







此实验在windows操作系统下进行的,使用IDEA编译运行
一、环境准备
二、具体流程图
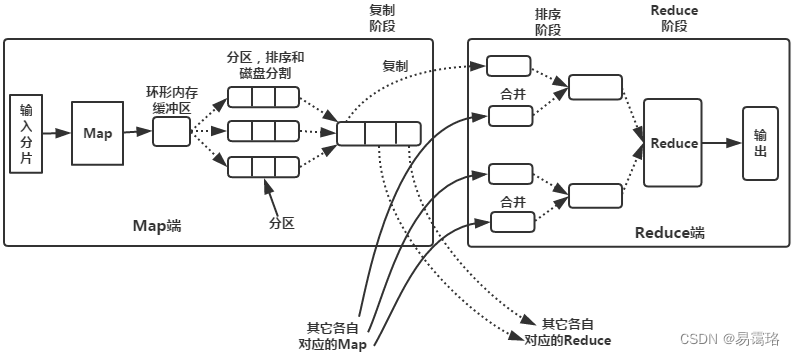
三、实现过程的完整代码
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author: 易霭珞
* @description 实现小文件的合并和数据去重操作
*/
public class Merge {
/**
*
* 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C
*/
//重载map函数,直接将输入中的value复制到输出数据的key上
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text text = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException{
text = value;
context.write(text, new Text(""));
}
}
//重载reduce函数,直接将输入中的key复制到输出数据的key上
public static class Reduce extends Reducer<Text, Text, Text, Text>{
public void reduce(Text key, Iterable<Text> values, Context context ) throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
//定义HDFS文件系统的用户(根据你的Hadoop用户而定)
System.setProperty("HADOOP_USER_NAME","hduser");
Configuration conf = new Configuration();
//定义HDFS文件系统的地址
conf.set("fs.default.name","hdfs://192.168.56.100:9000");
//定义Job实例对象以及任务名称
Job job = Job.getInstance(conf,"Merge and duplicate removal");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//定义需要合并和去重的数据文件夹
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.56.100:9000/user/hduser/input"));
//定义输出数据的文件路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.56.100:9000/user/hduser/input/out"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
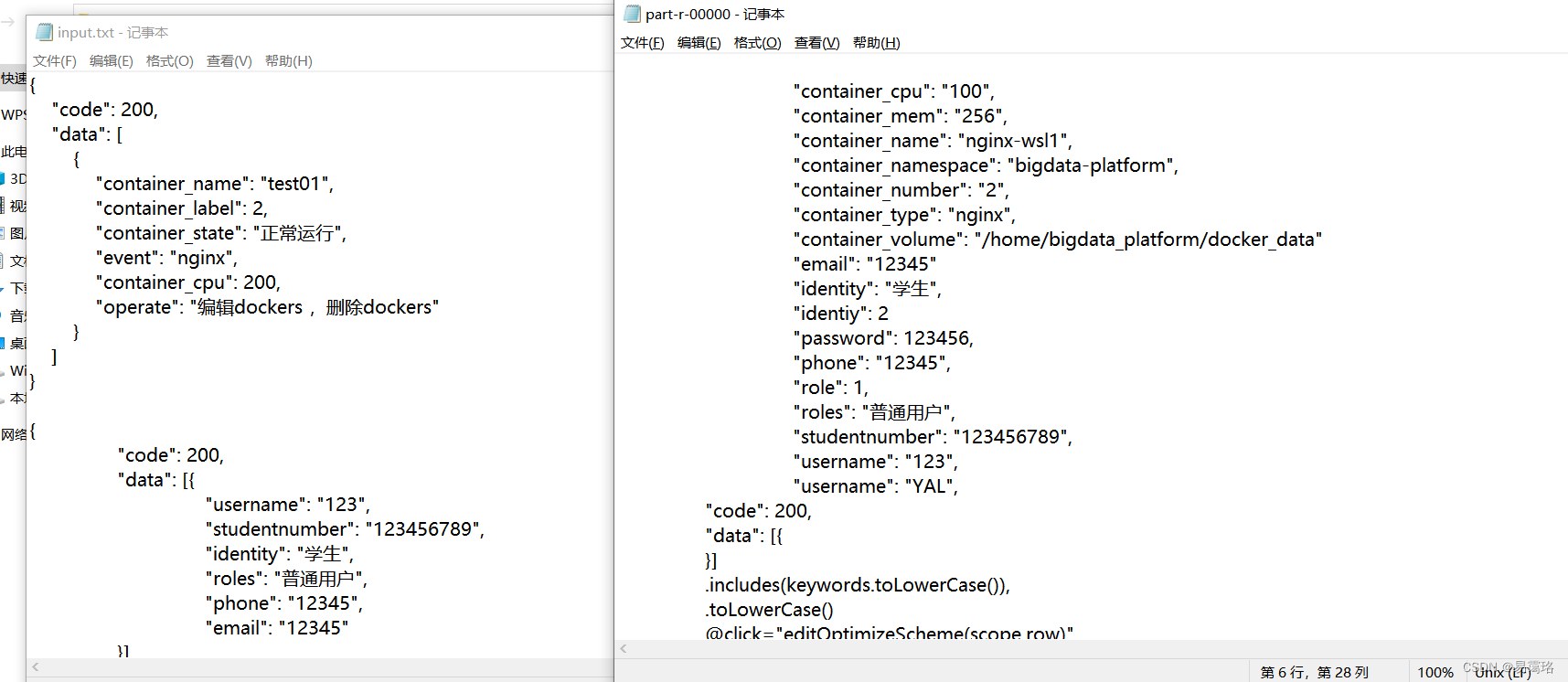
四、输出结果
运行前后的数据对比















 1644
1644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











