






本篇文章主要介绍推荐的一些常见的算法,重在原理的理解,减少了算法公式的推导以及繁杂的解释,由于篇幅较长,本文分上和下两篇,大家可循序渐进,没必要马上理解里面的原理。
推荐的诞生
互联网的普及带来了信息量的爆炸增长,用户需要花费更多时间才能获得真正有用的信息,信息的增长对信息的使用效率反而降低了,这就是所谓的信息超载(informationoverload)问题。
解决信息超载问题一个最有潜力的办法是推荐系统,它建立在海量的数据挖掘基础之上,通过用户的行为,预估出用户的偏好,将商品与用户偏好匹配以后,向用户推荐商品或服务。
和搜索引擎相比,系统能发现用户的潜在需求,并能引导用户发现自需求,能让用户觉得你很懂她;一个好的推荐系统能为用户提供个性化的服务,还能和用户之间建立密切关系,让用户对推荐产生依赖。
推荐系统组成
推荐系统一般由几个层次构成,由下至上分别是数据层、离线算法层、在线算法层、策略层;
离线算法层包括召回层,排序层,重排层;
数据层包括用户数据和物料数据;
为推荐系统服务的一般还有以下一些平台:
推荐网关:负责合法性检查,请求分发,在线Debug等;
分流系统:为推荐服务进行流量分发,为推荐实验分流;或者对新的模型新进分支实验;以及设置应急预案等;分流形式有独占和分层分流两种;
标注平台:为模型提供人工标注的数据
画像平台:将用户和用户行为,物品的特征整理成标签,推荐时用来做特征匹配;
用户画像包括一些长期兴趣,短期兴趣,实时兴趣;品牌偏好,购买力,颜色,尺码,促销敏感度,家庭情况,个人基本信息等
物料画像主要包括商品品类,商品关键词,品牌词,质量,价格区间,用户年龄层,适用性别等
用户行为,包括搜索,点击,浏览,订阅,加入购物车,下单,退货,资讯等
预测系统:根据用户的历史行为,用机器学习模型,来增加或减少召回候选集的权重
主要算法
我这里就主要讲我们公司自己用得较多的算法,像一些公司算法自己建立的推荐算法就不做展开了,每个公司算法团队的技术不同,实际可能会有差别;
1.New hot
有的公司叫热度算法,根据用户的浏览行为,以及物品本身的属性来为新闻,商品等进行打分,进行推荐;

S0是物品或新闻本身的初始热度,可按物品种类,属性来打分,如重大事件,就会给更高的分数,通过热词匹配或者对头条新闻的爬取赋予高权重,就能让重要新闻或物品的S0有一个较高分数;
S(Users)是用户行为产生的得分,这里初步列了点击,喜爱,评论,分享,如果是电商还有购买,加入购物车等,针对不同行为会给予一个不同的权重,想分享和评论的权重分就会高一些;
S(Time)是时间衰减得分,时间衰减曲线如下,不是一条直线,而是随着时间的流逝,衰减得越来越快;一般的新闻失效性为一天,重大新闻也不会超过3天;T1是当前时间,T0是新闻入库时间
新闻的热度衰减曲线大致如下
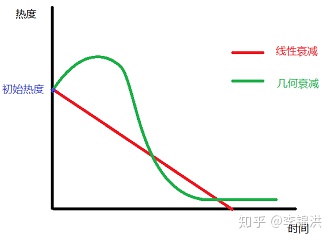
也有一些品类除外,如历史纪实,军事,百科,养生等,可以不遵循这个衰减公式
2.基于内容的相关推荐CB
里面的逻辑很简单就是不管用户是什么样的,直接通过物品的特征向量,计算物品或文章之间的相关性,在用户浏览某篇文章或商品时,一般就出现在文章末尾的推荐,或者是相似商品页。
相关推荐一般先通过自己公司维护的词库,对推荐的文章或商品内容进行分词,词库的词一般是通过标注平台新增或者是用第三方的词库进行分词;在分词计算向量相似度的时候,会出现一个问题,就是两篇文章关键词大部分一样,但是表达的意思是不同的;这里要用到TF-IDF模型,目的是过滤掉常见的词语,保留重要词语。
TF-IDF=TFij * IDFi
TF是每个关键词在文中的频率
IDF是关键词在所有文档中出现频率的相反值,也叫逆文本指数;为啥要取相反值?因为对区文档最有意义的词语,应该是那些在文档中出现的频率高,但在整个文档集合中出现频率少的词语;
在经过分词和特征处理以后,就可以用表示每件商品或文章的向量了;一般是关键词和tfidf的值
然后再通过距离公式计算相似度,就能进行相关推荐了;这里距离公式有欧式距离,曼哈顿距离,余弦相似度等;
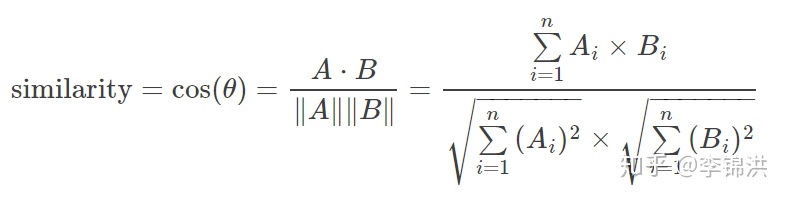
余弦相似度基本上是最常用的,在计算文本相似度效果很好,一般像tf-idf一下然后计算,推荐中在协同过滤以及很多算法中都比其他相似度效果理想。
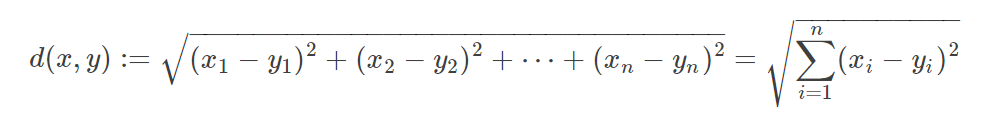
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。
3.猜你喜欢
在计算出物品的相关度后,如果还想要再进一步,对用户进行个性化荐,就需要计算用户的特征;
用户在app或网站上有阅读,点赞,评论,购买,收藏等行为,根据用户的这一系列行为,生成行为权重向量,(该项量包含用户一系列行为特征)再与新闻或物品的特征向量相乘后获得用户特征分,并生成用户标签;用户在app里使用时间越久,画像标签就越精准,越全面;在有新的新闻或物品入库后,与用户的匹配度就越高,推荐就越精准。大家最常见的猜你喜欢就是通过这个过程计算出来的。
这篇就先介绍到这里,上面所介绍的算法已经能满足大小公司做个性化推荐的需求,如果还想进一步把推荐做得更加有特色,更精准,更懂用户,那么在下一篇讲协同过滤,隐语义模型,以及发现性推荐算法的文章也许能满足你的要求。















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









