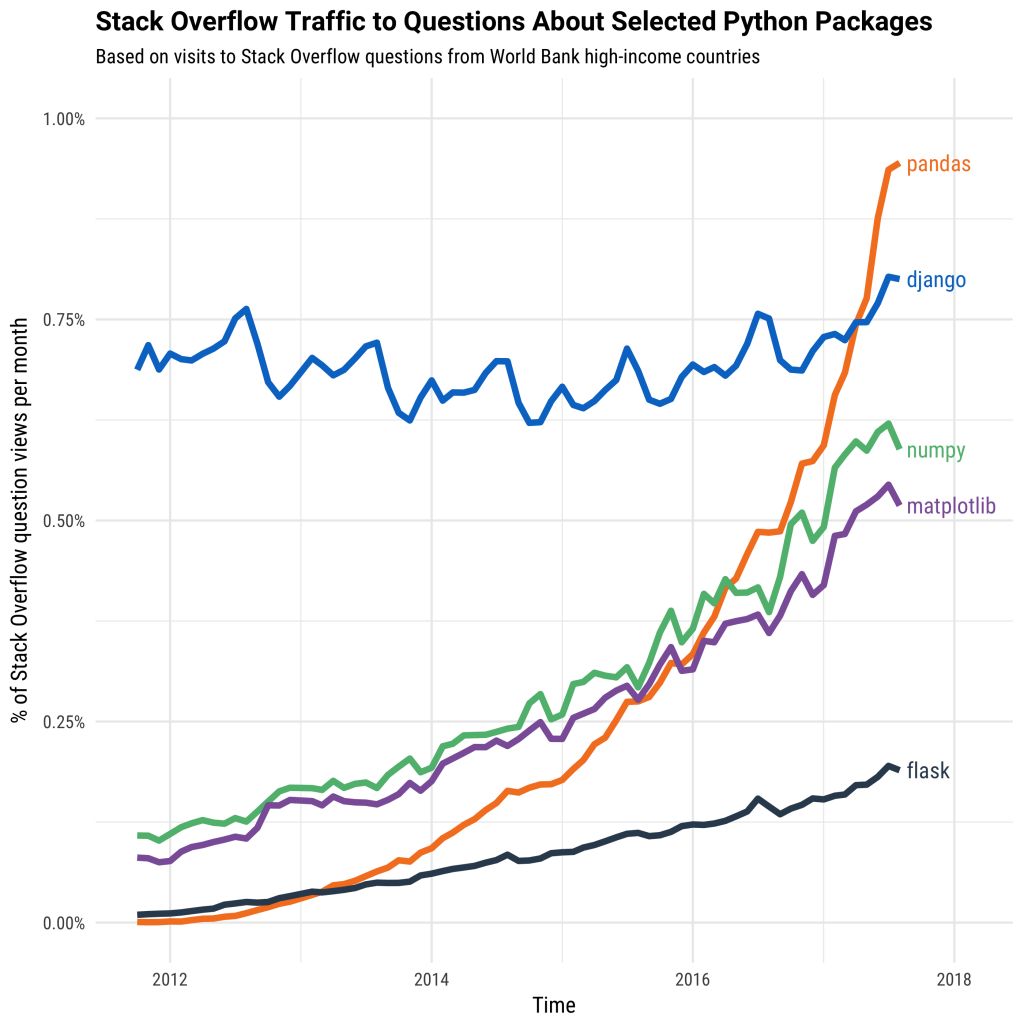
pandas库是python中最有名的数据分析库,因为dataframe这种易用强大的数据类型,pandas成为数据科学必备套件。pandas可以和很多包联合使用,比如与机器学习sklearn、统计分析statsmodels、可视化searborn&matplotlib等等。下图是近几年python包的使用量趋势,pandas一骑绝尘
安装
pip install ray
pip install dask
pip install modin
modin使用
modin的用法与pandas相差无几,只是在导入的时候略有不同。
import modin.pandas as pd
现在这个pd就拥有与pandas一样的功能
读取速度
说了这么多了,我们先看看pandas导入test.csv文件(107M)的速度。
import time
import pandas as pd
start = time.time()
df = pd.read_csv('data/test.csv')
end = time.time()
print(end-start)
1.611081838607788
pandas导入107M的test.csv耗时1.78s
import time
import modin.pandas as pd
start = time.time()
#test.csv 107M
df = pd.read_csv('data/test.csv')
end = time.time()
print(end-start)
0.7474761009216309
modin只用了0.75s,加快了2.1倍。
运算速度
pd.concat是用来连接多个dataframe的操作函数,当我们的df很大时,pd.concat就会变慢。我们在这里实验一下pandas和modin各自的速度
import time
import pandas as pd
df = pd.read_csv('data/test.csv')
start = time.time()
newdf = pd.concat([df for _ in range(100)])
end = time.time()
print(end-start)
10.625022888183594
import time
import modin.pandas as pd
df = pd.read_csv('data/test.csv')
start = time.time()
newdf = pd.concat([df for _ in range(100)])
end = time.time()
print(end-start)
0.7488729953765869
同样的pd.concat操作,modin比pandas快了14倍。我又做了几个对比,制作成表格

实战技巧
modin目前仍然正在发展中,并不是所有的pandas的函数都能加速。如果加速遇到报错,说明这个操作modin不支持。
默认modin会调用电脑全部的cpu,如果不想全部调用,可以使用ray来限制cpu使用数。
import ray
import warnings
warnings.filterwarnings('ignore')
ray.init(num_cpus=4, ignore_reinit_error=True)
import modin.pandas as pd
如果待操作的数据文件远大于电脑内存RAM,可以设置
import os
os.environ["MODIN_OUT_OF_CORE"]='true'
import modin.pandas as pd

本周依旧给常读常分享用户赠书,两本从零开始学Python数据分析包邮送?明天公布名单~

只要多看多分享就有机会获得,当然也可以点击下方小程序直接购买
 想做疫情分析却没有数据?看这篇就够了
想做疫情分析却没有数据?看这篇就够了
 点在看,看更多
点在看,看更多















 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









