






? 工欲善其事,必先利其器。
算法分析
- 有关算法的时间耗费分析,称之为算法的时间复杂度分析
- 有关算法的空间耗费分析,称之为算法的空间复杂度分析
算法的时间复杂度分析
要计算算法时间的耗费情况,首先就得度量算法的执行时间,那么如何度量呢??
事后分析估算法
比较容易想到的方法就是我们先把算法执行起来,然后进行计时 ⏲。这种方式看上去的确不错,但是需要我们自己手动去计时,而且现在编辑器上几乎都带有代码执行时间,并且不止计时,还可以分析执行效率,cpu 占用等等。
但是这种方式主要是通过提前设置好的测试数据和测试程序,利用计算机自动化对不同的算法程序进行时间比较,从而确定算法效率的高低,但是这种方法是有很大的缺陷的;必须依靠测试数据和测试程序进行,而测试程序通常需要耗费大量精力进行编写,并且当测试程序编写完成后,如果发现算法具有很大的问题,则之前编写测试程序的工作就相当于白费。而且除了算法的不确定性外,还有硬件导致的各种问题,不同设备下,不同 cpu 下,程序运行的时间则不一样。
所以通过测试程序和测试数据进行的测试没法统一的估算算法耗费情况,具有很大的问题。
public static void main(String[] args) {
long start = System.currentTimeMillis();
int sum = 0;
int n=100;
for (int i = 1; i <= n; i++) {
sum += i;
}
System.out.println("sum=" + sum);
long end = System.currentTimeMillis();
System.out.println(end-start);
}
事前分析估算法
有了事后分析估算法,那么就有事前分析估算法。
在计算机程序编写前,依据传统统计方式,经过总结,发现一个高级语言编写的程序应用在计算机上运行的消耗取决于以下因素:
- 采用的算法方案
- 书写的代码质量
- 数据规模
- 机器执行的快慢(硬件的配置高低)
由上面因素可见,抛弃了和计算机硬件、软件有关的因素后,只剩下采用的算法方案和数据规模。
如果算法方案已经确定,那么就只剩下了数据规模。
比如在概述章节里面,算法初体验中的一个需求,如果将计算 1-1000 改为计算 1-1 亿甚至更多。
第一种解法:
var sum = 0;
// n 代表无限个数值
var n = n;
for (let i = 1; i <= n; i++) {
sum += i;
}
console.log(sum);
第二种解法:
var sum = 0;
// n 代表无限个数值
var n = n;
// 高斯公式求和
sum = ((n + 1) * n) / 2;
console.log(sum);
当输入数据规模很大时,第一种算法执行了 1 + 1 + (n + 1) +n = 2n +3次,第二种执行了 1+1+1=3次。如果我们把第一种算法的循环看做一个整体,忽略掉循环条件结束的判断,那么这两个算法运行次数差就是 n 和 1 的差别。
假设每行执行时间一致,则两种算法的时间差就是 n 和 1 的差别。在 n 无穷大时,是可以忽略掉 n 的系数和常量。
比如下面的这张图:
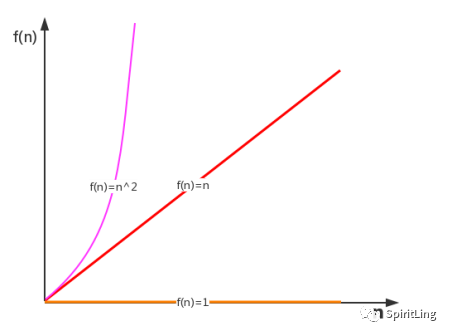
函数渐进增长
关于函数渐进增长,内容过多,这边不予展示说明(后续也有可能单独出一期)。其内容可以直接google搜索即可。
大 O 记法
算法的执行效率 ≈ 算法的执行时间 ≈ 执行次数
在算法分析时,语句总的执行次数是关于问题规模 n 的函数,由此可以看出,所有代码的执行时间 T(n) 与每行代码的执行次数成正比。
所以推出公式为 T(n) = O(f(n)),其中 T(n) 表示代码执行的时间;n 表示数据规模大小,f(n) 表示每行代码执行的次数总和。
所以上面的例子可以写成 T(n) = O(2n+3)。这就是 大 O 时间复杂度表示。大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
通过函数渐进增长来说,当 n 很大时,公式中的低阶、常量、系数三部分并不左右增长趋势,所以都可以忽略。只需要记住一个最大量级即可,如果用大 O 表示上面例子中的时间复杂度则为:O(n) 和 O(1)。
不含任何和量级有关的循环代码,复杂度始终为 O(1)
var sum = 0;
// n 代表无限个数值
var n = n;
// 高斯公式求和
sum = ((n + 1) * n) / 2;
console.log(sum);
上面代码中不存在循环,则所有都是执行一次,在合并时间复杂度时,可以使用常数 1 取代运行代码中的所有加法常数。
而且如果存在循环,但是循环和量级 n 无关,则也记为 1。
T(n) = O(1 + 1 +1) = O(3) = O(1)
只计算循环执行次数最多的一段代码
public int Main(int n){
int sum = 0;
for(int i=0;i sum = sum + i;
}
return sum;
}
上面代码中,赋值等都属于常量级操作,都可以设置为 1;而只有 for 循环是与量级 n 有关的,所以整个代码的时间复杂度就是:
T(n) = O(1 + n) = O(n)
最终结果就是 O(n)
总复杂度等于量级最大的那段代码复杂度(只保留最高阶项)
int cal(int n) {
int sum_1 = 0;
int p = 1;
for (; p 100; ++p) {
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
for (; q sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}
这个代码分为三部分,分别是求 sum_1、sum_2、sum_3。可以分别分析每一部分的时间复杂度,然后把它们放到一块儿,再取一个量级最大的作为整段代码的复杂度。
sum_1 时间复杂度根据上面的判断:O(n)
sum_2 时间复杂度根据上面的判断:O(n)
sum_3 时间复杂度根据上面的判断:O(n^2)
T(n) = T1(n) +T2(n) +T3(n) = max(O(n)+O(n)+O(n^2)) = O(max(n + n + n^2)) = O(n^2)
也就是说:总的时间复杂度就等于量级最大的那段代码的时间复杂度。
嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
int cal(int n) {
int ret = 0;
int i = 1;
for (; i ret = ret + f(i);
}
}
int f(int n) {
int sum = 0;
int i = 1;
for (; i sum = sum + i;
}
return sum;
}
上面的最大代码复杂度是通过加法计算的,而嵌套代码复杂度是通过乘法进行的,通过上面的最终公式,可以同样推出乘积的公式:如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)*T2(n)=O(f(n))*O(g(n))=O(f(n)*g(n))
所以上面代码的复杂度就是 T(n) = O(n^2)
常见的时间复杂度
| 名称 | 增长的数量级 | 说明 | 举例 |
|---|---|---|---|
| 常量阶 | O(1) | 普通语句 | 两数相加,赋值 |
| 对数阶 | O(logn) | 二分策略 | 二分查找 |
| 线性阶 | O(n) | 循环 | 找出最大元素 |
| 线性对数阶 | O(nlogn) | 分治思想 | 归并排序 |
| 平方阶 | O(n^2) | 双层循环 | 检查所有元素对 |
| k 方阶 | O(n^k) | 多层循环 | 检查所有多元组 |
| 指数阶 | O(2^n) | 穷举查找 | 检查所有的子集 |
| 阶乘阶 | O(n!) | --- | --- |
对于上面表格中的复杂度量级,可以粗略分为:多项式量级和非多项式量级。
其中多项式量级只有:指数和阶乘阶
O(1)
通过上面的代码和例子,首先必须明确一个定义,O(1) 只是常量级时间复杂度的一种表示方法,并不是指执行一行代码。
var i = 10;
var j = 100;
var sum = i + j;
只要代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1)。或者说,一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是 Ο(1)。
O(logn)、O(nlogn)
对数阶时间复杂度非常常见,同时也是最难分析的一种时间复杂度。
var i = 1;
while (i <= n) {
i = i * 2;
}
根据上面的复杂度计算方式,分析这个代码段,发现 while 循环中的这行代码执行次数最多,执行次数约等于执行时间。所以,只要知道这行代码就可以知道整段代码的时间复杂度。
从代码中可以看出,变量 i 的值从 1 开始取,每循环一次就乘以 2 。当大于 n 时,循环结束。
1 1*2=2 1*2*2=4 1*2*2*2=8 ......
由上面可以写成 2^0 2^1 2^2 2^3 ……
可以看到上面实际上一个等比数列。所以实际就是求 2^x = n 。求解 x 值,x = log2n,所以这段代码的时间复杂度就是 O(log2n)。
现在将上面代码稍微修改下
var i = 1;
while (i <= n) {
i = i * 2;
}
和上面一样的计算方式,它的时间复杂度是:O(log3n) 。
实际上,不论对数是以 2 为底,还是以 3 为底,我们都可以把对数阶的时间复杂度记为 O(logn)。为什么呢??
因为对数之间是可以相互转换的,log3n 就等于 log23 * log2n,所以 O(log3n) = O(C * log2n),其中 C = log23 是一个常量。基于前面的理论:**在采用大 O 标记复杂度时可以忽略系数,即 O(Cf(n)) = O(f(n))。**因此,在对数阶时间复杂度的表示方法里,一般忽略掉对数的“底”,统一表示为 O(logn)。
O(m+n)、O(m*n)
前面所涉及到的复杂度计算都是基于一个数据规模的,有一就有二,现在看一个,由两个数据规模来决定。
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}
从代码中可以看到, m 和 n 是表示两个数据规模。我们无法事先评估 m 和 n 谁的量级大,所以在计算时间复杂度时,就不能简单的利用前面的规则来处理。只计算循环执行次数最多的一段代码就不可以之间使用,所以结果复杂度为:O(n+m)
但是如果嵌套起来,总复杂度量级等于嵌套的内外代码复杂度的乘积,所以依旧可以使用这个规则,复杂度就是:O(m*2)
算法的空间复杂度分析
前面花了很长时间讲大 O 表示法和时间复杂度分析,接下来就是空间复杂度分析。
前面说过,时间复杂度就是渐进时间复杂度,表示算法的执行时间与数据规模之间的增长关系,类比一下,空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
通过下面例子来说明
void print(int n) {
int i = 0;
int[] a = new int[n];
for (i; i a[i] = i * i;
}
for (i = n-1; i >= 0; --i) {
print out a[i]
}
}
一般来说,没人会这么写的。
跟时间复杂度分析一样,可以看到 a 变量申请了一个大小为 n 的空间。除此之外,其他代码都没有占用更多的空间,所以整段代码的空间复杂度就是 O(n)。
常见的空间复杂度就是:O(1)、O(n)、O(n^2),像 O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到,而且,空间复杂度比时间复杂度分析更加简单。
浅析最好、最坏、平均、均摊时间复杂度
- 最好情况时间复杂度(best case time complexity)
- 最坏情况时间复杂度(worst case time complexity)
- 平均情况时间复杂度(average case time complexity)
- 均摊时间复杂度(amortized time complexity)
最好、最坏情况时间复杂度
上面的复杂度分析都是非常简单的,下面的代码来一个稍微复杂的。
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i if (array[i] == x) pos = i;
}
return pos;
}
这段代码要实现的功能是,在一个无序的数组(array)中,查找变量 x 出现的位置。如果没有找到,就返回 -1。按照上面讲的分析方法,这段代码的复杂度是 O(n),其中,n 代表数组的长度。
但是一般在写代码中,并不是都需要将数组循环一遍,当我们找到我们需要的元素时,我们可以提前结束本次循环。所以这段代码写的不够高效,我们可以这样优化下:
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
现在优化完成后,它的时间复杂度还是 O(n)吗?
要查找的变量 x 有可能出现在数组的任意位置。如果要查找的 x 元素正好在第一个位置,那就不需要遍历剩下的数据,那时间复杂度就是 O(1)。但是如果变量 x 不在数组中 hu,那我们需要遍历整个数组,时间复杂度就成了 O(n)。所以,不同情况下,代码的时间复杂度是不一样的,这就需要其他的概念来解释。
? 最好情况时间复杂度:在最理想状态下,执行这段代码的时间复杂度
在最理想的情况下,要查找的变量 x 正好是数组的第一个元素,这个时候对应的时间复杂度就是最好情况时间复杂度。
? 最坏情况时间复杂度:在最糟糕情况下,执行这段代码的时间复杂度
如果数组中没有要查找的变量 x,我们需要把整个数组都遍历一遍才行,所以这种最糟糕情况下对应的时间复杂度就是最坏情况时间复杂度。
平均情况时间复杂度
最好和最坏情况时间复杂度对应的都是极端情况下的代码时间复杂度,发生的概率不大。为了更好的表示平均情况下的复杂度,需要引入新的概念:平均情况时间复杂度,简称平均时间复杂度。
以上面的例子进行在分析。
要查找的变量 x 在数组的位置,有 n+1 种的情况:在数组的 0 ~ n-1 位置(总共 n 种)和不在数组中。我们把每种情况下,查找需要遍历的元素个数累加起来,然后再除以 n+1,就可以得到需要遍历的元素个数的平均值,即:
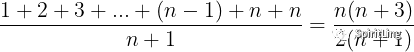
公式源码:\frac{1+2+3+...+(n-1)+n+n}{n+1} = \frac{n(n+3)}{2(n+1)}
在大 O 标记法中,可以省略掉系数、低阶、常量,所以对上面的结果进行简化后,得到平均时间复杂度就是 O(n)。
这个结论虽然是对的,但是计算过程稍微有点问题。上面的 n+1 种情况并不是每个情况概率相同。
查找的变量 x ,要么在数组里,要么不在数据里。这两种情况对于的概率统计起来很麻烦,为了方便起见,假设在数组中和不在数组中的概率都为 1/2。另外,要查找的数据出现在 0 ~ n-1 这 n 个位置的概率也是一样的,为 1/n 。所以,根据概率乘法法则,要查找的数据出现在 0 ~ n-1 中任意位置的概率就是 1/(2n)。
因此,前面的推导过程中存在的最大问题就是,没有将各种情况发生的概率考虑进去。如果把每种情况发生的概率也考虑进去,那平均时间复杂度的计算过程就变成了这样:
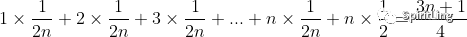
公式源码:1\times\frac{1}{2n}+2\times\frac{1}{2n}+\cdots+n\times\frac{1}{2n}+n\times\frac{1}{2} = \frac{3n+1}{4}
这个值就是概率论中的加权平均值,也叫作期望值,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
引入概率之后,得到新的平均值。用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍是 O(n)。
很多时候,我们使用一个复杂度就可以满足需求了。只有同一块代码在不同的情况下,时间复杂度有量级的差距,才会使用这三种复杂度来表示。
均摊时间复杂度
到目前截至,已经讲解了算法分析大部分内容了,几乎可以使用起来。但是还有一个更高级的概念,均摊时间复杂度,以及它对应的分析方法,摊还分析(或者叫平摊分析)。
均摊时间复杂度,听起来跟平均时间复杂度有点儿像。对于我来说,刚学习到这里时,对这两个概念经常容易混淆。所以均摊时间复杂度比平均时间复杂度更加特殊、更加有限。
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
这段代码实现了一个往数组中插入数据的功能。当数组满了之后,也就是代码中的 count == array.length 时,我们用 for 循环遍历数组求和,并清空数组,将求和之后的 sum 值放到数组的第一个位置,然后再将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组。
- 最理想情况下:数组中全是空闲空间,我们只需要将数据插入到数组下标为 count 的位置就可以了,所以最好情况时间复杂度为 O(1) 。
- 最坏的情况下:数组中没有空闲空间了,我们需要先做一次数组的遍历求和,然后再将数据插入,所以最坏情况时间复杂度为 O(n)。
- 平均时间复杂度:O(1)。
假设数组的长度是 n,根据数据插入的位置的不同,我们可以分为 n 种情况,每种情况的时间复杂度是 O(1)。除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,这个时候的时间复杂度是 O(n)。而且,这 n+1 种情况发生的概率一样,都是 1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度就是:
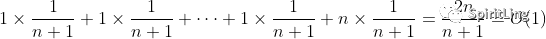
公式源码:1\times\frac{1}{n+1}+1\times\frac{1}{n+1}+\cdots+1\times\frac{1}{n+1}+n\times\frac{1}{n+1} = \frac{2n}{n+1} = O(1)
首先,find() 函数在极端情况下,复杂度才为 O(1)。但 insert() 在大部分情况下,时间复杂度都为 O(1)。只有个别情况下,复杂度才比较高,为 O(n)。这是 insert()第一个区别于 find() 的地方。
第二个不同的地方。对于 insert() 函数来说,O(1) 时间复杂度的插入和 O(n) 时间复杂度的插入,出现的频率是非常有规律的,而且有一定的前后时序关系,一般都是一个 O(n) 插入之后,紧跟着 n-1 个 O(1) 的插入操作,循环往复。
针对这种特殊的场景,我们引入了一种更加简单的分析方法:摊还分析法,通过摊还分析得到的时间复杂度我们起了一个名字,叫? 均摊时间复杂度。
那究竟如何使用摊还分析法来分析算法的均摊时间复杂度呢??
? 还是继续看在数组中插入数据的这个例子。每一次 O(n) 的插入操作,都会跟着 n-1 次 O(1) 的插入操作,所以把耗时多的那次操作均摊到接下来的 n-1 次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是 O(1)。这就是均摊分析的大致思路。
均摊时间复杂度和摊还分析应用场景比较特殊,所以我们并不会经常用到。
但是下面说一些它们的应用场景。
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。
? 均摊时间复杂度就是一种特殊的平均时间复杂度
没必要花太多精力去区分它们。你最应该掌握的是它的分析方法,摊还分析。至于分析出来的结果是叫平均还是叫均摊,这只是个说法,并不重要。
算法与数据结构:
算法与数据结构(一)- 概述














 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









