






阅读原文,更加美观。
MapReduce 计算框架概要
上一期我们聊到 MapReduce 编程模型将大数据计算过程切分为 Map 和 Reduce 两个阶段。 先复习一下,在 Map 阶段为每个数据块分配一个 Map 计算任务,然后将所有 map 输出的 Key 进行合并。 相同的 Key 及其对应的 Value 发送给同一个 Reduce 任务去处理。通过这两个阶段,工程师只需要遵循 MapReduce 编程模型就可以开发出复杂的大数据计算程序。
我们已经对 MapReduce 有一个值观的认识并知道它的工作原理:将输入拆分成多份小输出并行处理。 现在是时候来鸟瞰一下 MapReduce 的整体系统架构和数据流的走向了。
在一个经典的Hadoop集群中,MapReduce 运行在 HDFS 和 YARN 之上。
HDFS 是一个分布式文件系统,它提供了将大数据文件以分散和高可用的形式存放在大规模节点的集群中的功能,详细的介绍可以参考我之前的文章。
YARN 则是一个比较抽象的概念。我们姑且先将它理解为一组后台进程,目的是为了做两件事情:
- 资源管理(CPU、内存等计算资源)
- 作业调度、监视
这两件事情其实是 Hadoop 作为分布式系统来看的核心功能,我认为这也是管理基础设施(服务器的计算资源和进程)的分布式系统共同的核心目的。 说得通俗一点就是管理进程和分配资源的分布式系统。
Hadoop 1 vs Hadoop 2
Hadoop 现在的最新大版本是 3.x,我们需要知道 1.x 和 2.x 之间在基础组件上是有重大区别的。
最主要的区别就是新增了 YARN 这个基础组件。我们应该知道,一切的中间层都是为了解耦。
计算机科学中的每个问题都可以用一间接层解决 (All problems in computer science can be solved by another level of indirection.)
by: David John Wheeler - 他是世界上第一个计算机科学博士。
YARN 的基本思想是将资源管理和作业调度/监视的功能拆分为单独的守护程序。 这里,我只简单地提及一下 Hadoop 1.x 和 2.x 的区别,之后在学习 YARN 的时候,再详细讲它的架构和工作方式。
术语
首先,我们来看一下 MapReduce 相关的术语(glossary)。
- 作业(job)
MapReduce作业是客户端要执行的工作单元:它由输入数据,MapReduce程序和配置信息组成。 - 任务(task)
有两种类型:map任务和reduce任务。这些任务是使用 YARN 来调度的,并在群集中的节点上运行。如果任务失败,它将自动重新安排为在其他节点上运行。
注意:Hadoop 1.x 没有 YARN,所以任务的调度是集成在 MapReduce 框架内的。 并且由于从 Hadoop 2.x 开始,除了支持 MapReduce,还有 Spark 这样的新的计算框架,为了将编程模型和调度引擎解耦,YARN 才应运而生。
- 输入数据分片(input split)
Hadoop将MapReduce作业的输入分为固定大小的片段,称为输入数据分片或分片。 Hadoop为每个分片创建一个map任务,该任务为分片中的每个记录运行用户定义(编写)的map函数。 - 记录(record)
在 MapReduce 中,有2个和输入数据相关的概念:ImputFormat和RecordReader。我们应该先从宏观上理解。 对于操作系统机而言,一切数据都是以字节为单位来存储的,通过各种编码来转换并应用于文本、音频、视频等数据格式。 HDFS实现了一套数据类型的输入规范,比如一行原始数据文本可能保存在多个数据块中,HDFS将封装好的数据类型接口提供给我们来使用。就像我们在Python中调用file()系统方法来调用OS的接口以打开一个本地文件一样。 常见的InputFormat有FileInputFormat,以及其子类TextInputFormat。 MapReduce 框架依赖 InputFormat 来处理输入的数据。 你可以类比成这个场景:当一个压缩文件太大了,你的单块磁盘装不下,你就需要将这个压缩文件拆分成多个分割文件。 比如:example.rar分割成example.part1.rar, example.part2.rar,... 我们在处理这些压缩文件的分割文件时,需要指定压缩格式,这个压缩格式就类似于MapReduce中的InputFormat。 通常,RecordReader会转换输入数据块提供的输入的面向字节的视图,并将面向记录的形式呈现给Mapper实现以进行处理。 在TextInputFormat前提下,一个记录就是经过RecordReader处理后的一行文本,以n为分隔符。 值得注意的是,原始文本数据存储在HDFS中时,不一定是在同一个数据块中的,所以这是TextInputFormat实现的逻辑。 - 数据局部性优化(data locality optimization)
在一个HDFS节点上保存着数据,Hadoop会尽力在该节点上运行map任务,因为这样不会使用宝贵的集群网络带宽。 - 分区(partition)
这里的分区指map任务输出的中间产物,是在交给reducer消费前聚合的产物。请参考图例 2-4。 - 组合器函数(Combiner Functions)
这是用户自定义的,作用于map任务的输出,并且是在"Shuffle and Sort"的过程中被执行的,更准确地说,由于这个是为了减少跨界点的网络带宽使用量,所以是在shuffle的过程中,在map任务本地节点上使用本地的中间产出物执行的。
数据流向
现在我们知道,MapReduce的map任务会读取节点上的数据块,根据数据块、map任务所在的节点位置,可以推导出以下3种分部情况,如图例2-2:

图例 2-2. Data-local (a), rack-local (b), and off-rack (c) map tasks
map任务的输出是MapReduce作业的中间产物,是给reduce任务使用的,reduce任务一完成就没用了,所以不会保存在HDFS中,只会保存在本地文件系统中。 如果一个reduce任务在消费map的中间产物过程中,map所在的节点失败了,那Hadoop会自动重新找一个节点再运行一次该map任务。
reduce任务不会用到本地文件系统,通常来说一个reduce任务的输入是所有mapper的输出。所以运行reduce任务通常肯定会消耗集群中网络带宽,但是也只会和普通的HDFS层面的管道写入操作消耗相同的带宽。
单个reduce任务的整个数据流向如图例 2-3:

图例 2-3. MapReduce data flow with a single reduce task
reduce任务的数量不是靠输入数据的大小来决定的,而是有单独指定的方式。之后我会阐述如何选择reduce任务的数量。
在有多个reducer的情况下,map任务会将它们的输出进行分区处理,每个分区将被一个reducer来消费。 在每个分区中可能有多个<Key, Value>,并且相同的key只会在同一个分区中出现。
一个有着多个reduce任务的数据流向如图例 2-4:

图例 2-4. MapReduce data flow with multiple reduce tasks
在图中的map和reduce任务之间的生成中间产物的阶段,我们习惯称之为"Shuffle and Sort",实际上比上面的2个图例要复杂很多,对这个过程的调优将会对作业的执行时间产生巨大的影响。 之后我也许会记录这个过程的细节。
最后,还有一种是只有0个reduce任务的情况。 这种情况就是你的业务需求不需要执行"shuffle"阶段的操作。这个情况的例子包括使用NLineInputFormat这个InputFormat时的用例。后续有机会我也会记录。 这种情况下,会消耗带宽的操作只有map任务输出到HDFS时(参考图例 2-5),产生的跨节点的操作(repliacation)。
组合器函数(Combiner Functions)
许多MapReduce作业受群集上可用带宽的限制,因此需要最大程度地减少在map和reduce任务之间传输的数据。 Hadoop允许用户指定要在map输出上运行的组合器函数,并且组合器函数的输出构成了reduce函数的输入。 因为合并器功能是一种优化,所以Hadoop不能保证它会为特定的map输出记录调用多少次(如果有的话)。 换句话说,调用组合器函数0,1或多次应从reducer产生相同的输出。

图例 2-5. MapReduce data flow with no reduce tasks
组合器函数的约定限制了可以使用的函数的类型。最好用一个例子说明。 假设以最高温度为例,通过两个map处理了1950年的读数(因为它们位于不同的输入数据分片中)。想象一下第一个map产生的输出:
(1950, 0)
(1950, 20)
(1950, 10)第二个产生:
(1950, 25)
(1950, 15)reduce函数将接受到所有的value形成的列表作为输入:
(1950, [0, 20, 10, 25, 15])输出:
(1950, 25)因为25是列表中的最大值。我们可以使用组合器函数,就像reduce函数一样,为每个map输出找到最高温度。然后reduce被调用时会接受到的输入就像以下这样:
(1950, [20, 25])并将产生与以前相同的输出。更简洁地说,在这个案例下,我们可以按以下的方式解释对于温度value的函数调用:
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25并非所有函数都具有此属性。例如,如果我们计算一个平均气温,我们不能使用mean函数来作为我们的组合其函数,因为:
mean(0, 20, 10, 25, 15) = 14但是:
mean(mean(0, 20, 10), mean(25, 15)) = mean(10, 20) = 15合并器函数不能替代reduce函数。(就如上面的例子一样,有些业务必须处理来自不同的map输出的相同的key所对应的value) 但这可以帮助减少map和reduce之间的数据交换量,仅出于这个原因,始终值得考虑是否可以在MapReduce作业中使用合并器函数。
类似上面的max函数一样,具有此属性的函数称为 可交换(commutative)的和 关联的(associative)。 有的时候也被称为 分布式的,例如Jim Gray等人的 "Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals",February1995.
指定一个组合器函数
我们回到上一篇文章中的Java MapReduce程序中去,组合器函数是使用Reducer类来定义的,并且对于这个应用程序来说,它的实现和MaxTemperatureReducer中的reduce函数一样。 唯一的变化是我们需要在Job上设置组合器的类(如 示例 2-6)。
示例 2-6. 在天气数据集中查找最高温的应用,使用组合器函数来提高效率
public class MaxTemperatureWithCombiner {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperatureWithCombiner <input path> " +
"<output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperatureWithCombiner.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
NOTE: 对比Java MapReduce程序中的
示例 2-5,其实只是多了
job.setCombinerClass(MaxTemperatureReducer.class);这一行。
Hadoop流(streaming)
Hadoop提供了MapReduce的API,该API允许您编写使用Java以外的其他语言来编写map和reduce函数。
Hadoop Streaming使用Unix标准流作为Hadoop与您的程序之间的接口,因此您可以使用可以读取标准输入并写入标准输出的任何语言来编写MapReduce程序。
流自然是适合文本处理的。Map输入数据通过标准输入传递到map函数,该map函数逐行对其进行处理并将行写入标准输出。 Map的输出的每一行为对,以单个制表符为分隔符。 reduce函数的输入采用相同的格式(制表符分隔的对),通过标准输入传入。 reduce函数从标准输入读取行,框架保证以Key来对行进行排序,并将其结果写入标准输出。
让我们通过重写MapReduce程序来说明这一点,该程序可在Streaming中按年份查找最高温度。
Ruby
map函数可以用Ruby表示,如示例 2-7所示。
示例 2-7. 用Ruby写的用来查找最高温的Map函数
#!/usr/bin/env ruby
STDIN.each_line do |line|
val = line
year, temp, q = val[15,4], val[87,5], val[92,1]
puts "#{year}t#{temp}" if (temp != "+9999" && q =~ /[01459]/)
end该程序通过对来自STDIN(IO类型的全局常量)中的每一行执行一个块(block)来遍历标准输入中的行。 该块从每个输入行中提取相关字段,如果温度有效,则将以制表符 t分隔的年份和温度写入标准输出(使用puts)。
注意
值得一提的是Streaming与Java MapReduce API之间的设计差异。 Java API的map函数旨在一次处理一个记录。 MapReduce框架为输入中的每个记录调用Mapper(类)上的map()方法,而通过流式处理,map程序可以决定如何处理输入--例如,由于你可以控制标准输入的数据,因此一次可以轻松读取和处理多行。 用户的Java map实现是“推送”记录,但通过在Mapper的实例变量中累积前几行,仍然可以考虑一次累计多行。 在这种情况下,您需要实现close()方法,以便知道何时读取了最后一条记录,从而可以完成对最后一组行的处理。
由于脚本仅在标准输入和输出上运行,因此无需使用Hadoop就可以轻松测试脚本,只需使用Unix管道即可:
% cat input/ncdc/sample.txt | ch02-mr-intro/src/main/ruby/max_temperature_map.rb
1950 +0000
1950 +0022
1950 -0011
1949 +0111
1949 +0078示例2-8中显示的reduce函数稍微复杂一点。
示例2-8 用Ruby来计算出最高温度的reduce函数
#!/usr/bin/env ruby
last_key, max_val = nil, -1000000
STDIN.each_line do |line|
key, val = line.split("t")
if last_key && last_key != key
puts "#{last_key}t#{max_val}"
last_key, max_val = key, val.to_i
else
last_key, max_val = key, [max_val, val.to_i].max
end
end
puts "#{last_key}t#{max_val}" if last_key同样,程序在标准输入的行上进行迭代,但是这次我们在处理每个key group时必须存储一些状态。 在这种情况下,key是年份,并且我们存储最后看到的key和到目前为止看到的最高温度(value)。 MapReduce框架可确保key是有序的,因此我们知道,如果一个key与前一个key不同,我们已经到了一组新的<Key, Value>(在遍历过程中)。
Note: 上面这段话用示意图来说明比较好。 假设在Ruby的map阶段,输出如下:plain-text 1950 +0000 1949 +0111 1950 +0022 1950 -0011 1949 +0078 1948 +0128 1948 +0108那么在经过Hadoop流传给Ruby的reduce时,输入是已经被排序了的:plain-text 1948 +0128 1948 +0108 1949 +0111 1949 +0078 1950 +0000 1950 +0022 1950 -0011
与Java API相反,在Java API中为每个键组提供了迭代器,在Streaming中,您必须在程序中查找键组边界。 对于每一行,我们拉出键和值。 然后,如果我们刚刚完成了一组(last_key && last_key!= key),则在开始处理新键的最高温度之前,我们就写出该键和该组的最高温度(由制表符分隔)。 如果我们还没有完成一组处理,那么只需更新当前键对应的最高温度即可。 这个程序的最后一行代码确保为输入中的最后一个键组输出处理完成的结果。
现在我们可以使用Unix管道(相当于图例2-1中所示的Unix管道)模拟整个MapReduce管道:
% cat input/ncdc/sample.txt |
ch02-mr-intro/src/main/ruby/max_temperature_map.rb |
sort | ch02-mr-intro/src/main/ruby/max_temperature_reduce.rb
1949 111
1950 22输出与Java程序的输出相同,因此下一步是使用Hadoop本身运行它。
Hadoop命令行工具里并没有Streaming选项。取而代之的是,您可以通过jar选项来指定Streaming JAR文件来使用流功能。 Streaming程序的选项指定输入和输出路径以及map和reduce脚本。 它看起来像这样:
% hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
-input input/ncdc/sample.txt
-output output
-mapper ch02-mr-intro/src/main/ruby/max_temperature_map.rb
-reducer ch02-mr-intro/src/main/ruby/max_temperature_reduce.rb在集群上的大型数据集上运行时,我们应使用-combiner选项设置组合器:
% hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
-files ch02-mr-intro/src/main/ruby/max_temperature_map.rb,
ch02-mr-intro/src/main/ruby/max_temperature_reduce.rb
-input input/ncdc/all
-output output
-mapper ch02-mr-intro/src/main/ruby/max_temperature_map.rb
-combiner ch02-mr-intro/src/main/ruby/max_temperature_reduce.rb
-reducer ch02-mr-intro/src/main/ruby/max_temperature_reduce.rb还请注意-files的使用,它会帮我们我们把本地脚本传送到集群上各个节点,以运行Streaming程序。
Python
现在我们再来看一个Python版本的例子,因为我比较熟悉Python,所以看起来也比较亲切~
Python社区有一个叫Dumbo的第三方包,更加Pythonic以及更易于使用。
map脚本在示例 2-9中,reduce脚本在示例 2-10中。
示例 2-9. Python实现的计算最高温的map函数
#!/usr/bin/env python
import re
import sys
for line in sys.stdin:
val = line.strip()
(year, temp, q) = (val[15:19], val[87:92], val[92:93])
if (temp != "+9999" and re.match("[01459]", q)):
print "%st%s" % (year, temp)示例 2-10。 Python实现的计算最高温的reduce函数
#!/usr/bin/env python
import sys
(last_key, max_val) = (None, -sys.maxint)
for line in sys.stdin:
(key, val) = line.strip().split("t")
if last_key and last_key != key:
print "%st%s" % (last_key, max_val)
(last_key, max_val) = (key, int(val))
else:
(last_key, max_val) = (key, max(max_val, int(val)))
if last_key:
print "%st%s" % (last_key, max_val)我们可以像在Ruby中一样测试程序并运行作业。例如,运行测试:
% cat input/ncdc/sample.txt |
ch02-mr-intro/src/main/python/max_temperature_map.py |
sort | ch02-mr-intro/src/main/python/max_temperature_reduce.py
1949 111
1950 22学而思
如何实现Java MapReduce的WordCount
在上一篇记录MapReduce的编程模型的文章中,开头我记录了一个Python单机版本wordcount例子。 看完今天这篇文章的内容,我想您应该可以利用所学到的概念来推测出如果要用Java来实现WordCount的MapReduce程序,应该怎么写了。
正所谓学而不思则罔,虽然我已经完全不记得Java的语法以及特性,不过我们IT从业者应该具备抽象地思维能力,所以,大胆地基于现有的知识才推论吧!
首先我们应该想到,WordCount是要累计地计算出现的单词去重后,每个单词一共有多少个。 假设我们的原始数据是一个巨大的文本文件,并且是以n分了行的。 那么map函数的输入应该是<Offset, LineText>,输出则是<Word, 1> ,此处map函数只需要对LineText进行以下处理--用空格或者t来分割LineText,每遇到一个Word就输出<Word, 1>, 所以有许多个数据块,每个数据块都会输出许多相同的<Word, 1>。
在shuffle过程中,应该将map输出的<Word, 1>合并成<Word, [1,1,...]>。 所以交给reduce的是来自所有数据块产出的<Word, [1,1,...]>,且Word是唯一的。
然后就交给reduce函数处理,reduce将来自map的<Word, [1,1,...]>处理,输出为<Word, Count>。
我画个图来说明,会更加直观,照葫芦画瓢就行啦~
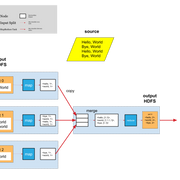
延申的思考
- 公有云上的Hadoop集群为什么使用对象存储?
通过学习HDFS和MapReduce,我们知道了为了加快作业的处理速度,我们应该尽可能的将map任务调度到拥有所需数据块的节点上, 也就是说Hadoop的作业调度系统应该是有机架感知能力(Rack Awareness)的。 那么现在在公有云上搭建Hadoop集群时,我们的数据是否还存放在本地磁盘呢?显然不是的,现在的公有云Hadoop产品,默认的存储都倾向于使用对象存储,这就要消耗集群内的网络带宽。 在公有云内,是否使用对象存储服务的性价比已经远超于使用本地磁盘呢? 要知道现在我们创建云主机依然可以选择使用本地磁盘,而不使用默认的云磁盘。 - 更加复杂的编程实现
为了加快作业的速度,我们是否可以在多个节点上同时对一个数据块的多个副本进行map任务? 比如block 0有3个副本,分别存放在3个节点上,对于block 0,节点1-3上执行的map任务分别从不同的偏移位置开始处理数据,等等的复杂一点的实现。 是否在MapReduce框架中已经存在对应的接口。
小结
MapReduce既是编程模型又是计算框架,尽管对于我们来说只需要实现map和reduce函数就能完成业务,但是前提是要对MapReduce编程框架的内部机制有清晰的概念。 总体来说,MapReduce最神奇的地方在于shuffle和sort,这是框架可以帮我们完成的。 反过来说,就是如何实现一个分布式的任务调度系统,并且要基于并行处理数据的编程模型来设计。
本文主要参考:
- 极客时间专栏 - 李智慧 - 从0开始学大数据
- Hadoop: The Definitive Guide, 4th Edition - Chapter2 - MapReduce















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









