





红黑树为代表的各种二叉平衡搜索树可以实现插入和查找的渐进
哈希表(散列表):
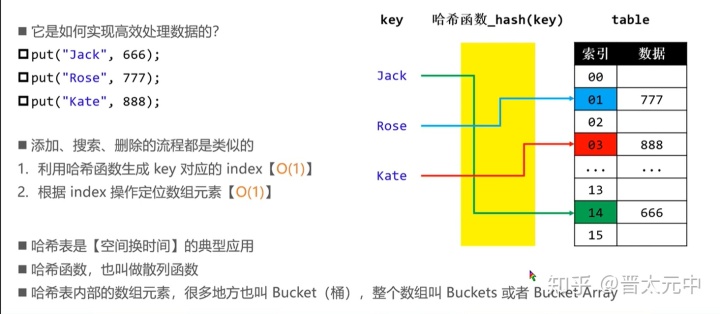
如上图,哈希表一般由若干个哈希函数和一个内部数组构成。
哈希函数:实现将输入的键值key(一个key对应一个需要存储的value),通过一定的算法转换为数组的索引值。
内部数组(桶数组):也成为buckets或buckets array,数组中的每一个元素称为bucket(桶),数组的大小一般设计为
由图可知哈希表实现平均的
哈希冲突:
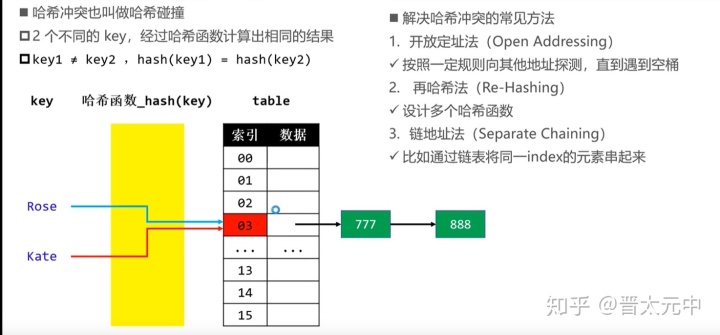

哈希冲突指的是不同的关键字通过哈希函数得到的索引有可能是一样的,这时就出现了不同关键字,但是索引值相同的情况。此时需要另外操作用来解决哈希冲突,我看的网课(以java实现的)只介绍了用在数据处用单链表或者红黑树(可以通过某些特定操作实现虽然key不能比较大小但是仍可以用红黑树存储)来存储重复的索引值对应的数据。节点较少时使用单链表而不是双向链表的原因主要是每次插入操作发现得到的索引非空时,一般是从该索引值处的链表第一个结点单向遍历进行查找是否已经存在要插入的key,如果已经存在,那么直接覆盖key对应的value,如果不存在,那么插入新的key-value对。
哈希函数:
哈希函数中所要做的主要有以下两步:
1.将传入的key转换为哈希码,哈希码一定是整数。
当传入的key就是整型int,可以直接将key作为哈希码
当传入的key是浮点型float,将浮点型在计算机内存储的二进制码对应的整型为哈希码
当传入的key是long(64位),将long与进行向右32位的无符号右移动的long取异或,最后强制转换为32位int哈希码。(我不清楚C++ 有没有这个限制,我所听的网课用的java限制哈希码只能是32位整型,所以这里直接照搬java处理方法,后边我用C++实现的时候也对应这个思路写一份代码)如下图。

当传入的key是字符串,则按照下图所述算法进行处理(之后我打算用C++实现一遍,我不清楚C++是否有这个性质,所以我到时在代码中手动实现

当传入的key是自己定义的结构,则需要自己设计一个产生哈希码的算法,设计原则如下

求得的哈希值尽量不要一样,这一就可以尽量避免哈希冲突,所以哈希表的插入,查找,访问等操作的平均时间效率就会高。两个对象如果求得的哈希码一样,这不代表两个对象就是一样的,两个对象是否一样取决于equal函数的返回结果,也就是取决于设计设个equal函数的人判断两个对象一样的标准。
2.将哈希码与内部数组大小作位运算,得到数组索引值(得到的数组索引值一定是小于等于数组大小-1)。
这一步就只有这一行代码,这一段代码相当于hashcode % (table.size() - 1),但因为是位运算所以效率高很多。
return hashcode & (table.size() - 1);//hashcode为第一步得到的哈希值
对于这段代码的理解:
因为数组的大小被设定为了

将其与任意一个数进行与运算,所得到的数都是小于等于
由以上讨论,我们可以得知我们不用担心获得哈希码时哈希码太大导致int越界的问题,因为我们只是想得到一个整数,而不是要求整数具体要等于多少。
用哈希表实现简易的Map:(部分内存管理细节省略,key类型唯一,value类型唯一,不完整,仅仅体现思路)
公共接口:
//假设K是自定义类型(内置类型我还不知道怎么像java一样直接用成员函数返回哈希值)
//要求K中具有有一个bool成员iscompare,如果为true则可以比较大小,如果为false则不可以比较大小
//如果K中iscompare为true,则必须提供一个成员函数compare来比较两个对象的大小
//k1.compare(k2) 返回1则k1>k2,返回-1则k1<k2,返回0则k1大小等于k2(不一定是同一对象,只是大小相同)
//要求K的实现中具有equal函数来规定什么情况下认为两个K对象可以当作是同一个
template <typename K, typename V>
struct Node//HashMap所要存储的key-value结构,将要存储在红黑树结构中
{
int hash = 0;//哈希值,默认取0
bool color = 1;//红黑树新节点默认为Red
Node<K, V>* lc = nullptr;
Node<K, V>* rc = nullptr;
Node<K, V>* parent = nullptr;
K key;
V value;
Node(K key, V value, Node<K, V>* _parent):key(key), value(value)
{
hash = key == nullptr? 0:key.hashcode();//如果非空则调用自定义类型的成员函数返回哈希值,如果为空则置0
parent = _parent;
}
//以下都是红黑树结点的各种操作函数
bool hasTwoChildren()
{
return this->lc && this->rc
}
bool isLeftChildren()
{
return this->parent && this == this->parent->lc;
}
bool isRightChildren()
{
return this->parent && this == this->parent->rc;
}
Node<K, V>* sibling()//返回兄弟节点
{
if(isLeftChildren())
return this->parent->rc;
if(isRightChildren())
return this->parent->lc;
return nullptr;
}
};
class HashMap
{
public:
HashMap(){};//默认构造函数
void clean();
void put(const K& key, const V& value);
V* get(const K& key);
bool remove(const K& key);
bool containValue(const V& value);
bool resize();//扩容操作
int index(const K& key)
{
return (key.hashcode()) & (table.size() - 1);
}
private:
int size = 16;//size一般取2的n次方,size为数组容量长度
int used_size = 0;//数组包含的Node数量
vector<Node*> table (size);//数组默认长度取16
void moveNode(Node<K, V>* p);//移动节点函数,用来辅助扩容操作
Node<K, V>* search(Node<K, V>* p, const K& key)//辅助查找函数
{ //在p为根节点的红黑树中递归查找是否存在key
if(!p)
return nullptr;
if(key.equal(p->key))
return p;
search(p->lc, key)
search(p->rc, key)
return nullptr;
}
//假设以下包含了红黑树的各种操作函数,比如插入后修复函数,删除后修复函数等等
clean()实现:
void HashMap::clean()
{
if(!used_size)//数组包含的非空元素数量为0
return;
for(int i = 0; i < size; i++)
{
table[i] = nullptr;
{释放i对应数组位置的红黑树}
}
used_size = 0;
}
put(K key, V value)实现:
//向HshMap中插入由传入参数指定的key-value对
//红黑树的向左向右由
//如果已经存在相同的key,则直接覆盖value
//否则就是插入新的key-value对
template <typename K, typename V>
bool HashMap::put(const K& key, const V& value)
{
int index = index(key)
bool search = false;//遍历搜索标志,如果已经递归遍历过所有红黑树结点则为true
Node<K, V>* root = table[index];
if(!root)//如果索引处为nullptr,则直接插入即可
{
root = new Node<K, V>(key, value, nullptr);
table[index] = root;
used_size++;
after_insert(root);//调用插入后修复红黑树性质函数
}
//root如果不为空,先检查是否已经存在相同的key
int h1 = key.hashcode();
int cmp = 0;//红黑树搜索方向标志,cmp = -1向左,cmp = 1向右,cmp = 0说明就是相等,应该覆盖
Node<K, V>* p = root;//辅助指针,如果不存在重复key那么p指向应该插入的位置的父亲
while(root)
{
p = root;
int h2 = root->key.hashcode();//获取当前节点key的哈希值
if(h1 > h2)
cmp = 1;
if(h1 < h2)
cmp = -1;
//如果发现哈希值相同(哈希值相同还不足以说明就是要找的key),首先尝试能否通过K本身就是可比较的函数继续决定向左向右搜索红黑树
if(h1 == h2)
{
if(key.iscompare && key.compare(root->key != 0)//K是可比较大小的类型
{
if(key.compare(root->key) == 1)//key > p->key
cmp = 1;
if(key.compare(root->key == -1))//key < p->key
cmp = -1;
}
else//如果K是不可以比较大小的类型或者大小相同,还得进一步判断是否是同一key
if(search)//如果已经遍历过了还能来到这里,那么就说明肯定已经不存在了,直接默认向右即可
cmp = 1;
else
{
//因为无法比较大小,此时只能递归遍历去查找是否已经有key存在了
Node<K, V>* result = search(root, key);
if(result)//如果找到,说明key存在
{
cmp = 0;
root = result;
}
search = 1;//已经搜索过了,如果能来到这里说明key不存在,交给下一轮循环进行了
}
}
if(cmp == 1)
root = root -> rc;
if(cmp == -1)
root = root -> lc;
if(cmp == 0)//是同一个key,直接覆盖value即可
{
root->value = value;
return false;//插入失败,直接覆盖了原来key的value
}
}
//如果能来到这里,说明确实不存在了,可以根据cmp指定的位置插入新的key-value对了
Node<K, V>* temp = new Node<K, V>(key, value, p);
if(cmp == 1)
{
p->rc = temp;
after_insert(p->rc)//调用插入后修复红黑树性质函数
}
if(cmp == -1)
{
p->lc = temp;
after_insert(p->lc)//调用插入后修复红黑树性质函数
}
used_size++;
return true;//插入成功
}
get(K key)的实现:
//get根据key找到对应的Value并返回指向V指针,如果不存在key则返回空指针
template <typename K, typename V>
V* HashMap::get(const K& key)
{
int index = index(key);//获得索引
Node<K, V>* root = table[index];
if(!root)//如果root是空
return nullptr;
int h1 = key.hashcode();//获取待查找key的哈希值
while(root)
{
int h2 = root->key.hashcode();//获取当前节点key的哈希值
if(h1 > h2)
cmp = 1;
if(h1 < h2)
cmp = -1;
//如果发现哈希值相同(哈希值相同还不足以说明就是要找的key),首先尝试能否通过K本身就是可比较的函数继续决定向左向右搜索红黑树
if(h1 == h2)
{
if(key.iscompare && key.compare(root->key != 0)//K是可比较大小的类型
{
if(key.compare(root->key) == 1)//key > p->key
cmp = 1;
if(key.compare(root->key == -1))//key < p->key
cmp = -1;
}
else//如果K是不可以比较大小的类型或者大小相同,还得进一步判断是否是同一key
if(search)//如果已经遍历过了还能来到这里,那么就说明肯定已经不存在了,直接默认向右插入即可
cmp = 1;
else
{
//因为无法比较大小,此时只能递归遍历去查找是否已经有key存在了
Node<K, V>* result = search(root, key);
if(result)//如果找到,说明key存在
{
cmp = 0;
root = result;
}
search = 1;//已经搜索过了,如果能来到这里说明key不存在,交给下一轮循环进行了
}
}
if(cmp == 1)
root = root -> rc;
if(cmp == -1)
root = root -> lc;
if(cmp == 0)//是同一个key,直接退出循环
break;
}
if(root)
return &root->value;/退出循环后要么找到了,此时root不是空,要么没找到,此时root是空
else
return nullptr;
}
remove(const K& key):的实现
//删除Map中存在的由key指定的key-value对
//删除成功返回true,反之返回false
template <typename K, typename V>
bool remove(const K& key)
{
int index = index(key);//获得索引
Node<K, V>* root = table[index];
if(!root)//如果root是空,则删除失败
return false;
while(root)
{
int h2 = root->key.hashcode();//获取当前节点key的哈希值
if(h1 > h2)
cmp = 1;
if(h1 < h2)
cmp = -1;
//如果发现哈希值相同(哈希值相同还不足以说明就是要找的key),首先尝试能否通过K本身就是可比较的函数继续决定向左向右搜索红黑树
if(h1 == h2)
{
if(key.iscompare && key.compare(root->key != 0)//K是可比较大小的类型
{
if(key.compare(root->key) == 1)//key > p->key
cmp = 1;
if(key.compare(root->key == -1))//key < p->key
cmp = -1;
}
else//如果K是不可以比较大小的类型或者大小相同,还得进一步判断是否是同一key
if(search)//如果已经遍历过了还能来到这里,那么就说明肯定已经不存在了,直接默认向右插入即可
cmp = 1;
else
{
//因为无法比较大小,此时只能递归遍历去查找是否已经有key存在了
Node<K, V>* result = search(root, key);
if(result)//如果找到,说明key存在
{
cmp = 0;
root = result;
}
search = 1;//已经搜索过了,如果能来到这里说明key不存在,交给下一轮循环进行了
}
}
if(cmp == 1)
root = root -> rc;
if(cmp == -1)
root = root -> lc;
if(cmp == 0)//找到key,直接退出循环
break;
}
if(!root)//如果不存在key,则删除失败
return false;
else
{
{删除root指向的红黑树结点的函数}
{红黑树的删除后的处理函数}
return true;
}
}
containsValue(const V& value)的实现:
//检测哈希表中是否存在value这个值
//对于value哈希表没有太好的解决办法,只能是对table中每个位置的红黑树依次进行层序遍历
//这个操作时间效率最低,为O(n)
template <typename K, typename V>
bool HashMap::containsValue(const V& value)
{
queue<Node<K, V>*> temp = {};//辅助队列
for(int i = 0; i < size; i++)
{
temp.push(table[i]);
while(!temp.isempty())
{
Node<K, V>* p = temp.front();
temp.pop();
if(p)
{
if(value == p->value)
return true;
temp.push(p->lc);
temp.push(p->rc);
}
}
}
return false;
}
moveNode()以及resize()操作的实现:
//当装填因子: used_size/size 的值大于0.75,就说明此时哈希表中哈希冲突现象比较严重
//此时扩容操作对哈希表的结点进行重新排布,扩容一般是将size扩大为为原来两倍
//由于数组索引index是由 哈希码&(size-1) 获得,所以扩容后的索引要么和原来一样还是index
//要么就扩大为index + 扩容前的size,所以可以缓解哈希冲突
//整体思路是生成一个扩容后的数组,对旧数组进行层序遍历一个个得将结点重新按照哈希表的插入规则插入新的数组中
//虽然扩容以及移动操作需要O(n)时间效率,但是从平均的意义上看,可以有效改善哈希表的时间效率
template <typename K, typename V>
bool HashMap::resize()
{
if(static_cast<double>(used_size/size) < 0.75)
return false;//装填因子不够大,不需要扩容
vector<Node<K, V>*>* old_table = table;
int old_size = size;
size = 2*size;
table = new vector<Node<K, V>*>(size);//扩容后的新数组
queue<Node<K, V>*> temp = {};//辅助队列
for(int i = 0; i < old_size; i++)
{
temp.push(old[i]);
while(!temp.isempty())
{
Node<K, V>* p = temp.front();
temp.pop();
if(p)
{
moveNode(p);
temp.push(p->lc);
temp.push(p->rc);
}
}
}
}
template <typename K, typename V>
void HashMap::moveNode(Node<K, V>* x)
{
//将x所指的结点视作要插入数组的新节点,所以一切都要重置
x->lc = nullptr;
x->rc = nullptr;
x->parent = nullptr;
x->color = 1;//红黑树新插入结点默认为红
int index = index(key)
Node<K, V>* root = table[index];
if(!root)//如果索引处为nullptr,则直接插入即可
{
root = x;
table[index] = root;
used_size++;
after_insert(root);//调用插入后修复红黑树性质函数
}
//root如果不为空,先检查是否已经存在相同的key
int h1 = key.hashcode();
int cmp = 0;//红黑树搜索方向标志,cmp = -1向左,cmp = 1向右.
Node<K, V>* p = root;//辅助指针,如果不存在重复key那么p指向应该插入的位置的父亲
while(root)
{
p = root;
int h2 = root->key.hashcode();//获取当前节点key的哈希值
if(h1 > h2)
cmp = 1;
if(h1 < h2)
cmp = -1;
//如果发现哈希值相同(哈希值相同还不足以说明就是要找的key),首先尝试能否通过K本身就是可比较的函数继续决定向左向右搜索红黑树
if(h1 == h2)
{
if(key.iscompare && key.compare(root->key != 0)//K是可比较大小的类型
{
if(key.compare(root->key) == 1)//key > p->key
cmp = 1;
if(key.compare(root->key == -1))//key < p->key
cmp = -1;
}
else//如果K是不可以比较大小的类型或者大小相同,直接默认向右,因为这里是移动操作,不可能有相同的key
cmp = 1;
}
if(cmp == 1)
root = root -> rc;
if(cmp == -1)
root = root -> lc;
}
//到达了可以插入新键值对的地方
if(cmp == 1)
{
p->rc = x;
after_insert(p->rc)//调用插入后修复红黑树性质函数
}
if(cmp == -1)
{
p->lc = x;
after_insert(p->lc)//调用插入后修复红黑树性质函数
}
}















 2894
2894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









